
...making Linux just a little more fun!
The Front Page
By Heather Stern
Ride the X11 Bus
This one's inspired by Tavis Ormandy of #fvwm on freenode, realising that one of
his nearby bus lines to Uni really is the X11 bus. He took a pic
to share - I asked him what he thought of my silly idea - the rest, as they
say, is history.
You can't really see who's the driver, but hey, most people don't care
what the Window Manager is anyway, as long as the keyboard works.

![[BIO]](misc/cover/xteddy-sitting-48.png)
|
Xteddy - a Gund "Tender Teddy" - was born in 1983, fell in love with
Stegu's monitor in the
90's sometime, and since 1998 or so has been faithfully using Unix, though
he has been seen on
a Windows system now and then and even with a
Macintosh once in a while. Lately he has been hanging out a lot in
#fvwm on freenode, baking cookies, memorizing people's screenshots so as
to be helpful, and indulging in a mocha now and then. The regulars there
call him a little hug daemon - a ready source of hugs for all processes.
Our Weekend Mechanic is one of his biggest fans.
Our regular readers may recall that Xteddy featured in our second cover
art picture over a year ago (back in issue
111). His good pal bear
has also stood in for him on occasion.
|
![[BIO]](misc/cover/gimp.png)
|
Wilbur has been the GIMP's
mascot since whenever it was that he won that logo contest. Best thing he
ever did. Now his work gets seen at speaking engagements in just about
every major Linux technical conference. He's been working on outreach
programs to benighted Windows users, as well.
|
![[BIO]](misc/cover/dragon.jpg)
|
Konqi has been with the K desktop crowd for some time now. He enjoys
fleshing out bug reports, and when he really gets into gear, polishing his
shiny white taskbar. He and his girlfriend plan to visit Kiagara Falls
sometime later this year, and enjoy the purple mists.
For the uninitiated, "Kiagara Falls" is one of the finer wallpapers in
the KDE collection. Consider taking a look at kde-look.org.
|
Talkback: Discuss this article with The Answer Gang
 Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather got started in computing before she quite got started learning
English. By 8 she was a happy programmer, by 15 the system administrator
for the home... Dad had finally broken down and gotten one of those personal
computers, only to find it needed regular care and feeding like any other
pet. Except it wasn't a Pet: it was one of those brands we find most
everywhere today...
Heather is a hardware agnostic, but has spent more hours as a tech in
Windows related tech support than most people have spent with their computers.
(Got the pin, got the Jacket, got about a zillion T-shirts.) When she
discovered Linux in 1993, it wasn't long before the home systems ran Linux
regardless of what was in use at work.
By 1995 she was training others in using Linux - and in charge of all the
"strange systems" at a (then) 90 million dollar company. Moving onwards, it's
safe to say, Linux has been an excellent companion and breadwinner... She
took over the HTML editing for "The Answer Guy" in issue 28.
Here's an autobiographical filksong she wrote called
The Programmer's Daughter.
Copyright © 2006, Heather Stern. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006
The Linux Gazette Mailbag
Apache Server Question
(marnie.mclaughlin at gmail.com) marnie.mclaughlin at gmail.com
Sat May 13 09:17:24 PDT 2006
Answered by: Ben
[ This one slipped through without an answer - anyone out there have a suggestion for Marnie? -- Kat ]
[Ben] - This is from a friend of mine; my memory of how to do this is rather
fuzzy, so I'm hoping that someone here will have a bit more recent Apache experience
than I do.
Hi Ben,
I have a Linux question for you if you don't mind:)
My boyfriend is a Linux Admin and wants to display a different directory
per user based on _SERVER{PHP_AUTH_USER}
For example:
http://server/home/
should point to http://server/home/user1/ or
should point to http://server/home/user2/
Both directories should appear to be the same (i.e. /home/) home could
be a PHP script or anything else that will work:)
What would you suggest or where can I look for help?
Fank you:)
Marnie
OSS external midi plays to AWE
sindi keesan (keesan at sdf.lonestar.org)
Fri May 12 18:33:24 PDT 2006
Answered by:
[ No one has had an answered for this one yet. Maybe there's
someone reading this issue of LG who does? -- Kat ]
I checked your knowledge base and found my own posting from 2005. The
MIDI howto is for ALSA and I am using 2.2.16 kernel and OSS.
Last year you helped me to play AWE files in linux, using my abbreviated
version of Slackware 7.1 (I had compiled playmidi and drvmidi but I needed sfxload
and a sound bank). I now know how to play FM synthesis and AWE midi in DOS and
linux, after setting the sound card in DOS with ctcm and loading soundbank with
sfxload. drvmidi or playmidi -a does AWE, playmidi -4 or -f does FM synthesis,
and playmidi -e is supposed to play to the external midi device but it DOES
NOT.
I also have the file I was missing that was needed to convert rpm to
tgz so I can use precompiled rpm packages (rpm2cpio as used by rpm2targz).
If I have inserted awe_wave.o, playmidi -e plays AWE not external,
and if I have not inserted it I get an error message about /dev/sequencer not
found and device or resource being busy.
cat /dev/sndstat does not do anything (some error message about the
device not existing). cat file.midi > /dev/sequencer says the device does
not exist or is busy or something.
I have made /dev/sequencer and /dev/midi00 with symlink to /dev/midi
and /dev/dsp and /dev/audio and /dev/music and /dev/sndstat.
In DOS I run ctcm to set the addresses and irqs, after which the pnp
AWE cards work properly in DOS, then I boot with loadlin into linux and the
settings are retained and I can play to external MIDI with several DOS programs,
or AWE or FM synthesis.
Soundblaster AWE64 card (ISA, pnp)
Using a 2.2.16 kernel which I compiled with support for sound:
insmod soundcore
insmod soundlow
insmod sound
insmod v_midi (Do I need this one? Is it causing problems?)
insmod uart401
(Sometimes also insmod mpu401, makes no difference)
insmod sb io=0x220 mpu_io=0x330 irq=5 dma=1 dma16=5
insmod awe_wave (for AWE sound only)
sfxload /usr/lib/sfbank/synthgm.sbk (the sound bank)
insmod opl3 io=0x388 (for FM synthesis only)
Or with a 2.4.31 kernel
insmod soundcore
insmod sb_lib
insmod sb.....
Do I need support for joystick or gameport as well? My kernel has modular
support for joystick but I don't have a joystick.
The only info I could find online was requests from other people who
had their external midi devices working in Win95 not in linux. With playmidi
-e or Rosegarden they either did not play, or played as FM synthesis on a card
without AWE. Mine plays as AWE, perhaps because I set that as the playmidi default.
External midi works in DOS with several programs such as playb.exe
(playpak) and beatmaster. We have an OEM midi cable and a Yamaha Clavinova with
the cable plugged in properly (OUT of cable to IN of piano and vice versa -
no sound came through when we plugged it backwards). The joystick port is not
disabled on the card in ctcm, and I tried a non-AWE card too with jumper set
to joystick enabled.
I also tried the basic (bare.i) kernels from Slackware 7.1 and 10.2
and I think 8.1 (one of them would not even play AWE sound). They all seem to
have full sound support, mostly as modules.
What little step might I have left out, or is there a bug in playmidi?
You helped me back in around 2002 to set up a 2MB ramdisk linux with
mdacon (to use both TTL and VGA monitors) and tried to teach me how to use screen
and suid. I still do not have modprobe, just insmod.
Proofing C
The Answer Gang (tag at linuxgazette.net)
Wed Apr 5 14:03:27 PDT 2006
Answered by: Ben, Jason, Neil
[ This was originally part of the Talkback:
122/sreejith.html discussion. -- Kat ]
[Jason] - [ Aside to the Answer Gang: I am by no means a C expert, but I know
a little bit about the language. ISTR some reader volunteering to proofread
C code that comes up in future articles, but if not, I could step in and try
to catch the obvious technical stuff.]
[[Ben]] - Well, Jan-Benedict Glaw volunteered - but I haven't actually seen
any result from it, despite prodding him a couple of times. I guess he's been
busy, or something. Your offer is gratefully accepted, since my C is too rusty
to be useful except in trivial cases.
[[[Neil]]] - Feel free to CC me for a second opinion on any C/C++ stuff.
[[[[Ben]]]] - That's great, Neil; accepted with thanks. Even with Jason's kind offer,
it would still be very nice to have more than one person available to do this.
Side note: anyone who contributes to the proofing process - technical, HTML
vetting, whatever - please add your name to that issue's STATUS file as described
there. We do not yet have a mechanism for using this, but at some point in
the near future, I'm hoping to have a bit of processing added that will display
those names on the index page of each issue. Either via my ham-handed efforts,
or someone else's Python skills (which would be greatly preferred; when I
take an axe to Python, it ain't pretty), but it will happen.
An idea
Benjamin A. Okopnik (ben at linuxgazette.net)
Wed Apr 19 18:23:07 PDT 2006
Answered by: Ben, Pablo, Thomas
[ cc'd to The Answer Gang for comments and further suggestions ]
On Wed, Apr 19, 2006 at 05:49:17PM -0700, Pablo Jadzinsky wrote:
> Dear editor,
>
> I am somewhat newbie to linux and I find your magazine the best
> resource I found so far. Even though I have great pleasure reading it
> and I find it extremely useful I have a suggestion.
> I think it would be great to have a 'homework' forum where every
> month a script or task can be suggested and then we (the readers)
> work on in during say 2 weeks. Some of us can send solutions to you
> and then someone on your team can post some of the different
> solutions with perhaps some comments on the different approaches. My
> experience says that the only way of really learning linux is through
> practice but at the beginning is difficult to use the system altogether.
>
> Any way, I hope you find my comment appropriate and useful.
>
> Thanks a lot
> Pablo Jadzinsky
Pablo, that's an excellent idea. I like it a lot; in fact, this is
one of the things I tried to do when I wrote the "Learning Perl" series
here a while ago. In fact, your idea gives me an idea:
How would you like to write this column?
Before you start objecting due to the fact that you're a "newbie"
[1], consider these two facts:
1) You don't have to come up with an answer to them yourself (although
I certainly hope that you'll try); posting them to The Answer Gang should get
a nice variety of answers which you could collate and use as part of next month's
article.
2) I suspect that most of us (it is certainly true for me) have by
now forgotten the specific kinds of problems that new users face, and would
have a tough time coming up with a list of them that would be relevant. You,
on the other hand, have the advantage of your position as a new user, and can
simply use any problems that you run into (after considering if they are of
general interest, of course.)
Besides... I don't like to mention it, because it's sort of like twisting
people's arms... but think of the *fame*. I mean, just imagine - "Pablo
Jadzinsky, Linux Gazette columnist." In *bold*, even. Women will swoon,
men will grit their teeth in envy, little green creatures from Beta Aurigae
will finally make contact with us because we've shown ourselves to be so highly
evolved... it's a winning scenario all around. Really. :)
[1] To quote Tom Christiansen, whose opinion, I fully share,
I find "Newbie" to be a grating, overly-cutsie buzzword
(read: obsequious neologism) used by people who are either
trying to be overly-cutsie or else who don't know that
"neophyte", "beginner" or "I'm new to" work just fine.
It sounds like something you'd be likely to find
in that offensively entitled line of books called
"XXX for Dummies".
[[Thomas]] - Been done before via various means --- some people (including myself)
tried setting various exercises in articles. But then this is only targetting
a specific audience: the people reading that specific article. (Ben's Perl series
at least had some reader feedback in this way).
[[[Ben]]] - Speaking of titles - "Thomas Adam, Linux Gazette cynic-in-residence."
Think of the fame, the... oh, right. :)
My articles were intended as lessons in basic Perl for those who wanted an
easy start. The exercises were purely incidental. I believe that a column
of the sort that Pablo suggested would garner an audience over time - it may
even get a good jump-start right away.
[[Thomas]] - Sometimes allusions were made in the earlier editions of TAG for
readers' to try out ideas if they were so inclined, and do post their results
in. Some did, but not many.
It's worth a try, for sure. I am greatly cynical though, so do not be surprised
if the response you get from it is low at best. You never know, you might
get a 'good' month in it.
[[[Ben]]] - Why not leave off the discouraging grumbling, and see what happens?
Thomas, there are no positive outcomes to be served by carping in this case,
and lots of negative ones. Why do it?
[[Thomas]] - I assume (since it's your suggestion) you'll be detailing to us
in more detail the sorts of things you were meaning, with an example? Yes? Excellent.
[[[Ben]]] - In fact, if Pablo does decide to undertake this, I would rather he
didn't detail them. Granting him the same courtesy that we do to any author
means leaving the details to him up until the moment that he submits the finished
article. There's no reason whatsoever to demand them until that point.
[[[[Thomas]]]] - I wasn't saying that. From what Pablo is saying, I get the impression
that he would like us at TAG to critique the answers?
[[[[[Ben]]]]] - Actually, that was my suggestion. I saw these two birds, and I only
had the one stone...
[[[[Thomas]]]] - If that's so, then that sounds like a good idea to me (is this
positive enough?) I'm just curious, that's all. Heck, it's an interesting discussion.
[[[[[Ben]]]]] - You bet. :) Encouraging participation is a plus in my book.
[[[[[[Pablo]]]]]] - I can't believe I got you two to write this much. If I tell my wife
that in top of doing my Ph.D, changing diapers and starting 2 companies I am
going to be involve in writing a column she will divorce me right away. I am
seriously tempted but let me see what I
can seriously manage and I'll get back to you.
By the way Ben, your intro to scripting in bash is excellent.
Speaking of taking over the world...
Benjamin A. Okopnik (ben at linuxgazette.net)
Tue May 2 06:41:53 PDT 2006
Answered by: Ben, Martin, Suramya, Thomas
"Gee, Brain - what are we going to do tonight?"
"The same thing we do every night, Pinky - try to take over the world."
So, my nefarious plan is this: let's all write a column (yep, I've
definitely caught the bug from the idea proposed by that querent, WhatsIsName,
recently.) What I'm talking about is creating a monthly thread in which we walk
through a common Linux task - anybody is welcome to toss in the seminal idea
and the first part of it (I'll take dibs on 'Installing a printer' this month
:), and the rest of us can pitch in comments: different ways to do it, solutions
to problems that could come up during the process, hardware/software quirks
to watch out for, etc. At the end of each month, I'll format the whole thing
into an article - I still need to figure out the layout, perhaps something highly
structured with lots of footnotes - and the credit will go to all the members
of TAG who participated.
What do you all think?
[Thomas] - I think it's a nice idea -- and something that's worth having a
go at. ;)
[[Ben]] - A pleasure to see you positive and first out of the gate, Thomas.
:) Very cool indeed.
[Martin] - That would be a interesting idea... Certainly would like to know
more about modern day printing...
All I have to do with the distro I use is select a printer and it sets it
up. I presume I'm using Cups although I'm not too sure...
[[Ben]] - Well, that is the way it often works - but that's not something from
which you can learn a whole lot. However, I'm more interested in the times when
it doesn't work that way; I've run into a lot of those over time, and have learned
quite a bit out of that. I'm definitely hoping that other people can contribute
something from their less-than-perfect experiences as well.
[[[Martin]]] - Luckily every distro I've tried has drivers for my printers but
I still would like to find out how it all works without...
[Suramya] - Sounds like a great idea.
Followup: [LG#127] mailbag #4
Ganesh Viswanathan (gv1 at cise.ufl.edu)
Thu May 25 19:02:29 PDT 2006
Answered by: Ben, Neil, Thomas
[ This is a followup to the question I
have a question about rm command. from LG#127. -- Kat ]
My reply for the:
"I have a question about rm command. Would you please tell me
how to remove all the files excepts certain files like anything ended with .c?"
question:
Hey,
The simple command (bash)
rm *[!.c]
would work for deleting all files except the right?
For all directories also, one can use:
rm -rf *[!.c]
Whatsay?
--Ganesh
[Thomas] - Assuming you had:
shopt -s extglob
set.
> For all directories also, one can use: rm -rf *[!.c]
I'd use find, since the glob will just create you unnecessary headaches if
the number of files are vast.
[[Ben]] - That would be my solution as well. In fact, since I'm a fan of "belt
and suspenders"-type solutions for shell questions of this sort ('rm' is
quite ungracious; it does exactly what you tell it to do - I'd have sworn
I've heard it chuckle at me...), I'd use 'find' and 'xargs' both.
[Neil] - [Quoting Ganesh]:
> The simple command (bash)
> rm *[!.c]
> would work for deleting all files except the right?
That doesn't look right to me. I would expect that to delete all files, except
those ending in '.' or 'c', so it would not delete example.pc or example.
> For all directories also, one can use:
> rm -rf *[!.c]
That will probably delete far more than you want. The glob expression is
evaluated by the shell in the current directory. The rm command does not see
the expression "*[!.c]", it sees whatever list the shell has created
from
that expression, so if you had a directory containing readme.txt, and
subdirectories src and module1, rm will get the command line "rm -rf
readme.txt module1" and will delete everything in module1, including files
ending in .c. The subdirectory src won't be matched, because, as I said
above, it doesn't match anything ending in 'c'.
Here's a little demo:
neil ~ 07:51:14 529 > mkdir /tmp/test
neil ~ 07:51:26 530 > cd !$
cd /tmp/test
neil test 07:51:31 531 > mkdir src
neil test 07:51:38 532 > mkdir module1
neil test 07:51:45 533 > echo -n > readme.txt
neil test 07:51:52 534 > echo -n > example.pc
neil test 07:51:58 535 > cp readme.txt example.pc src/
neil test 07:52:06 536 > cp readme.txt example.pc module1/
neil test 07:52:09 537 > ls -lR
.:
total 8
-rw-r--r-- 1 neil users 0 May 26 07:51 example.pc
drwxr-xr-x 2 neil users 4096 May 26 07:52 module1
-rw-r--r-- 1 neil users 0 May 26 07:51 readme.txt
drwxr-xr-x 2 neil users 4096 May 26 07:52 src
./module1:
total 0
-rw-r--r-- 1 neil users 0 May 26 07:52 example.pc
-rw-r--r-- 1 neil users 0 May 26 07:52 readme.txt
./src:
total 0
-rw-r--r-- 1 neil users 0 May 26 07:52 example.pc
-rw-r--r-- 1 neil users 0 May 26 07:52 readme.txt
neil test 07:52:16 538 > rm -rf *[!.c]
neil test 07:52:27 539 > ls -lR
.:
total 4
-rw-r--r-- 1 neil users 0 May 26 07:51 example.pc
drwxr-xr-x 2 neil users 4096 May 26 07:52 src
./src:
total 0
-rw-r--r-- 1 neil users 0 May 26 07:52 example.pc
-rw-r--r-- 1 neil users 0 May 26 07:52 readme.txt
neil test 07:52:30 540 >
Multiple append= Directives in /etc/lilo.conf
moped (moped at sonbeam.org)
Thu Apr 6 10:13:41 PDT 2006
Answered by: Ben
I found a web page with your subject comment, but I couldn't find where
you actually explained how to do it. Can you put a per-image append kernel option
in lilo.conf? Or does something like that have to be done all on one line, as
you suggest?
Could you please give me more info on how to do this?
Thanks!
[Ben] - Sure; here's a copy of the relevant part from my own "lilo.conf":
# Set the default image to boot
#
default=Linux-new
image=/boot/vmlinuz
vga=0x317
label=Linux-new
append="quiet acpi=on idebus=66 hdc=ide-scsi"
read-only
image=/boot/vmlinuz.old
vga=0x317
label=Linux-old
append="quiet acpi=on idebus=66"
read-only
image=/boot/vmlinuz-2.6.8-rc3-bk4
label=Linux-2.6.8
vga=0x317
append="resume=/dev/hda2 quiet acpi=on idebus=66 hdc=ide-scsi"
read-only
Each image entry gets its own 'append' option. This is also documented in
the LILO documentation; under Debian, the '/usr/share/doc/lilo/Manual.txt.gz'
file contains several examples as well as an explanation of the option.
Kmail mystery
Neil Youngman (ny at youngman.org.uk)
Fri Apr 28 01:00:48 PDT 2006
Answered by: Neil
[ Neil found his problem immediately, but I thought that the
TAG readership would like to see his nicely clueful help request, anyway. -- Kat ]
I noticed this morning that kmail was sending messages via postfix
on my machine, not via my ISP's mail server and as a consequence some emails
weren't being delivered because it's a dynamically allocated IP. this was unexpected
because
a. I thought kmail was set up to deliver via my ISP
b. postfix was set up for local delivery
First off I reconfigured postfix (dpkg-reconfigure postfix) to make
sure that it was configured for local deliveries only. This made no difference
that I could see.
I then checked my kmail configuration. Under the accounts/sending tab,
I saw that none of my sending accounts were marked as the default. That was
unexpected, but seemed like a reasonable explanation for the problem. I selected
the sending account for myisp and retested. It still sent via my local postfix
program.
I took a closer look and that account had no hostname set. I'm starting
to wonder how my kmail settings got into this state. I fix it and retest. It
still goes via my local postfix! I stop and restart kmail, check the settings
and retest. No change.
I am now completely at a loss. I search through all the visible kmail
settings and I can't see any other settings that should affect how my email
is sent.
My default sending account has the hostname for sending email set to
mail.myisp.com. I can telnet to the SMTP port at mail.myisp.com, but kmail insists
on sending mail to localhost. Why? at am I missing?
[Neil] - I am mistaken. The last 2 emails did go via my ISP, so somewhere along
the line kmail picked up the change and I misread the logs.
How to recursively search HTML?
(m at de-minimis.co.uk) m at de-minimis.co.uk
Wed May 17 20:13:40 PDT 2006
Answered by: Ben, Francis, Thomas
Dear LinuxGazette,
Can you recommend a tool for recursively searching for a a given word
starting at a given HTML page?
Google's great when on the web, but when I
have HTML on my local machine Google can't get to it.
It should be reasonably easy to script something together using wget,
awk
(to get rid of anything that's not meant to be seen), and grep, however
if there are already nice solutions out there one might as well use those.
Best Wishes, Max
[Thomas] - Do you just mean the content? Open it up in a browser. If it's
the actual HTML, use an editor.
[Francis] - If you want to have content served by your web server searchable
on an
ongoing basis, then the best answer is probably to run a local search
engine, such as htdig or swish-e (or, presumably, many others).
If you want content on my web server to be searchable, I'd prefer if you
didn't fetch everything without asking me first.
"web server" there is for three things: get at the content initially
for indexing; provide an interface to the search utility for searching; and
allow the search utility present a link to the original content for retrieving.
None of the three requires a web server, but for search engines which expect
to be used on a web site you may need to make non-default configurations if
you want your primary interface to be file: urls instead of http: ones.
> It should be reasonably easy to script something together using wget, awk
> (to get rid of anything that's not meant to be seen), and grep, however
> if there are already nice solutions out there one might as well use those.
If it is to be a one-off or rare search, then "find | xargs grep"
on the filesystem should work. The equivalent through the http interface would
also work. ("find" becomes "print a list of urls"; that
then would go through a url-retriever like wget or curl to spit the content
to stdout for grep; if grep matched, you'd want to print the matching url
for later consideration.)
In either case, you'll effectively be searching all of the content every
time.
You can get your search engine to search all of the content once, and then
tell you where to look for specific terms. The larger the volume of content,
the sooner it will have been worth indexing it initially.
[Ben] - I suppose it depends on what you mean by "recursively" -
for many webpages, enough recursion depth means searching the entire web.
I don't know of anything like that already made up, but as you say, it should
be easy enough to script. My first cut would be something like 'wget' piped
into 'lynx -dump -nolist' plus 'grep' to filter the output - but YMMV.
Cannot read Kingston USB pen drive with DOS and Mac partitions
Sindi Keesan (keesan at grex.cyberspace.org)
Sun May 14 10:15:13 PDT 2006
Answered by: Thomas
Someone asked for our help repartioning/reformatting (to FAT16) a Kingston
DataTraveler Elite 256MB USB 2.0 pen drive which currently contains one
DOS partition of about 200MB that can be accessed via a Mac (which was
used to delete the files in it), and a 50MB or so Mac partition that
cannot be reformatted by the Mac. (Something is greyed out).
The drive was apparently given out by a TCF bank at a conference and
one
of the partitions is labelled TCF_2005.
usb-storage.o identifies it as Model: TCF_2005 and Type: CD-ROM
I was told that DOS USB drivers also found it as CD-ROM, and Windows
XP
or 2000 found DOS and Mac partitions. Our DOS drivers did not find it at
all on our older computers. We have only USB 1.0 ports.
I attempted to use the Slackware 10.2 bare.i kernel with hfs.o (Mac
file
system) module, which has no dependencies listed in modules.dep.
I use Slackware-4.0- and uClibc-based Basiclinux 3.40 and
Slackware-7.1-based Basiclinux 2.1 with glibc upgraded to 2.2.5.
When I insmod hfs.o:
Unresolved symbol: generic_file_llseek
generic_commit_write
unlock_new_inode
generic_read_dir
block_read_full_page
__out_of_line_bug
block_sync_page
cont_prepare_write
event
mark_buffer_dirty
block_write_full_page
iget4_locked
generic_block_bmap
(copied via pencil and paper - how do I save such messages to a file?).
hfsplus.o gave twice as many lines of messages.
I found only four references to the first three lines in google/linux
and
they were for later kernels.
The drive comes with Windows or OSX security software which I suspect
is
causing the problem.
I cannot use fdisk without first finding the drive as a device.
Is it possible to repartition this drive with any linux?
Sindi Keesan
[Thomas] - Why insmod? That's not really the best way to go. You almost
certainly want to use modprobe so that any dependant modules needed
by the one you're trying to load, do so.
> (copied via pencil and paper - how do I save such messages to a file?).
They'll appear in /var/log/messages.
> hfsplus.o gave twice as many lines of messages.
I presume with the same content as the above?
> I found only four references to the first three lines in google/linux
> and they were for later kernels.
>
> The drive comes with Windows or OSX security software which I suspect
> is causing the problem.
>
> I cannot use fdisk without first finding the drive as a device.
Such things will appear as mass storage devices. Usually via
hotplug, they'll be assigned one of the /dev/sda* mappings. In
fact, hotplug is something that is both useful and a PITA. For
kicks, try resetting it, removing your pen drive first, and then
reinserting it:
sudo /etc/init.d/hotplug restart
(if you don't know what sudo is, or don't have it setup, you'll have
to su to root to do the above.)
You should look at the output from 'dmesg' to see what else it says
about your device. Something you haven't even bothered to tell us
(but that's OK -- everything is about guessing around here) is the
kernel version you're using. Guess what mass storage devices use?
Go on -- you might even get a gold star out of it. No? Ok, it's
SCSI. In the 2.4.X kernels, you'll need some sort of emulation
layer to do this -- scsi_mod probably.
If you're in 2.6.X, you don't have to worry about that.
> Is it possible to repartition this drive with any linux?
It is -- but this is 200MB we're talking about here...
PHP and Apache
clarjon1 (clarjon1 at gmail.com)
Fri May 12 12:29:22 PDT 2006
Answered by: Ben, Thomas
Hey gang, hope you can help
I am running Slackware 10.2 with the default apache and php stuff that
came with the installation. I am having a few troubles with PHP. I have done
what I have read I am supposed to do, the modules are loaded, but when I goto
view a PHP doc via the server, I get either a blank page or a Download To box
(depending on the browser, and what page it is) Any suggestions? I would really
appreciate.
Thanks!
(PS, I can't wait to finish writing my first article to submit to LG!
:) )
[Thomas] - [Quoting clarjon1]
> I have done what I have read I am supposed to do, the modules are
Really? And just what have you read?
You can't have done everything correctly. This symptom is usually the result
of Apache not knowing how to deal with that file type. I am going to make
an assumption here in that you really have got the PHP modules loaded. Of
course, since you don't tell us which version of Apache you're using, it makes
things slightly harder. I don't use Apache2 (way overhyped), so for Apache
1.3.X, you have to ensure in your /etc/apache/httpd.conf file, you have something
like:
AddType application/x-httpd-php .php
AddType application/x-httpd-php-source .phps
[[Clarjon1]] - Sorry for not specifying what all the versions are, I was at
school at the time, and was pretty rushed for time.
[[[Thomas]]] - It happens.
[[Clarjon1]] - I have Apache 1.3.33, and I have those modules loaded in both
mod_php and httpd.conf, so I actually get errors about the modules already loaded,
[[[Thomas]]] - This is normal, and quite harmless. Which version of PHP are you
using?
[[Clarjon1]] - The AddType lines, I have those added into the httpd.conf file,
and the application/x-httpd-php stuff in the mimetypes file as well (without
the AddType there, of course)
[[[Thomas]]] - Right.
[[Clarjon1]] - The module is there, I think that it could be that I messed something
up somewhere in installation, and it's biting me now. I'm gonna try downloading
fresh copies of apache and php later today, and compile from the source when
I get home.
[[[Thomas]]] - Possibly overkill. It's probably not the applications per se that
are causing your issue, but one of misconfiguration. I would not have said that
recompiling anything is going to help, but YMMV.
[[Clarjon1]] - One last question, what sort of errors should I look at in the
error/access logs for hints as to what is going wrong? Thanks for taking the
time to help, guys. I really appreciate this.
[[[Thomas]]] - There probably won't be any errors, since Apache is doing exactly
what you asked it to do (i.e. with a misconfiguration, or no configuration,
it will attempt to either display the php file, or give you the option of downloading
it). I actually have a multitail window open (via sshfs) that tails both /var/log/apache/{access,errors}.log:
multitail -I /mnt/var/log/apache/errors.log -I \
/var/log/apache/access.log
It's quite useful for things like this. :P
[[[[Clarjon1]]]] - Thanks for all your help, but I was able to fix the problem.
Turns out I had all the configuration files set up correctly, I was
missing some files. I don't know why nothing complained, but oh well.
I went through the packages from my other distros I have kicking
around, and I found this package:
libphp_common432
This package provides the common files to run with different implementations
of PHP. You need this package if you install the php standalone package or
a webserver with php support (ie: mod_php).
I installed it, and viola! I now have PHP working. I got a little forum set
up (after finding mySQL was broken and then had to install postgres, then
figuring out how to use postgres and the database and users which can be used
via web). I'm glad that's over with.
So all is good for now, with this problem Thanks again for your help!
[Ben] - As Thomas said, it sounds like you don't have the PHP filetypes defined
in your 'httpd.conf' - or perhaps the relevant module is missing or not enabled.
On Debian, this happens automatically as part of the PHP package installation
procedure; presumably, Slackware doesn't do that, so you'll have to do it manually.
In my /etc/apache2/apache2.conf, the relevant entries look like this:
DirectoryIndex index.html index.cgi index.pl index.xhtml index.php
Include /etc/apache2/mods-enabled/*.load
I'd also ensure that there was a 'php5.conf' and a 'php5.load' in my /etc/apache2/mods-enabled/
directory. For plain Apache (i.e., not
Apache2), the above would be more of a direct reference from 'httpd.conf'
and would look something like
AddType application/x-httpd-php .php
AddType application/x-httpd-php-source .phps
LoadModule php5_module /usr/lib/apache/1.3/libphp5.so
(This would, of course, require that the module named above existed at that
location.)
Something I've also found helpful in my PHP travails of the past (this wouldn't
help in your case, since the problem you're having comes before this level
of troubleshooting) is having a file called 'info.php' living somewhere in
my web hierarchy and consisting of the following:
<?php
phpinfo();
?>
Once PHP is up and running, looking at this file will give you lots and lots
of info about your PHP installation and its capabilities.
Printer setup
Neil Youngman (ny at youngman.org.uk)
Sat Apr 1 00:01:28 PST 2006
Answered by: Ben, Martin, Neil
I upgraded to the latest SimplyMepis a while back and since then I've
been unable to get it to configure my printer. IIRC, when I originally set up
Mepis I just installed some extra packages to give it the right drivers and
configured it in the CUPS web interface at localhost:631.
The printer is a Xerox XK35C, for which the lex5700 driver is recommended.
Searching the debian packages for xk35c, I find foomatic-db and foomatic-filters-ppds
seem to have relevant files. Having made sure both are installed, I still don't
get the Xerox Workcentre XK35C or the Lexmark 5700 on the list of available
printers.
The HOWTOs don't offer anything more than install the correct driver
package and configure printer. Does anyone know what I'm missing here?
[Martin] - Have you re-started CUPS?
/etc/init.d/cups restart
Sometimes you have to re-start Cups for it to see any new drivers then just
select the printer in the web interface...
[[Neil]] - This machine is not usually left on overnight, so it's been rebooted
quite a few times since the drivers were installed.
[Ben] - Check to make sure that your system (via hotplug) still detects your
printer. Examine the output of 'dmesg' for something like this:
usb 2-1: ep0 maxpacket = 8
usb 2-1: default language 0x0409
usb 2-1: new device strings: Mfr=1, Product=2, SerialNumber=3
usb 2-1: Product: psc 1310 series
usb 2-1: Manufacturer: hp
usb 2-1: SerialNumber: CN522C5230V4
usb 2-1: uevent
usb 2-1: device is self-powered
usb 2-1: configuration #1 chosen from 1 choice
usb 2-1: adding 2-1:1.0 (config #1, interface 0)
usb 2-1:1.0: uevent
usb 2-1: adding 2-1:1.1 (config #1, interface 1)
usb 2-1:1.1: uevent
usb 2-1: adding 2-1:1.2 (config #1, interface 2)
usb 2-1:1.2: uevent
drivers/usb/core/inode.c: creating file '002'
hub 2-0:1.0: state 7 ports 2 chg 0000 evt 0002
uhci_hcd 0000:00:1d.0: suspend_rh (auto-stop)
hub 3-0:1.0: state 7 ports 2 chg 0000 evt 0000
drivers/usb/core/inode.c: creating file '001'
usblp 2-1:1.1: usb_probe_interface
usblp 2-1:1.1: usb_probe_interface - got id
drivers/usb/core/file.c: looking for a minor, starting at 0
drivers/usb/class/usblp.c: usblp0: USB Bidirectional printer dev 2 if 1 alt 0 proto 2 vid 0x03F0 pid 0x3F11
usbcore: registered new driver usblp
drivers/usb/class/usblp.c: v0.13: USB Printer Device Class driver
Also (assuming that it's a USB printer and you have 'usbfs' configured and
mounted), take a look at '/proc/bus/usb/devices'; my printer entry there looks
like this:
T: Bus=02 Lev=01 Prnt=01 Port=00 Cnt=01 Dev#= 3 Spd=12 MxCh= 0
D: Ver= 2.00 Cls=00(>ifc ) Sub=00 Prot=00 MxPS= 8 #Cfgs= 1
P: Vendor=03f0 ProdID=3f11 Rev= 1.00
S: Manufacturer=hp
S: Product=psc 1310 series
S: SerialNumber=CN522C5230V4
C:* #Ifs= 3 Cfg#= 1 Atr=c0 MxPwr= 2mA
I: If#= 0 Alt= 0 #EPs= 3 Cls=ff(vend.) Sub=cc Prot=00 Driver=(none)
E: Ad=01(O) Atr=02(Bulk) MxPS= 64 Ivl=0ms
E: Ad=81(I) Atr=02(Bulk) MxPS= 32 Ivl=0ms
E: Ad=82(I) Atr=03(Int.) MxPS= 8 Ivl=10ms
I: If#= 1 Alt= 0 #EPs= 3 Cls=07(print) Sub=01 Prot=02 Driver=usblp
E: Ad=03(O) Atr=02(Bulk) MxPS= 32 Ivl=0ms
E: Ad=83(I) Atr=02(Bulk) MxPS= 32 Ivl=0ms
E: Ad=84(I) Atr=03(Int.) MxPS= 8 Ivl=10ms
I: If#= 2 Alt= 0 #EPs= 3 Cls=ff(vend.) Sub=ff Prot=ff Driver=(none)
E: Ad=07(O) Atr=02(Bulk) MxPS= 32 Ivl=0ms
E: Ad=87(I) Atr=02(Bulk) MxPS= 32 Ivl=0ms
E: Ad=88(I) Atr=03(Int.) MxPS= 8 Ivl=10ms
I: If#= 2 Alt= 1 #EPs= 3 Cls=ff(vend.) Sub=d4 Prot=00 Driver=(none)
E: Ad=07(O) Atr=02(Bulk) MxPS= 32 Ivl=0ms
E: Ad=87(I) Atr=02(Bulk) MxPS= 32 Ivl=0ms
E: Ad=88(I) Atr=03(Int.) MxPS= 8 Ivl=10ms
If all the hardware stuff is OK, try printing directly to the device:
cat /etc/group > /dev/usb/lp0
If that works, then the problem is (obviously) CUPS. I've wrestled with that
thing myself, in the past, and here's what worked for me:
Check /etc/cups/ppd to make sure that you have the correct PPD file. If you
do, and 'cups' still fails to detect your printer, go to http://linuxprinting.org
and grab a fresh copy of that PPD file - I've had the distro install a stale
version that couldn't handle my (brand new) printer twice now, with two different
printers.
[[Neil]] - No it's not USB
[Ben] - There's also a 'HOWTO'-type page at the above URL that walks you through
the intricacies of dealing with CUPS and FooMatic stuff that you might find
helpful.
[[Neil]] - I've looked at that before, but this time I found enough inspiration
to solve it. The PPD file hadn't been installed where CUPS could see it.
[[[Ben]]] - Now that you remind me - yeah, shortly after I installed CUPS a
couple of years ago, I had the same problem. The PPD I needed was located somewhere
deep inside '/usr/share' or /usr/lib', but CUPS just ignored it. I think it
was that FAQ at linuxprinting.org that finally put me onto the fact that it
should be in '/etc/cups/ppd' instead.
[[Neil]] - I located the PPD file with
find / -xdev -iname \*xk35\*
and then I copied it to /usr/share/cups/model/
root at 2[~]#
gunzip /usr/share/ppd/linuxprinting.org-gs-builtin/Xerox/Xerox-WorkCentre_XK35c-lex5700.ppd.gz
root at 2[~]#
cp /usr/share/ppd/linuxprinting.org-gs-builtin/Xerox/Xerox-WorkCentre_XK35c-lex5700.ppd /usr/share/cups/model/
root at 2[~]# /etc/init.d/cupsys restart
Restarting Common Unix Printing System: cupsd.
root at 2[~]#
After that I was able to configure it from the web interface.
Easy once I looked in the right place. Thanks for getting me on the right
track.
[[[Ben]]] - Glad I could help, Neil!
Reading Oxygen Phone Manager files
Jimmy O'Regan (jimregan at o2.ie)
Thu May 25 08:17:43 PDT 2006
Answered by: Ben, Francis, Jimmy
Every now and then I use a Windows program called "Oxygen Phone
Manager" to back up my phone. It's able to read information that none of
the Linux programs can, so it solves the problem of how to back up everything
on the phone, but uses some strange file formats of its own, which is another
problem...
This script converts data from
the call registry to the XML format that OPM outputs (.cll files, or [mnt point]/Program
Files/Oxygen/OPM2/Data/Phones/[phone IMEI]/CallRegister.dat).
This is probably the least useful information that OPM extracts, but
I needed to use it to understand the date format OPM uses, and someone somewhere
might find it useful.
[Jimmy] - It turns out that at least one other program uses the same date
format, so the date stuff is probably more useful than I'd thought.
Anyway, here's a Python version of the date
stuff (I use python as a hex editor :)
[Francis] - Hi there,
I think there are some imperfections in the homebrew date code (which is
why there are modules for that sort of thing, of course).
As a verification, 36524 days after 1 Jan 1900 should be 1 Jan 2000 (100
years x 365 days per year plus 24 leap days between those dates).
My date(1) doesn't go back as far as 1 Jan 1900, but 1000 days later is 28
Sep 1902, so I can use that as an independent verification.
$ date -d "28 Sep 1902 + 35524 days" +%d/%m/%Y
01/01/2000
print days_since_1900(36524);
-2/01/2000
So: homebrew perl is a few days out, and it prints negative numbers.
> sub split_date
> {
[snip]
> # Number of days since 1900
> if (eval "require Date::Manip")
> {
> import Date::Manip qw(DateCalc Date_Init);
>
> # OPM doesn't seem to use proper leap years
> $numdays -= 2;
[snip]
> }
[snip]
> else
> {
> # My crappy function, as a last resort
> days_since_1900 ($numdays);
> }
[snip]
> }
>
> if ($buggy_as_hell)
> {
> # 38860.8914930556 should be 23/05/2006 21:23:45
> split_date(38860.8914930556);
That'll give 23/05/2006 because you subtract 2 within split_date when using
Date::Manip, as shown above.
38860 days after 1 Jan 1900 is actually the 25th. It's only worth mentioning
because you don't explicitly subtract 2 within days_since_1900.
> sub days_since_1900
> {
> my $numdays = shift;
> my @mdays = qw(31 28 31 30 31 30 31 31 30 31 30 31);
>
> my $years = int($numdays / 365);
Minor point -- after 366 leap years have passed, that'll be off.
Unlikely to be a major problem.
> if ($buggy_as_hell) {print "$years years\n";}
>
> $numdays -= ($years * 365);
That's $numdays %= 365, "the number of days gone this year plus the
number of leap days since epoch".
> if (($years % 4) == 0)
> {
> $mdays[1] = 29;
> }
Other minor point -- that's strictly wrong; but for the range of "90
years either side of today" it works, so it's also unlikely to be
a major problem.
> if ($buggy_as_hell) {print "February has $mdays[1] days\n";}
>
> my $leapyears = int ($years / 4);
> if ($buggy_as_hell) {print "$leapyears leapyears\n";}
> $leapyears++; # Um... 'cos this doesn't count 1900 as OPM does
Don't know exactly what OPM does, but $leapyears is now "the number
of leap days since epoch, plus one, plus one more if this is a leap year but
it's not yet Feb 29th" which is probably not a very useful count.
> $numdays -= $leapyears;
The big problem is here. $numdays can now be negative, which will lead to
odd dates come December -- try 39050 and 39060 and spot the awkwardness.
So: if $numdays is less than 1, decrease $years by 1, increase $numdays by
365 (or 366 if the new $years corresponds to a leap year), and then think
about how to handle the "if this is a leap year but it's not yet Feb
29th" thing.
Oh, and maybe subtract the 2 that happens in the Date::Manip case.
It's too much to wrap my head around right now, so I'll just suggest the
cheaty
$numdays -= 1000;
$date=qx{date -d "28 Sep 1902 + $numdays days" +%d/%m/%Y};
as a shell-out workaround.
And the magic OPM "2"? Maybe it counts 1 Jan 1900 as day 1 not
day 0, and maybe it thinks 1900 was a leap year? That could bump the current
numbers up by 2 compared to what is expected, perhaps.
The same algorithmic error is in the python implementation.
[Ben] - I didn't have the time to dig into it, but two errors jumped out at
me:
import Date::Manip qw(DateCalc Date_Init);
Ummm... don't do that. Just don't. The reasons are long and complex (see
'perldoc -f import', if you feel like unraveling a tangled string), but that
should be 'use Date::Manip qw(DateCalc Date_Init);' instead.
You've also got 'xml_line' being invoked as
while (<>)
{
s/\r\n//;
my ($type, $order, $number, $foo, $name, @times) = split (/\t/, $_);
xml_line ($type, $number, $name, @times);
}
but declared as
my ($type, $number, $name, $stimes) = @_;
my @times = split / /,$stimes;
Given your sample data, you're putting a single time string into '@times',
then reading it as a scalar. The easiest fix (well, 'problem prevention' rather
than 'fix' - it'll work as it is unless a "\t" gets into the time
data) would be to invoke and process it as a scalar:
my ($type, $order, $number, $foo, $name, $times) = split (/\t/, $_);
xml_line ($type, $number, $name, $times);
or, perhaps, by completely eliding those temp vars since they're only used
once anyway - which would eliminate the problem as a side effect:
while (<>)
{
s/\r\n//;
xml_line ( ( split /\t/)[0,2,4,5] );
}
Network Traffic Review/Filtering
sloopy (sloopy_m at comcast.net)
Thu Apr 6 04:27:56 PDT 2006
Answered by: Francis, Kapil, Suramya
Greets and Salutations,
I have lurked about on the ML for quite a while and wanted to thank
all that make this source of info (and at times humor) for their time and knowledge.
The question(s)
I run a 8-10 node network at home through a router (a VIA C3 mobo with
fedora core) and would like to have a way of setting up a web page on it that
would list URL's being retrieved from the inet, and a nice side option of being
able to block certain content for some nodes on the network. would i need to
run a proxy (i.e. squid or similar) for this? or would this be over the capabilities
of the router machine?
thanks,
sloopy.
[Francis] - Hi there,
I have lurked about on the ML for quite a while
Great -- I'll not explicitly Cc: you since you're on the list already.
Short answer: you do not need to run a proxy, but you should do so. And it
should not exceed the capabilities, unless you've other funny stuff going
on.
Longer answer follows...
Usually, the hard part about designing a solution is precisely specifying
the intention ;-)
that would list URL's being retrieved from the inet
will need to have access to those URLs.
I'm guessing that you primarily care about http, with perhaps an interest
in https or ftp too.
Expect that you won't see details of https requests. It's easier that way.
One way to get access to those URLs would be to run a network sniffer on
the router and configure it to record HTTP requests.
Completely passive, no change to what the users see or do, and you can prevent
the system becoming swamped by allowing it to drop packets if it thinks it
is too busy, at the cost of not having a complete record of the accesses.
Google will be able to suggest software which can do this, if you don't have
any favourites. One variant I've come across (but can't think of right now)
involves sniffing and displaying any images in http traffic that are on the
network. That may or may not be appropriate for your setup, of course.
[[Suramya]] - The software you are thinking about is called Driftnet
.
Be really really careful while running this. We tried this as a test at my
last job and were showing off the program to a group of co-workers and I guess
someone in the building was surfing porn at that time so we got to display
some really explicit content on a really big display.
Consider yourself warned if you want to use this... :)
[Francis] - Another way to get the URL list would be to require the use of a http proxy
server, and read the log file it generates. One way to require the use of
a proxy server is to allow (web) access from it and block access from elsewhere.
Another way is to try network magic on the router and use a transparent proxy.
(With the obvious caveat that a transparent proxy can't work in all cases;
that may not be an issue for you.)
Small or no changes to what the users see and do. Active, in that if the
extra service fails, web access is stopped. And it does allow for the possibility
of caching and access control, if you go that way.
In either case, for a web page, "tail the-url-list-file" as an
appropriate user might be sufficient, or just show the raw log file, or use
any of the log analysers to generate pretty pictures. Again, Google will likely
show you a ready-made solution for whichever you pick.
being able to block certain content for some nodes on the network.
When you have defined (for yourself) "certain content" and "some
nodes", you'll probably find that it's easier to do this at the http
level, with a proxy server. It can be done at the tcp level with a more active
network sniffer, but the simple answer is "don't do that".
On my machine (PII 366MHz, 128MB) I use squid as a caching proxy server,
with squidGuard as a redirector intended primarily to block some images and
undesired content. Single client node, and (deliberately) easily bypassed.
(I also have a thttpd to serve the redirected content, for completeness.)
In my setup, the control is handled mostly by squidGuard, which can decide
based on source address or url, but not based on content. That's good enough
for me. (There's a Fine Manual with all of the details.)
Occasionally I want to make local modifications to the block-or-allow lists,
which I do from a shell. A webmin module for it exists if you like that kind
of thing, but I've not examined it in a long time.
"My users" is "me", and they all know how to fix or work
around broken bits without bothering their admin. This happy state may not
match your network.
Extra memory is always good. And disk space if you choose to cache or retain
logs. But if the machine can run Fedora Core, it can run squid/squidGuard
for a small network.
Set up squid and squidGuard and whatever other bits you want, and use it
as your proxy server. Configure squid to allow what you want to allow, and
block the rest. Configure squidGuard to allow or block as appropriate. And
make sure that "what you want to allow" won't surprise the other
users.
Admire your URL list web page, and change it to match what you want.
Decide how important to you it is to block access and have a full log of
http requests.
Then either invite others to use the proxy, require others explicitly to
use it, or require others transparently to use it (the latter two include
adjusting your ip filtering rules).
And when it's all working, if you've something to add over what's in the
lg archives, write it up as an article and submit.
Good luck with it!
[[[Kapil]]] - As Suramya pointed out anecdotally, in any (re-)configuration of
routers/firewalls make sure you understand and can handle the "politics".
As Francis Daly said you have three solutions. I'll add a glimpse to the
politics associated with each.
a. Force all nodes to use a web proxy by blocking other nodes from accessing
the web directly (using firewall rules). Any web proxy combined with a log
analyzer (analog?) can do what you want.
Provide a ".pac" file (for automatic proxy configuration) for
user convenience.
This way everyone using the nodes knows what you are doing and how.
b. Automatically redirect web connections from the nodes to the web proxy
by firewall rules. You need a web proxy (like squid) that can handle "transparent
proxying".
The users need not be told anything but they'll probably find out!
"Transparent" proxying is generally not quite transparent and
in my experience does break a few (very few) sites. Note that web proxies
are acounted for by the RFC for HTTP but transparent proxies are not.
c. Use firewall rules to send a copy of all web traffic through a sniffer
which can extract the URL's. You can insert firewall rules to block/allow
specific IP addresses.
Again the users need not be told anything.
You will not be breaking any network protocols by doing this.
Hope this helps,
Meaning of overruns & frame in ifconfig output
Ramon van Alteren (ramon at vanalteren.nl)
Thu Apr 6 13:41:50 PDT 2006
Answered by: Ben, Francis, Martin, Ramon
Hi All,
Out of pure interest would anyone know the exact definition (or provide
me with pointers to said definition) of the fields overrun and frame in the
output of ifconfig.
I've been searching google for an answer, but that mostly turns up
false positives from all the people over the years that have posted their ifconfig
output on the internet.
I've checked wikipedia which has an external link to the following
short bit on overruns but nothing on the frame field: "Receiver overruns
usually occur when packets come in faster than the kernel can service the last
interrupt. "
I'm seeing these (overrun & frame errors) on a NIC in a load-balancer
which services just the incoming http-requests (outgoing uses direct routing)
and I'm buying new ones tomorrow. I am however still curious what these values
actually mean.
Thanx,
Ramon
[Francis] - The source code might :-)
[[Ramon]] - Kept that as a last resort, my C coding & reading skills is
at best rusty and at worst non-existant.
[Francis] - But there's a 450 kB 45-page pdf at both
http://www.utica.edu/academic/institutes/ecii/publications/articles/A0472DF7-ADC9-7FDE-C80B5E5B306A85C4.pdf
and http://www.computer-tutorials.org/ebooks/02_summer_art1.pdf
with the heading
International Journal of Digital Evidence
Summer 2002, Volume 1, Issue 2
"Error, Uncertainty, and Loss in Digital Evidence"
Eoghan Casey, MA
which includes on p29
One manufacturer provides the following information about interface errors,
including datagrams lost due to receiver overruns a.k.a. FIFO overruns (NX Networks,
1997).
* packet too long or failed, frame too long: "The interface received
a packet that is larger than the maximum size of 1518 bytes for an
Ethernet frame."
* CRC error or failed, FCS (Frame Check Sequence) error: "The
interface received a packet with a CRC error."
* Framing error or failed, alignment error: "The interface received
a packet whose length in bits is not a multiple of eight."
* FIFO Overrun: "The Ethernet chipset is unable to store bytes in
the local packet buffer as fast as they come off the wire."
* Collision in packet: "Increments when a packet collides as the
interface attempts to receive a packet, but the local packet buffer
is full. This error indicates that the network has more traffic than
the interface can handle."
* Buffer full warnings: "Increments each time the local packet
buffer is full."
* Packet misses: "The interface attempted to receive a packet,
but the local packet buffer is full. This error indicates that the
network has more traffic than the interface can handle."
[[Ramon]] - Mmm interesting link, more reading material for the stack ;-) Thanks
[Francis] - This is friend-of-a-friend third hand stuff by now, of course,
but it certainly sounds reasonable to me, and might give you pointers to some
more terms to search for to find something demonstrably authoritative.
For what it's worth,
/proc/net/dev packet framing error overrun
was what I was what I (eventually) asked Google for, before asking for
"NX Networks" ifconfig
which found the two links.
I hope the above isn't useless.
[[Ramon]] - Certainly not, at the very least it will serve to enlight my soul
with knowledge, which is a good thing (tm)
FYI: It took me awhile to pinpoint this bottle-neck, most answers google
turned up pointed to badly configured or malfunctioning hardware and or pci-busmaster
stuff.
This is a well-configured Intel 100Mbit NIC with busmastering enabled which
is apparently flooded with http-traffic to the point that it can not generate
interrupts fast enough to get the frames out of it's buffer. That's the first
time I've ever seen that.
[[[Martin]]] - DOS attack was the first thing that came to mind...
[[[Ben]]] - I've seen NICs from nominally reputable vendors start throwing a large
number of errors under a much lower load than what you've described - I tested
several identical units and gave up in disgust. The Intel cards that I used
to replace them worked great, never a complaint. The one you described is just
an amazing sample of the breed; it should be given a retirement dinner, a gold
watch, and a full pension.
[[[[Ramon]]]] - It's an Intel NIC
;-)
[[[[Martin]]]] - So what would cause a network card to throw that many errors then?
I'm guessing that its either dodgy drivers or a actual dodgy manufacture...
[[[[[Ben]]]]] - The latter. This happened ~7 years ago, but since I had to send the
cards to the States to get them replaced (I was in the USVIs at the time), and
everything took place in S-L-O-W T-I-M-E, many of the details are still with
me. It all took place under a certain legacy OS, but the drivers that the vendor
specified (ne2000) were the bone-standard, came-with-the-OS types. By the time
the third card arrived - I had a hard time believing that I got two bad cards,
but seeing trainwrecks happening at 2MB/s was a pretty strong motivator to find
out - I had installed Debian (dual-boot) on my machine, and could show the NIC
falling over and twitching piteously under two different OSes. Then, I marched
into the CEOs office with a couple of printouts and demanded a case of Intel
NICs. I had no experience with them personally, but I had a number of trustworthy
admin friends who swore by these things while swearing off everything else.
Oh yeah - I should mention that the CEO of that company was convinced that
the IS department should be able to run on, oh, fifty cents a month - and
asking for anything more was an outrage and a shuck that he was way too smart
to fall for. This led to some interesting confrontations on a regular basis
- I suppose he liked high drama. Anyway, I don't recall if I had to resort
to bodily harm and talking about his mama, but I got those cards and spent
the week after that installing them on every machine in the company (except
the CEOs, he-heh. He had a brand-new Dell for his Minesweeper and Solitaire,
and had previously told me that he didn't want me to touch it.)
After The Great Replacement, many of my network troubles disappeared - and
as a bonus, so did lots of database problems. Seems that many of the latter
were caused by apps establishing a lock for the duration of the transaction
+ the network flaking out during that transaction. This would cause the lock
to persist until that machine was rebooted (!), and nobody else could get
access to that DB until it was... this was a Novell 4.01 goodie that fortunately
went away when I updated everything to 4.11, months later.
[[[Francis]]] - (quoting Ramon): Kept that as a last resort, my C coding
& reading skills is at best rusty and at worst non-existant.
As backup for the "random file on the web" info, /usr/include/linux/netdevice.h
on my 2.4-series machine includes in the definition of "struct net_device_stats",
in the "detailed rx_errors:" section
unsigned long rx_frame_errors; /* recv'd frame alignment error */
unsigned long rx_fifo_errors; /* recv'r fifo overrun */
which seems consistent with that information. (Similar entries appear in
a few other headers there too.)
And egrep'ing some nic drivers for "rx_frame_errors|rx_fifo_errors"
reveals notes like "Packet too long" for frame and "Alignment
error" for fifo.
So if it's wrong, it appears consistently wrong.
As to the cause of the errors -- fifo overrun, once the nic is configured
and negotiated right, might just mean "you have a (seriously) large amount
of traffic on that interface". Presumably you've already considered what
devices might be generating that traffic, and isolating things on their own
network segment. An alternative is that the machine itself is too busy to
process the interrupts and data, but you would likely have spotted that sooner.
Frame alignment, on the other hand (again, presuming that it isn't just an
artifact of a nearly-full buffer) suggests that some other device is generating
a dubious frame. Any consistent pattern in source MAC or IP which can be used
to point the finger?
[[[[Ramon]]]] - Nope the reason I couldn't believe the error at first sight is that
it is NOT failure behaviour. It simply is legit traffic ;-)
It's the external nic on the load-balancer for the website I work for. It's
pulling 9M+ pageviews per day with a 12 hour sustained peak of 500K+ pageviews
per hour. All that traffic needs to go through this single 100Mbit interface,
in large amounts of small http request packets.
I'm swapping it out for a Gigabit card later today.
We'll probably frame the card as an achievement and hang it somewhere around
the office :-D
Search Engine Spiders
bob van der Poel (bvdp at xplornet.com)
Thu Apr 20 16:46:45 PDT 2006
Answered by: Ben, BobV, Francis, Jason, Thomas
Any light on how search engines like google work? I've recently moved
my web stuff to the free site provided by my new ISP. For some reason google
refuses to list any of my "really good stuff". And, doing some searches
I don't think that any other (or very few) pages on this site are being found.
My page http://users.xplornet.com/~bvdp has a fairly unique pattern I can
test "wynndel broadband xplornet". So far the only hits are back to
my OLD web pages which announce a move. BTW, those pages are gone.
I've discussed this with Xplornet and they have come to the conclusion
that their site is "sandboxed", but don't know why, etc. And, frankly,
I'm not sure they care much either :)
I have tried to "seed" things by filling out the google form
(sorry, forget the exact spot right now).
I find the whole issue pretty interesting, especially since in the
past when I've created new pages, etc. they have been found by google within
hours. Days at the most. These new pages have been up for about a month now
and not a hint from google.
[Thomas] - Probably then, the google site is listed in 'robots.txt' on the
webserver as not being valid when sending out bots to spider your site (or a
subdomain). It's a common practise to ban most harvesting bots, and to allow
only a few.
[[BobV]] - I've actually checked that out. The ISP assures me that there are
no robots.txt files buggering things up. I should have mentioned that in my
original post, I guess.
[Thomas] - Google work by sending out spiders -- programs that essentially
use referral-following (URL-hopping if you like) to see what's what. The greater
linked your site is, the greater the chance you'll get'spidered'. (I am sure
this is explained on google's site. Go and look).
> searches I don't think that any other (or very few) pages on this site
> are being found. My page http://users.xplornet.com/~bvdp has a fairly
> unique pattern I can test "wynndel broadband xplornet". So far the only
> hits are back to my OLD web pages which announce a move. BTW, those
> pages are gone.
So? Even if your site is hit by google (or some other indexing surveyor)
that's still no guarantee your search results will show up. Consier a company
such as Google. Do you have any idea just how much data they house? Whenever
you goto 'www.google.com', and perform a search -- you're connecting to a
different cache of information each time, so the results you get returned
for a known search may well differ. And note that "specific" !=
"likely chance of singular hit". In fact that's quite the opposite.
If your site is the only one listed with a specific phrase, and has not been
referenced elsewhere on the net for google to pick up, what do you think the
chances of it being listed are?
> I've discussed this with Xplornet and they have come to the conclusion
> that their site is "sandboxed", but don't know why, etc. And, frankly,
> I'm not sure they care much either :)
To me it's a moot point, and is slightly egotistical to want to see your
site on a search engine. If that happens all well and good. Doubtless it might
happen eventually.
[[BobV]] - Of course it is moot. Which is why I posted this message. Figured
it might of some interest to others. Sorry if you think I'm just being egotistical
or whatever.
[Jason] - Quoting BobV, "Any light on how search engines like google
work?"
Well, you start with a novel concept and a bunch of really smart people.
Then you leverage commodity hardware and open source software to create a
superior product with a clean, simple design. You dominate the market, go
public, and then you sell out your principles to help China suppress free
speech...
...oh, you mean *technically*? No idea. :-)
[Ben] - Well, there's a surefire way to find out if Google knows about you:
ben at Fenrir:~$ google http://users.xplornet.com/~bvdp
Sorry, no information is available for the URL users.xplornet.com/~bvdp
* If the URL is valid, try visiting that web page by clicking on the following link: users.xplornet.com/~bvdp
* Find web pages that contain the term "users.xplornet.com/~bvdp"
I guess it doesn't. I'm assuming you went to http://www.google.com/addurl.html
to add yourself - yes? And you made sure to put in a list of keywords that
are relevant to your site - yes? I've always found this to work just fine
for my clients, although it does take up to a couple of weeks (and it's amazing
how impatient people can get in the meantime. :)
[[BobV]] - Yes, that's what I did. I also tried to set up a site map but it
appears that I need permission to run python on the site for that to work. I
can't run anything on the remote site, so that is out.
[[[Francis]]] - All the site map is is a list of links, yes? Probably with some
organisation and grouping and background and the like, but fundamentally, a
link to every page on one page? (And the hrefs shouldn't start with "http://",
and probably shouldn't start with "/" either, for portability.)
Do you have a local copy of the web site content? If so, you can run a local
web server configured similarly to the public one, and run the site map generating
program against that. (Or use "find" with some extra scripting,
but that uses a file system view rather than a web client view of the content.)
That should lead to one or a few html pages being created; upload them to
the public site and you're laughing.
[[[[BobV]]]] - Yes, I think you have it pretty much correct. I've not bothered to
'dl the code ... I don't see that it does me much good to know how simple my
simple little site is :) But, you idea of running in on the local site and then
putting the results on my public site crossed my mind as well. Unless they have
some checksums/tests in the code it should work fine.
[Ben] - So, try submitting to a bunch of other engines in the meantime. They
all "steal" from each other, AFAIK - and the more places there are
on the Web that refer to your site, the higher the chance that Google will run
across it sooner.
[[BobV]] - You know, I get to used to using google that I forget that other
engines even exist. Just for fun, I tired yahoo and, interestly, it found the
site.
So, it probably is just a matter of time.
[[[Ben]]] - This should also provide a bit of reassurance on Google's score: if
Yahoo indexed you, then so will they - in their own good time.
2[BobV]- Honestly, this is not a big deal with me. I do contribute some software
and ideas which I suppose other folks might be interested in (which is why it's
on the web). I'm just trying to understand (at a low level) how these search
spiders work. I wonder, with all the computing power that something like google
has ... how long would it take to "spider" the whole web? They are
already referencing billions of pages and my mind gels thinking of how many
links that might involve, let alone keyword combinations.
[[[Ben]]] - Oh, it's fun (and at least somewhat mind-boggling) to think in those
terms. I mean, just how much space does the Wayback machine (which takes regular
snapshots of just about everything on the Net) have? More interesting yet, when
will that kind of capacity - and data-processing capability - become available
to us consumer types?
"Say, Bob, do you happen to have the latest copy of the Net? I think
I'm a bit behind; just beam me your version if you don't mind..."
4 [BobV] - Did I read somewhere, recently, that someone was marketing a disc
(HD?) with "the net" on it. Well, a very small subset of the net :)
I think this was for folks who didn't have broadband or something. Seemed like
a silly idea to me.
So, which is growing faster ... consumer storage or the size of the net?
I'd bet on the net! Mind you if we take all the porn, music, duplicate pages
and warez software off the net ... well, gosh, then there would be nearly
nothing left.
[[[Francis]]] - Do you have access to the web server logs? Ideally the raw logs,
which you can play with yourself; but even the output of one of the analysers
may be enough.
[[[[BobV]]]] - Unfortunately, no. Just a dumb site from this end.
[[[Francis]]] - If you can see the HTTP_USER_AGENT header in the logs, you'll
have an idea of when the search engine spiders visit. Apart from the "normal"
clients, almost all of which pretend to be some version of Mozilla, the spiders
tend to have reasonably identifying names.
[[[[BobV]]]] - Interesting. No secrets on the web :)
[[[Francis]]] - If you've ever seen "googlebot" (or however it is spelled)
visit, you can expect that they are aware of your content[*]. And if you've
never seen "yahoobot" visit (again, I'm making up the user-agent string
here -- when you see it, you'll know it) you can wonder about how they managed
to index your content.
[*] Unless it's someone playing games, using that sort of identifier in their
own web client. All of the HTTP headers are an indication only.
Whether the logs are available is up to the hosting company. And if they
are available, whether they include HTTP_USER_AGENT or HTTP_REFERER or any
other specific headers is also up to them.
But if you can get the logs, you can spend hours playing with them and finding
trends and counting visitors and seeing why "unique visitors"
is a fundamentally unsound concept. But there are almost certainly more enjoyable
ways of spending your time :-)
Good luck
[[BobV]] - Impatient ... when you say "weeks". Gosh, Ben, these days
anything more than a minute or two is an eternity :)
[[[Ben]]] - [laugh] Well, there is that. Most people have been trained to expect
instant gratification these days (athough many claim that instant is too slow
in the Internet Age), and a couple of weeks might as well be a lifetime. Although
I understand that a baby still takes nine months, no matter how hard you work
at it. It's all so confusing...
Quoting from the classic "Story of Mel",
Mel loved the RPC-4000 because he could optimize his code: that is, locate
instructions on the drum so that just as one finished its job, the next would
be just arriving at the "read head" and available for immediate
execution.
I suspect that your previous experiences happened when your part of IP space
(or whatever other system Google uses to sequence their spiders) was just
about to "arrive at the read head". This is, I assure you, not the
usual case. :)
Profile has errors
K1 (research.03 at gmail.com)
Thu Apr 13 16:21:06 PDT 2006
Answered by: Thomas
Hi:
I am new to IPCOP and am learning it while setting it up, I wonder
if you can point me to asomeone who can help me.
Your article was very informative, but my issue is with DSL.
I have Verizon DSL and am using a Westell Versalink 327W. I am utilizing
the red and green interfaces.
My IPCOP box is handing out addresses as I have DHCP enabled, but I
get time out errors when I try to ping it . When I access it from a browser
on the green interface I get "Current profile-Non" and "the profile
has errors".
When I view the log on my Westell I see my ipcop box. Help what am
I doing wrong?
[Thomas] - What are these 'red and green interfaces'?
What about using ''traceroute'' instead? What's your network topology like?
Are you using a gateway (perhaps some form of NAT?) Do you handle your own
DNS? You need to be much more thorough in the information you detail to us.
Sounds like you need to read the IPCop userguide, or somesuch then.
You're not telling us what's in the logs, for starters. We're not mind
readers -- and knowing what's in this file, might just help provide pointers
as to its solution.
Where can I find GLUE (Group of Linux Users Everywhere)
Shlomi Fish (shlomif at iglu.org.il)
Sat May 6 19:56:15 PDT 2006
Answered by: Ben, Rick, Shlomi
Hi!
I am the dmoz.org editor of the Linux Users' Group category. Recently,
GLUE (Group of Linux Users Everywhere) has disappeared from the Net. What is
its status and when will it be restored? Does it have a new URL?
Regards,
Shlomi Fish
[Ben] - Well - hi, Shlomi! Pleasure to hear from you.
(Shlomi Fish is a long-time contributor to the Perl community; lately, for
example, I've enjoyed his contributions on the "Perl Quiz-Of-The-Week"
list - so it's a pleasure to be able to give what help I can in return, little
though it may be in this case.)
A quick search of the Net seems to indicate that GLUE was being hosted by
our former webhost, SSC with whom we parted ways quite a while back.
[[Shlomi]] - I see.
[Ben] - According to the Wayback Machine, though, whatever arrangement they
had never amounted to much:
http://web.archive.org/web/*/http://www.ssc.com/glue/groups/
My best suggestion for anyone looking for a LUG is to take a look at the
{ http://www.linux.org/users/[LUG Registry]} - but I'd imagine that you already
know that. As to GLUE, my best guess is that they're gone.
[[Shlomi]] - I see. Well, I'll try to find out at SSC.
[Rick] - Hi, Shlomi. Ma nishma? ;->
[[Shlomi]] - Hi. Ani Beseder.
[Rick] - GLUE seems to have been completely eliminated in the most recent Web
site reorganisation at SSC. When that happened, because I reference it in the
Linux User Group HOWTO, I looked in vain for any sort of explanation, so I suppose
none will be forthcoming.
[[Shlomi]] - OK. Thanks. I'll try to find out more at SSC.
Graham Jenkins
Derek (derek.davies at telco4u.net)
Sun Apr 30 11:46:14 PDT 2006
Answered by: Ben, Thomas
Dear Gang, Can you help me ?,my old school friend Graham Jenkins moved
to Australia many years ago ,is he your Graham Jenkins?.
My friend was born in Hereford England on the third of April 1940,attended
Lord Scudamores boys school has three sisters.
This may be a shot in the dark,but I would like to see the old fellow
again before I pop my clogs.
I have been trying to find him for quite a while.
hope you can help
Derek Davies
[Thomas] - You could always look at his author page, and email him. IIRC he
might be claiming to be from Australia.
[[Ben]] - That is indeed what his bio says; "a Unix Specialist at IBM Global
Services, Australia... lives in Melbourne".
http://linuxgazette.net/authors/jenkins.graham.html
> My friend was born in Hereford England on the third of April 1940,attended
> Lord Scudamores boys school has three sisters.
[[Ben]] - The picture in his bio looks a bit younger than that, but it's plausible.
[Thomas] - Scudamores' school, eh? I know of it through reputation.
> This may be a shot in the dark,but I would like to see the old fellow again
> before I pop my clogs.
[Thomas] - That sounds like an awfully odd thing to say.
[[Ben]] - Google shows 981 usages. :)
[Thomas] - I must admit that your question is singularly unique. ;) I don't
think Jenkins is a member of TAG. If you'll permit us to do so, we'll add this
to the Gazette Matters section of LG.
[[Ben]] - I note (again, via Google) that Graham is quite active in the Perl
community and elsewhere. Perhaps emailing him at the address on his page would
be the most efficient way of getting hold of him.
Request for any ADC's driver source code
osas e (osas53 at yahoo.com)
Sat May 20 10:43:13 PDT 2006
Answered by: Thomas
Hello,
I am a student doing a project and want to interface an ADC0804 to
a PC’s parallel port to read the humidity value of the atmosphere. Knowing
that there are professionals like you out there, I am writing to request a driver
source code to read from this or any other ADC using a PERL Program. It is my
belief that you will be kind enough to help a newbie like me grow in computer
interfacing.
Kind Regards
Ediae Osagie
[Thomas] - Tell us more about this project. Does your project also stipulate
that you yourself have to work out how to interface an ADC0804 to the paralell
port?
As a "professional" (and a student) it is usually a given that
a student does their homework beforehand. How is it you heard of us, anyway?
You can't have read the Linux Gazette, since you'd know that we don't do others'
homework. You're no different from this.
Having done some electronics in the past (these are just pointers for you
to consider), interfacing to the paralell port is relatively easy -- assuming
you do so in an appropriate language. C for instance has many different routines
to achieve this, and in fact, any simple I/O system can read and write to
/dev/lp* as is necessary. Try it. That's the only "driver" you'll
really need.
Enjoy your homework -- we won't help you do it.
Talkback: Discuss this article with The Answer Gang
Published in Issue 128 of Linux Gazette, July 2006
The LG Talkbacks
Talkback:122/sreejith.html
[ In reference to the article Stepper motor driver for your Linux Computer in LG#122 ]
(jovliegen at gmail.com) jovliegen at gmail.com
Sun Apr 16 05:20:36 PDT 2006
Answered by: Ben, Jason
Hello, First of all, I like to thank you guys for this great "Gazette".
I realy do enjoy it !!!
I'm trying to build the stepper motor driver, that you published
in issue 122. While reading the code, I have a little remark. I'm not quite
sure that I'm right, but ... what do I have to loose :D
On line 20 : "static int pattern[2][8][8] = {"
Shouldn't that be pattern[2][2][8] ?
Like I said before, I'm not sure of this ... just wondering ...
Thanks again for your nice work, all of you
[Jason] - Thanks! It's great to hear from readers.
I went and looked at that author's code, and it sure looks like you're right.
Note that it doesn't hurt anything to declare the array as larger than you
need it, but it's probably not the best style.
There's a few other things in that code that I might have done differently.
For instance, his "step" function looks like this:
int step()
{
if(k<8) {
// if(pattern[i][j][k]==0) {
// k=0;
// printk("%d\n",pattern[i][j][k]);
// k++;
// }
// else {
printk("%d\n",pattern[i][j][k]);
k++;
// }
}
else {
k=0;
printk("%d\n",pattern[i][j][k]); /*#####*/
k++; /*#####*/
}
return 0;
}
Note that this does not have the exact same behavior as the original function.
In the original function, after step() returns, k is in range [1,8], inclusive.
In the version I give, k is kept in the range [0,7], inclusive, which is the
correct range if k is being used as the index of an array of length 8.
Unless I'm really missing something, I don't think the actual code to write
the parallel port was included in that article.
Thanks for taking the time to point this out.
[[Ben]] - As I recall, the author used a shell script to prod the device.
Talkback:123/jesslyn.html
[ In reference to the article uClinux on Blackfin BF533 STAMP - A DSP Linux Port in LG#123 ]
Robin Getz (rgetz at blackfin.uclinux.org)
Sat May 6 09:09:25 PDT 2006
Answered by:
In http://linuxgazette.net/123/jesslyn.html Jesslyn Abdul Salam
wrote:
>The Blackfin processor does not have an MMU, and does not provide any
>memory protection for programs. This can be demonstrated with a simple program:
This is only true if you leave this feature turned off.
The Blackfin processor does include hardware memory protection, which
the uClinux kernel supports - but since it effects performance, and most embedded
developers only turn this on when doing development, and it is turned off
by default.
http://docs.blackfin.uclinux.org/doku.php?id=operating_systems#introduction_to_uclinux
When you take:
int main ()
{
int *i;
i=0;
*i=0xDEAD;
printf("%i : %x\n", i, *i);
}
and run it on the Blackfin/uClinux, you get:
root:~> uname -a
Linux blackfin 2.6.16.11.ADI-2006R1blackfin #4 Sat May 6 11:38:53 EDT 2006
blackfin unknown
root:~> ./test
SIGSEGV
Which is pretty close to my desktop...
rgetz at test:~/test> uname -a
Linux test 2.6.8-24.18-smp #1 SMP Fri Aug 19 11:56:28 UTC 2005 i686 i686
i386 GNU/Linux
rgetz at test:~/test> ./test
Segmentation fault
Talkback:124/dutta.html
[ In reference to the article Interfacing with the ISA Bus in LG#124 ]
Abhishek Dutta (thelinuxmaniac at gmail.com)
Mon May 8 01:11:49 PDT 2006
Answered by: Ben, Thomas
Hi,
Could you please change address my website in the article http://linuxgazette.net/124/dutta.html
published in MArch,2006 issue of linuxgazette.net
You can get more details and photos related to this project at http://www.myjavaserver.com/~thelinuxmaniac/isa
The website address has changed from mycgiserver.com to myjavaserver.com
--
Abhishek
[Thomas] - I wouldn't have thought so. Most of the mirrors have probably synched
by now, not to mention copious other sources. By changing your article now,
that's be known as a fork -- something not desirable at all.
[[Ben]] - Even more importantly - since 'creating a fork' for already-published
content doesn't bother me much - it would be essentially pointless; we currently
have nearly 60 mirrors and several translation sites, and the only site that
we can change is ours (i.e., the root site.) In other words, even if we change
it - which I'll do, since it's trivial - anyone searching for your article will
still be about 70 times more likely to find the old address rather than the
new one.
For anyone contemplating writing an article, this is why I encourage including
the pertinent images, sources, etc. as part of the submission: external links
die. The author's details - including the URL in their bio - are flexible,
since the bios are reloaded monthly by all the mirrors; the article content,
once published, is essentially frozen in time.
[Thomas] - The best you can hope for is that I/we/someone publishes this request
in the gazette for next month. ;) Of course, given that the talkback feature
points here, and not to your personal address, you can at least be assured that
any correspondence will reach us and not some void.
[[Ben]] - Excellent point, Thomas! I hadn't considered that particular benefit
of it.
Talkback:124/smith.html (7)
[ In reference to the article Build a Six-headed, Six-user Linux System in LG#124 ]
Eric Pritchett (eric at gomonarch.com)
Mon Apr 24 15:07:31 PDT 2006
Answered by: Ben, Jimmy, Karl-Heinz
How would you configure this setup to use usb speakers for each
user. I think the ideal solution would be to have a usb keyboard with a built
in usb hub that has two usb slots, so you can plug in your mouse and usb speakers.
Any thoughts?
[Jimmy] - That would solve the simpler problem: that of having the speakers
close
to the user; it wouldn't address the other difficulties of using
multiple sound cards: of ensuring that the intended sound is directed to
the correct sound card, in particular.
Ob. mailing list requests: please don't send HTML email (there's a not-so-tenuous
connection between postal workers and the frequenters of mailing lists: you
have been warned :), and should you reply, please don't top post: top posting
makes the Baby {Jesus, Buddha, Xenu, etc.} cry. :)
If you understood my first paragraph, feel free to stop reading, as (bearing
in mind that e-mail to this list is intended for publication) there is a fairly
common misconception here; otherwise: USB is smart, but not that smart -
the fact that devices are located close to each other physically is not communicated
to the OS (that is, the system can't tell that soundcard A is connected to
keyboard A, soundcard B to keyboard B, etc.), which is therefore unable to
act accordingly.
[[Karl-Heinz]] - If the keyboard is its own hub -- the usb tree hierarchy should
be quite able to mirror the physical proximity. I've not read the beginning
of this thread -- but I can imagine a setup with two heads and two keyboards
where "usb speakers" are dedicated to sound produced on one of the
heads.
Just don't expect a standard distribution to do this for you -- this is manual
configuration and it can not be saved in the users settings (like kde) if
the users could be on either head.... pam extensions like group setting on
login for devices like audio might be able help with the setup.
[[[Ben]]] - Interesting idea, that. I can imagine a system - something like LDAP
in general scope if not in implementation - that assigns configured user resources
from the available pool... hm, wish I knew a bit more about creating a project
like that. It wouldn't even have to involve kernel programming, since everything
could be done at the USB level.
Talkback:124/smith.html (8)
[ In reference to the article Build a Six-headed, Six-user Linux System in LG#124 ]
Claude Ferron (cferron at gmail.com)
Thu Apr 27 05:30:25 PDT 2006
Answered by: BobS
any update on the bugs you were experiencing?
[BobS] - Not really. There is a new nVidia driver which does not fix the problem.
Two members of the Xephyr project have written to say that the problem I'm seeing
is due to a reset problem in the nVidia driver. Their solution is to run several
X sessions inside one big X session. This way the boards only get reset once.
The URL for Xephyr is at: http://www.c3sl.ufpr.br/multiterminal/index-en.php
.
Talkback:124/smith.html (9)
[ In reference to the article Build a Six-headed, Six-user Linux System in LG#124 ]
Izzy esteron (izzyesteronjr at yahoo.com)
Sun May 21 06:58:01 PDT 2006
Answered by: Ben, Izzy
To whom it may concern,
This article by Mr. Smith is amazing. In my opinion, this is the solution
all 3rd world countries are looking for to keep hardware cost down. I know the
technology is not perfect yet, but it is a great start.
Anyway, does this setup allow each workstation to have their own audio?
How about network/LAN gaming?
Thank you for your time,
izzy
[Ben] - Well, the former was noted as a problem in the article; there has also
been some discussion on the issue. What it looks like to me is that it would
be possible to make this available with a little work in the kernel - but it
would either take someone experienced in audio and kernel hacking, or convincing
the current maintainers that this is necessary. Conversely, individual external
(USB) sound devices might be a solution.
The latter does not seem like it would be a problem at all as long as the
CPU and the memory is up to it; most of the load in gaming, as I understand
it, is on the video card - and every user has one of their own in that configuration.
[[Izzy]] - Thanks for the reply, it was really helpful.
Last February Mr. Smith posted a message on http://blog.chris.tylers.info
. He mentioned that
"The system is VERY unstable. I get a kernel oops
fairly often when a user logs out. Has anyone seen
this problem before? Any ideas on how to fix it? Also,
any suggestions to improve my article?
thanks,
Bob Smith"
Also, there was a couple of replies after this message and showed how to
solve the problem by downgrading the nvidia drivers. Has Mr. Smith tried the
"fixes"?
Thanks again.
Talkback:125/collinge.html
[ In reference to the article HelpDex in LG#125 ]
Diego Roversi (diego.roversi at gmail.com)
Tue Apr 4 01:49:33 PDT 2006
Answered by: Ben, Rick, Suramya
I can see the comics. What's wrong with the old good image formats?
Why not PNG or JPG?
[Rick] - Guys, plainly we need to FAQ this.
Diego, this was discussed in the prior issue (#124). Please see: http://linuxgazette.net/124/misc/nottag/flash.html
Note open-source (reverse-engineered) Flash implementations in various degrees
of completion, detailed at http://osflash.org/ . Note also excellent and
authoritative analysis by Kapil Hari Paranjape at the first URL cited. (Kapil
views HelpDex using the open-source swfplayer software, which he finds adequate
to the task. I recommend that plus the Flashblock browser extension, http://flashblock.mozdev.org/,
so that you retain the ability to view Flash only when you wish, not when
some advertiser so dictates.)
Diego, you're welcome to work with us every month to convert the Ecol comic
strip to formats you prefer -- without the results sucking, please -- or become
a cartoonist and start sending us good cartoons in a graphics format you prefer.
Otherwise, your answer would seem to be as above.
[[Ben]] - I don't know that an FAQ entry would be of much use; in my estimate,
the percentage of our readers who have looked at our FAQ is very small.
[[[Rick]]] - Interestingly, one of the less-appreciated but substantial benefits
of a FAQ has nothing to do with whether people ever bother to read it before
asking its questions or re-raising its tired old subjects. That is: When somebody
does go there for the 1000th time, you can definitively answer, with near-zero
effort, with just a URL.
[[[[Ben]]]] - Which presumes remembering the URL in question... but I do see your
point. That "secondary" use of the FAQ has even more benefits than
I thought - all natural consequences, to be sure, but my mind wasn't quite twisty
enough to see all the rami. In short, kudos.
[[[[[Rick]]]]] - Why, thank you, sir.
You might enjoy the slightly cranky bit of documentation that I posted to
the prototype wiki replacement for Silicon Valley Linux User Group's Web site
(on one of Heather's machines), starting with header "Standards, Nits,
Peeves" on this page:
http://gemini.starshine.org/SVLUG/Teams/Web_Team
I was definitely getting in touch with the curmudgeon within, when I wrote
this entry:
website/Website: No such word. Correct to "Web site".
No, there's nothing wrong with inventing new words, especially where
they make our language more expressive and fill a need not met by
existing words. This one doesn't qualify, and is really just the result
of people being sloppy. Some would call our cleaning it and similar
things off our pages "prescriptivism"; I prefer the term "leadership".
[[[Rick]]] - Over the years, I've used this trick to dispose of innumerable topics
after getting tired of discussing them. My first-level expectation is that hardly
anyone will read my answers until I send their URLs. Note: I do take advantage
of that expectation to expose readers to adjoining text on related questions.
[[[[Ben]]]] - Sneaky. And useful.
[[Ben]] - However, it might make sense to add some sort of a note regarding
this issue to the top of the strip. I'll give the wording some thought and glue
it in.
[[[Rick]]] - My opinion, yours with a small fee and disclaimer of reverse-engineering
rights: Less is better. E.g.,
'' Format: Flash ''
...where "Flash" is anchor text hyperlinking to a FAQ, for which
http://linuxgazette.net/124/misc/nottag/flash.html might serve nicely.
Metacomment: Computerists tend to overestimate public willingness to deal
with explanatory text. The public at large tends to react badly to verbosity,
assuming its contents to be
- unimportant, and/or
- open to debate
This is why we have "STOP" signs, rather than "Stop, though
of course there are lots of exceptions including the need to do anything required
to avoid dangerous situations" signs.
[[[[Ben]]]] - [laugh] Kat just finished her Power Squadron course (scored 100% on
her test, woo-hoo!); this is almost exactly the phrasing used for right-of-
way rules in navigation. Which is why, I suspect, so many people screw up in
that regard.
[[Suramya]] - Umm... I have a low tech approach to converting the Ecol comic
strips from flash:
Click on the link to view the flash file, take a screen shot and save it
in the format you want. Sample output:
http://www.suramya.com/Temp/HelpDex.jpg
:)
If I get the files early enough I volunteer to do this. But let me know what
you think of this...
[[[Ben]]] - 1) At the moment, there's no way to do actual thumbnails linked to
full-size images in the cartoon section. Changing that would require twiddling
Mike's Python scripts - and I'd have no idea how to do that.
2) JPG files are significantly larger than the equivalent SWFs - and go all
jaggy when viewed at anything but "native" size (unless, of course,
you go with an even larger file size.) E.g.:
:-r!ls -l /tmp/Help*
-rw-r--r-- 1 ben root 80715 2006-04-06 12:50 /tmp/HelpDex.jpg
-rw-rw-rw- 1 ben root 18546 2005-12-06 21:21 /tmp/HelpDex.swf
Add a thumbnail to that, and we've got a big chunk'o'download - for no gain
(and, in fact, image quality loss.)
3) The issue is - except for the very rare complaint - settled. There's Open
Source viewing software available, which seems to work fine, and those who
complain will now be redirected (either from here or from the link on the
page itself) to the discussion covering it.
So - thank you for the offer, Suramya, but there's no need. It's all good
to go.
Talkback:125/howell.html
[ In reference to the article A Brief Introduction to IP Cop in LG#125 ]
André Fellows (andrefellows at hotmail.com)
Tue Apr 11 13:43:21 PDT 2006
Answered by: Ben
Hi folks!
This IP Cop is another leaf of the Linux Firewall/Router/DHCP server distros.
I have to tell you that this IP Cop seems to me not good as BrazilFW.
I used Coyote (http://www.coyotelinux.com/ ) but it was discontinued.
The BrazilFW (www.brazilfw.com.br)
is the Coyote continuation.
Try there, its free, fast and painless!
Cheers
Fellows
[Ben] - Then the obvious thing to do is a bunch of research comparing the two
and presenting your results in an article. Otherwise, thank you for telling
us how it "seems" to you... but I'm not sure why you'd want to share
this information. [1]
I've used Coyote in the past on several occasions, and liked it a lot; for
basic routing and firewalling, it was quite a nice gadget. However, IPCop
has many more features than Coyote did - at least so I gathered from the article.
DIfferent pieces of software, different purposes. One is not "better"
than the other - just different. Implying otherwise, especially without supporting
data, is rather inconsiderate toward the person/people who took the time to
write the software that you don't like.
[1] This is a (perhaps somewhat testy) way of pointing out that saying "program
$X is good" does NOT require adding "because program $Y sucks"
for the purpose of emphasizing the former; there's no subordinate clause implied.
Since this is not the world of proprietary software, in which vendors are
fighting tooth and nail to sell their latest crap-a-riffic bugware, *we do
not have to denigrate competing software* - it brings us, as a community,
no benefit, and may do damage to a fellow programmer's reputation. So, yeah,
this hits the rant button for me.
[[André]] - My sincere excuses!!!
I forgot to mention that my "seems" is not to consider!
[[[Ben]]] - Relax - my mini-rant was a generalized one. I replied to your statement,
but it's about more than that; it's about an important consideration for the
Linux community in general. We should always be striving to support each other,
not tear each other down.
Often, operating in the world of Open Source requires re-thinking the "standard"
ways of interacting with the other people involved. This differs from what
we're generally used to, but is usually easy to adapt to: substituting cooperation
for competition, especially when the benefits are obvious and immediate, presents
little difficulty for most people.
It does, however, require thinking about it ahead of time - which is what
I'm trying to get people to do with my rant. Thanks for the opportunity. :)
[[André]] - My intention was to tell you guys about the BrazilFW, the
Coyote sucessor. Like Coyote, BrazilFW have many addons to improve its funcionality.
The "seems" part was because I thinked you guys could make an article
comparing both and its funcionalities.
[[[Ben]]] - Well, we don't generally write articles - but we do accept well-written
ones on Linux-related topics. If you'd like to write one about BrazilFW, I'd
be happy to look at it.
[[André]] - This is the point of the information. Really sorry if I wasn't
clear (and I really wasn't ).
Very very very sorry to make you Benjamin spend your time on mine nonsense
comparison...
[[[Ben]]] - Don't worry - there was nothing particularly awful in your email,
and I wasn't upset.
[[André]] - Oh, by the way, Linuxgazette is a GREAT SITE with GREAT information!!!
[[[Ben]]] - Thank you, André! We do our best. Glad to hear that you're
finding it useful.
Talkback:126/cherian.html (1)
[ In reference to the article Preventing DDoS attacks in LG#126 ]
Thomas Adam (thomas at edulinux.homeunix.org)
Tue May 2 13:49:25 PDT 2006
Answered by: Ben
Hello,
I was intrigued by this article about DDoS. It's something one hears
about more and more, and so I thought I'd give it a go, and play along at home.
Ben, I don't know just what percentage of the original article remains, having
done the rewrite on it (something that I agree with, especially in terms of
attribution), but I would have liked it if the original author could have expanded
on a few things...
* Check if your CPU load is high and you a have large number of HTTP
process running
Heh. Yes, I quite agree. But so what? I mean, how are you supposed
to distinguish that from most other processing that goes on? A simple 'w' isn't
going to help you much there. It's pretty normal for most CPUs to peak.
As for the HTTP process, this is typically mitigated by setting the
following in /etc/apache/httpd.conf to a reasonable value:
MaxClients 30
Now, the Apache folks make it quite clear that this should not be set
too low, blah, blah. But for a small-end server (perhaps even one running on
a home ADSL-connection) setting this to something perhaps lower than 30 in this
case would help in stopping Apache from consuming everything.
Then there's the following command:
ps -aux|grep -i HTTP|wc -l
I know I can be pedantic at times, but on non-BSD systems the leading
'-' causes issues, not to mention the classic "You'll return grep too"
syndrome, as well as the useless use of 'wc' (this isn't for your benefit, Ben,
more the original author):
ps aux | grep -ic '[h]ttp'
* Determine the attacking network
This section was quite good. Note that, as mentioned before, the number
of concurrent connections via Apache can be capped. Again, the command:
netstat -lpn|grep :80|awk '{print $5}'|sort
Can be reduced to:
netstat -lpn | awk '/:80/ {print $5}' | sort
(Too many people seem to think Awk only understands columns in terms
of quoting printed ouput. Such a shame.)
It's worth mentioning here the use of PAM and chroots. A slight side-note
is that in any DDoS attack, the targeted process or thread is generally going
to expand as the load increases on it. This is generally undesirable, and so
one can tell PAM to employ memory usage limits via /etc/security/limits.conf
(think ulimit for processes). As for the chroots, running various processes
inside those can encapsulate their environment away from everything else.
I also couldn't see what the following code was supposed to do:
for f in /proc/sys/net/ipv4/conf/*/rp_filter
do
echo 1 > done
echo 1 > /proc/sys/net/ipv4/tcp_syncookies
I assume that's meant to read:
for f in /proc/sys/net/ipv4/conf/*/rp_filter
do
echo 1 > "$f"
done
echo 1 > /proc/sys/net/ipv4/tcp_syncookies
Hmm. This reads as though I've picked the hell out of the article for
no apparent reason -- far from it. I hope these little tidbits of information
will prove useful. By all means feel free to forward these comments on to the
other author.
[Ben] -
On Tue, May 02, 2006 at 09:49:25PM +0100, Thomas Adam wrote:
> Hello,
>
> I was intrigued by this article about DDoS. It's something one hears about
> more and more, and so I thought I'd give it a go, and play along at home.
> Ben, I don't know just what percentage of the original article remains,
> having done the rewrite on it (something that I agree with, especially in
> terms of attribution), but I would have liked it if the original author
> could have expanded on a few things...
>
> * Check if your CPU load is high and you a have large number of HTTP
> process running
> Heh. Yes, I quite agree. But so what? I mean, how are you supposed to
> distinguish that from most other processing that goes on? A simple 'w'
> isn't going to help you much there. It's pretty normal for most CPUs to
> peak.
I'm a fan of iostat/vmstat, myself - but 'w' will give you the standard
1/5/15 load averages.
That's not much to do with peaks. (Just FYI, I avoided changing the actual
content of the article as much as possible except where it was clearly wrong.
Different usage, or even suboptimal usage, I left alone. Ditto the idiom,
which is why it still sounds mostly like Blessen rather than me.)
As for the HTTP process, this is typically mitigated by setting the
> following in /etc/apache/httpd.conf to a reasonable value:
>
> MaxClients 30
>
> Now, the Apache folks make it quite clear that this should not be set too
> low, blah, blah. But for a small-end server (perhaps even one running on
> a home ADSL-connection) setting this to something perhaps lower than 30 in
> this case would help in stopping Apache from consuming everything.
Right, but he's talking about a server in a data center - I believe that
was mentioned right at the beginning.
> Then there's the following command:
>
> ps -aux|grep -i HTTP|wc -l
>
> I know I can be pedantic at times, but on non-BSD systems the leading '-'
> causes issues, not to mention the classic "You'll return grep too"
> syndrome, as well as the useless use of 'wc' (this isn't for your
> benefit, Ben, more the original author):
>
> ps aux | grep -ic '[h]ttp'
[Nod] Agreed.
> It's worth mentioning here the use of PAM and chroots. A slight
> side-note is that in any DDoS attack, the targeted process or thread is
> generally going to expand as the load increases on it. This is generally
> undesirable, and so one can tell PAM to employ memory usage limits via
> /etc/security/limits.conf (think ulimit for processes). As for the
> chroots, running various processes inside those can encapsulate their
> environment away from everything else.
Again, chrooting is something I'm a big fan of. Heather told me about
it ages back, and I glommed onto the idea like a drowning man onto a
log...
> I also couldn't see what the following code was supposed to do:
>
> > for f in /proc/sys/net/ipv4/conf/*/rp_filter
> do
> echo 1 > done
> echo 1 > /proc/sys/net/ipv4/tcp_syncookies
>
> I assume that's meant to read:
>
> for f in /proc/sys/net/ipv4/conf/*/rp_filter
> do
> echo 1 > "$f"
> done
>
> echo 1 > /proc/sys/net/ipv4/tcp_syncookies
>
> Hmm. This reads as though I've picked the hell out of the article for no
> apparent reason -- far from it. I hope these little tidbits of
> information will prove useful. By all means feel free to forward these
> comments on to the other author.
Yeah, I missed that in the welter of the other stuff I'd corrected.
Well spotted! I'll pass it on - and it should go into the Mailbag as
well, as a followup to the article.
Talkback:126/cherian.html (2)
[ In reference to the article Preventing DDoS attacks in LG#126 ]
Ulrich Alpers (ulrich.alpers at ub.uni-stuttgart.de)
Thu May 4 03:00:01 PDT 2006
Answered by: Ben, Thomas, Ulrich
Hi,
if I am the 10000th to mention, sorry for that ...
The last script snippet looks a bit weird:
-----------------------------------------------------
for f in /proc/sys/net/ipv4/conf/*/rp_filter
do
echo 1 > done
echo 1 > /proc/sys/net/ipv4/tcp_syncookies
-----------------------------------------------------
How about this:
-----------------------------------------------------
for f in /proc/sys/net/ipv4/conf/*/rp_filter
do
echo 1 > $f
done
echo 1 > /proc/sys/net/ipv4/tcp_syncookies
-----------------------------------------------------
As to the syncookies thing: I am not quite sure, but if you have
already put the line
net.ipv4.tcp_syncookies = 1
into the sysctl.conf - what is the syncookies line in the rc.local
for?
Regards,
Ulrich
[Ben] - Come to think of it, it's only a couple of days after publication -
and the error is egregious enough that it shouldn't be propagated. [sounds of
axes, sawing, hammering, copying, and pasting [1] in the background] All fixed
now.
How about this instead:
-----------------------------------------------------
#!/bin/bash
for f in /proc/sys/net/ipv4/{conf/*/rp_filter,tcp_syncookies}
do
echo 1 > $f
done
-----------------------------------------------------
Love those curly-brace Bash expansions. :)
[[Thomas]] - Horses for courses -- both ways'll work.
[Ben] -
> As to the syncookies thing: I am not quite sure, but if you have
> already put the line
> net.ipv4.tcp_syncookies = 1
> into the sysctl.conf - what is the syncookies line in the rc.local
> for?
Right; that should have been (and now is) worded as
Conversely, you could add this code to your '/etc/rc.local':
[[Thomas]] - But this is still wrong. /etc/rc.local is not honoured across all
Linux distributions. SuSE and RH use it (although SuSE for a time used to only
honour /etc/local.rc). RH uses /etc/rc.boot. Debian, for instance, has /etc/bootmisc.sh,
but one shouldn't go changing that arbitrarily anyway (it'll get overwritten
when 'initscripts' is updated). For the Debian people, one can create the following
directory:
/etc/rc.boot
... and place any scripts in there, ensuring that the directory and
scripts themselves have octal permissions '755'.
[[[Ben]]] - That would be the reason for the word "conversely", so I
wouldn't call it "wrong" - just different. Is there a distro out there
that doesn't have an "/etc/sysctl.conf"? I thought that was pretty
much universal in Linux.
On the gripping hand, there's also the fact that we don't purport to cover
all distros - although I like to encourage authors to broaden those "$DISTRO_OF_CHOICE-only"
articles into something a bit more useful. The way I figure it is, mentioning
a couple of different methods should suffice to clue people in about adapting
it to their specifics. If you have a better suggestion that will, without
fail, cover any and every distro (including the one that I'm creating right
now for the specific purpose of evading whatever solution you come up with
:), I'd like to hear it.
[Ulrich] - SuSE uses /etc/init.d/boot.local (among a lot of other boot.* files).
BTW, as we are collecting the locations of the script to put the code into
- Gentoo uses /etc/conf.d/local.start
[Ben] - Between Thomas Adam (who first noted the problem) and yourself, you
two have managed to get me off my lazy butt and fix it. Consider yourselves
promoted, and entitled to wear The Grand and Sublime Order Of The Linux Gazette
[2]. Thank you, congratulations, and may you remain worthy of this high honor!
:)
[1] For those who are not familiar with the BOFH Saga, the sound of these
last two operations is precisely like the sound that will
immediately precede the End of The World:
CLICKETY-CLICK
[2] This looks just like a red stick-on Post-It dot, but is imbued with special
powers; for this week only, we've secretly replaced the Post-It dots in your
local stores with these GaSOOTLGs, which will be activated as soon as you
buy and apply them.
Talkback:126/cherian.html (3)
[ In reference to the article Preventing DDoS attacks in LG#126 ]
René Pfeiffer (lynx at luchs.at)
Sun May 7 15:01:20 PDT 2006
Answered by: Ben
Hello, Linuxgazette!
I read Ben's introduction to the "Preventing DDoS attacks"
article. I can imagine that you get lots of submissions like this. I've given
the idea of having stand-by co-authors some thought. I like the suggestion very
much, especially if it helps to "rescue" content which could interest
a wide audience. However this is clearly much more than proofreading. It involves
communication with the author, and it requires a change of style, obviously.
I think it is a challenge to walk the fine line between helping someone and
completely changing the original idea into something very different.
I am teaching at a technical academy here in Vienna. I supervised and
helped several students working on their graduation. Last year a student submitted
a piece of work that we could not accept, even with all the best intentions.
We gave the student a long list of improvements and had him rewrite the whole
thing from scratch. Of course this is a different approach, because no one can
assume co-authorship for a diploma our students are supposed to write alone.
Nevertheless it illustrates the point of enabling someone else to improve something.
Provided you have a pool of stand-by co-authors and co-authorship is
welcome, it would be nice to have a simple set of rules how to proceed in such
a case. I don't think that it is a good idea to advertise this as a feature
and to encourage people to send half-written articles. Maybe postponing an article
with a list of suggestions to the author is an option then.
Well, that's my brainstorming. English is not my native language, but
in case you want to create a pool of helping hands that co-author and improve
articles, count me in.
Best wishes, René.
[Ben] - [Quoting René]
> Hello, Linuxgazette!
Hi, René! Good to hear from you again.
> I read Ben's introduction to the "Preventing DDoS attacks" article. I
> can imagine that you get lots of submissions like this.
These days, it's averaging a bit more than one per month.
> I've given the
> idea of having stand-by co-authors some thought. I like the suggestion
> very much, especially if it helps to "rescue" content which could
> interest a wide audience.
The original suggestion came from my wife, Kat, some months ago. Ever
since then, I'd been planning to write a Back Page (i.e., get up on my
soapbox), propose the idea, and invite participation - but somehow never
got around to it. Except, of course, now - in a fit of desperation.
> However this is clearly much more than
> proofreading. It involves communication with the author, and it requires
> a change of style, obviously. I think it is a challenge to walk the fine
> line between helping someone and completely changing the original idea
> into something very different.
Indeed. Many of these articles express an important viewpoint that's
just poorly-enough stated, or address an interesting technical point but
fail technical review by an amount just beyond trivial. If it's a case
of pointing out the errors to the author and having them do a rewrite,
or perhaps directing them to try restating their point a bit better,
fine - as I keep telling people, "there's always the next issue".
But
what if the problem is caused by the author lacking just that tiny bit
of knowledge, or that edge of ability to express themselves well in what
may be a foreign languge? I hate to turn those down because I can see
many of these authors trying their best, and missing by just ->that<-
much. If we can find some volunteers, this would be a great resource.
> I am teaching at a technical academy here in Vienna. I supervised and
> helped several students working on their graduation. Last year a student
> submitted a piece of work that we could not accept, even with all the
> best intentions. We gave the student a long list of improvements and had
> him rewrite the whole thing from scratch.
I almost never simply turn an article down; if I reject one, I'll have a
long list of suggestions and examples that an author could use to
improve their article and learn to write better articles overall. This
is, as I see it, one of the duties of an editor.
> Of course this is a different
> approach, because no one can assume co-authorship for a diploma our
> students are supposed to write alone.
What??? "Alone", as in "by themselves"? Shocking. If
it wasn't for those
famous co-authors, Messieurs Ibid, Opcit, and Anon, I suspect that fully
90% of the modern "original contributions" would never have seen
the
light of day. :)
> Nevertheless it illustrates the
> point of enabling someone else to improve something.
>
> Provided you have a pool of stand-by co-authors and co-authorship is
> welcome, it would be nice to have a simple set of rules how to proceed
> in such a case. I don't think that it is a good idea to advertise this
> as a feature and to encourage people to send half-written articles.
[Nod] All joking aside, those are wise suggestions. I think that
half-baked articles have a substantially different quality from the ones
that I find to be this sort of a moral dillemma, and I have no problem
bouncing those back to the author - but, yes, co-authors would be a
resource to be assigned with care and forethought.
> Well, that's my brainstorming. English is not my native language, but in
> case you want to create a pool of helping hands that co-author and
> improve articles, count me in.
René, I'll take your diction and clarity of expression over many a
native English speaker I've known - no joke. Your offer is gladly
accepted. I don't know that I'll have anyone to send to you anytime soon
(I'll be filtering submissions very carefully in this regard), but I'll
definitely keep this possibility in mind. Thank you!
Talkback:126/howell.html
[ In reference to the article From Assembler to COBOL with the Aid of Open Source in LG#126 ]
(trevor at haven.demon.co.uk)
Tue May 2 02:19:42 PDT 2006
Answered by: Ben, Edgar, Jimmy, Trevor
Tag guys 'n' gals,
Converting 6000 lines of old assembly code to, err, cobol ? Why ?
I would estimate that since a simple line of say c#/c++/pascal/basic compiles
down to at least 6 lines of assembly and probably many more then we are looking
at less than 1000 lines of 'high' level code. So it strikes me it would be
quicker and less bug prone to just re-implement the program in a modern language
and gain a few advantages along the way readability included.
It would have been nice if the original code/cobol code had been
linked to or a summary or explaination of the programs function was included.....
Trev
[Ben] - [quoting Trev] "Converting 6000 lines of old assembly code
to, err, cobol ? Why ? "
I'd imagine that it's due to The Golden Rule: He Who Has The Gold, Makes
The Rules.
> I would estimate that since a simple line of say c#/c++/pascal/basic
> compiles down to at least 6 lines of assembly and probably many more
> then we are looking at less than 1000 lines of 'high' level code. So
> it strikes me it would be quicker and less bug prone to just
> re-implement the program in a modern language and gain a few
> advantages along the way readability included.
There are many mainframes out there that don't run "modern" (i.e.,
PC-based) languages. Since Edgar is a mainframe consultant - at least so I
gather from his bio - I can see why he'd be constrained to COBOL and such.
> It would have been nice if the original code/cobol code had been
> linked to or a summary or explaination of the programs function was
> included.....
Well, I seriously doubt that Edgar's free to release his customer's code
for everybody's perusal. I agree, it would be nice if the world ran on Open
Source principles by default, and that it would indeed be interesting to see
what the original programming task was - just so people can snark at the complexity
and re-do it all in three lines of Perl or whatever - but that's not how things
are. Until we take over, at least. :)
[[Jimmy]] - Ah, Cobol. Not the reason I dropped out of college (that was RPG),
but a damn close second place.
[[Edgar]] - I won't try to one-up Ben's responses to the substantive issues.
We readers know why we keep him around...
[[[Ben]]] - Thanks, Edgar - I appreciate the implied compliment.
[[Edgar]] - But essentially you and I have no dispute. Your objections/questions are
all very reasonable. As I remarked to Ben, given a choice, I would prefer
C over any other programming language I have ever used. Regarding the article,
in retrospect it might have made sense to do things a bit differently. Some
background.
Although I have been using Linux since SuSE 5.0, I still consider myself
somewhat a newbie. Several decades of mainframe experience have inured me
against the daily slings and arrows. But even a casual reading of my articles
likely elicits no more than a polite "ho, hum" from the members
of TAG. A while back I discovered how easy it is for even a newbie to do things
that might sound intimidating, to a newbie. I'm addressing newbies.
[[[Ben]]] - Just to expand on that point a bit - that's one of the types of articles
I'm always looking for. In fact, one of my larger challenges in vetting, editing,
and writing articles is to keep or access that "beginner's mind" -
and it's not an easy one. I'm always appreciative of new Linux users who can
write well about their experiences - this is one of the most important types
of articles in LG.
[[Edgar]] - As I was writing the article, I was concerned the problem itself
might be getting too much "air time" as it were. But I doubt most
newbies have done anything in Assembler. Any Assembler. And COBOL?
When I submitted the article, Ben properly chastised me for mentioning that
5-letter-word.
[[[Ben]]] - Ah-ah-ah! I did not. I did, however, poke some gentle fun at you
about it. :)
[[Edgar]] - But I felt it necessary to motivate what I went through and to explain
it in enough detail to make the problem understandable.
The point I really wanted to make -- and it may not have come across well
-- was that Open Source might be of help where one wouldn't necessarily expect
it and that it needn't be terribly difficult to install a package not part
of the distribution you are using.
[[[Ben]]] - This is, in fact, how I took it; that's been a wonderful part of my
Linux experience as well. The Open Source nature of it seems to spawn effort
and creativity in people who wouldn't normally give a rat's ass about writing
software, and motivates others who would otherwise let their ideas die without
expression. As an example, some years ago I ran across a Linux tool that translated
Norton Guide databases - something that made me very, very happy, since it allowed
me to convert some very useful data I'd thought of as lost. Another author had
rewritten the first IDE for C/C++ that I'd ever used under DOS (Borland's Turbo
C++) as a Linux prog (RHIDE), which was responsible for a wonderful bout with
nostalgia. :) There are lots of examples, many people doing wonderful things
simply because the environment is available, there's nearly infinite room to
play in, and you get full credit for your work.
[[Edgar]] - To that extent it might as well have been Pascal to C. Except that
that wouldn't even deserve "ho, hum".
For precisely the reasons mentioned by Ben the code in the article is not
even the code dealt with, although functionally equivalent. And long-term
it is not a question of one, single program. This is far more than merely
proof of concept. The people I am doing this with long ago left the starting
blocks. And there is reason to believe that many other companies need quickly
to get away from Assembler into something else main-stream. Anything! Before
their last remaining Assembler programmer retires.
But, Trevor, you have given me a very interesting idea.
I need to check this out, but I am fairly confident that C is an intermediary
step in the compilation process, under Linux. I'm the only one in this crowd
regularly using Linux, but not C. The code might be ugly. I need to look into
it. But down the road...?
Thanks for your comments.
[[[Ben]]] - I'll be looking forward to that article, too. :)
As to package installation - heck, most interesting things are already available
as packages, especially in distros that make a point of it. When I find something
on the Net that I'd like to install, I usually check for an existing Debian
package containing it - and find it in better than half the cases.
ben at Fenrir:~$ apt-cache show open-cobol
Package: open-cobol
Priority: optional
Section: devel
Installed-Size: 464
Maintainer: Bart Martens <bart.martens at advalvas.be>
Architecture: i386
Version: 0.32-1
Depends: libc6 (>= 2.3.5-1), libdb4.3 (>= 4.3.28-1), libgmp3c2, libltdl3 (>= 1.5.2-2),
libncurses5 (>= 5.4-5), libcob1 (= 0.32-1), libcob1-dev (= 0.32-1)
Filename: pool/main/o/open-cobol/open-cobol_0.32-1_i386.deb
Size: 175364
MD5sum: e939fd76f9592030eabd051e8f168ba4
Description: COBOL compiler
OpenCOBOL implements substantial part of the COBOL 85 and COBOL 2002
standards, as well as many extensions of the existent compilers. OpenCOBOL
translates COBOL into C and compiles the translated code using GCC.
.
Homepage: http://www.opencobol.org/
So for me, it's just a matter of typing "sudo apt-get install open-cobol".
Debian takes care of all the dependencies, etc.
[[[[Trevor]]]] - Well guys I'd better explain what went through my mind when I read
the article, it went something like "This guy's creating a problem' now
my experience and current nightmare is legacy code, where I'm at (I work for
IBM on uk government outsourcing projects) we have a number of older systems
that need modified, updated and in many cases replaced. The cost of hiring people
with 'legacy' skill sets which these days increasingly includes COBOL is high.
One day that piece of COBOL will need either it's function modified or the
hardware will be replaced (nothing lasts for ever) with an off the shelf x86/opteron
commodity server (hopefully running Linux) and someone will have to re-do
the work and that might meaning having to hire an expensive contractor or
re-write the whole system in some other language and that is a cost that could,
at least in part, have been avoided.
I have seen huge amounts of time and money spent dealing with this type of
'patching up' it's my pet hate.
[[[[[Ben]]]]] - Sure; anyone who's been a programming consultant for any length of
time has seen this, and it's always the same kind of double-bind. However, this
is also exactly the situation I had in mind when I quoted the Golden Rule -
what most of us neglect to consider, at least when we first run into the situatuon,
is the financial/operations end of the problem from the client's point of view.
When a client (whose entire codebase consists of, say, COBOL) discovers that
he needs to patch/modify/fix/tweak/whatever that codebase, the first questions
that arise will inevitably be these:
1) What will it cost?
2) How much of an interruption of business will it create?
In the case of the first question, a patch - or even a large series of patches
or mods - is usually much cheaper than a complete rewrite, especially when
that codebase is large. So, the decision to patch, and keep patching some
obscure horror that can only be fixed by one doddering wizard (all others
having either croaked or switched to Java, which is essentially the same thing
:) is pretty much the default - absent some immediately-pending and obvious
(or already extant) catastrophe. Trying to convince clients that it's going
to happen before that point will mark you as a doom-sayer with a sly second
agenda, and will not result in happy relations with that client.
In the case of the second question, the problem is even worse - far worse.
A patch - even if it's relatively major - can usually be rolled back fairly
easily in case of problems; a complete replacement - which usually involves
system changes (hardware, configuration, OS change) cannot. Certainly not
easily. Can you, or any programmer, guarantee that bugs - even major ones
- will not show up after the replacement, and take the business out of operation
for some length of time? The answer is, of course, no - and so, a complete
rewrite is very risky.
In short, clients usually hate rewrites, and love patches - and if you keep
wishing that it wasn't otherwise, you'll only get frustrated. I learned, a
long time ago, to take my satisfaction in charging all the market will bear
for overtime, etc. when the crash does come; verbal "I told you so"s
bring no more than transient satisfaction, and put no money in your pocket.
:) By that time, I tend to be uniquely qualified as The Right Programmer to
do the job - since I've used the patching process to study the client's entire
business flow (as it relates to the software) and can not only write the new
code but know how and where the system can be improved.
Looking at this kind of thing as an opportunity rather than a problem has,
over time, proven to be very rewarding. :)
[[[[[Edgar]]]]] - Hi Trevor, I hope you don't feel that "we" are picking
on you. This wasn't orchestrated. I still have essentially your attitude but
a few years ago resigned myself to the fact that the real world is as described
by Ben. About 5 years ago I quit telling everyone who might understand that
we need to get away from Assembler. As an outside consultant I don't have access
to the appropriate managers and they wouldn't understand the problem anyhow.
Basically I'm as frustrated as you are. But I have learned to live with it
and don't lose any sleep over the situation. That the managers are incompetent
is clear when you consider that I am now the only one left with Assembler
skills. An outsider! Unexpectedly, I spent a couple of weeks off work this
year due to skin cancer (taken care of) and during that time absolutely nothing
happened at work, in spite of the fact that we had a deadline of 31 March.
How can they sleep at night if they understand the situation?!
That is my major customer at the moment, government service. I can't speak
about the UK but I am now convinced that the government service systems in
Germany and the USA cannot be reformed and need to be junked. I'm not going
to start a campaign and it of course won't happen. But if the tax-payers were
aware of the money wasted and the virtual sabotage on the part of too-highly-rated
civil servants...
In the case of converson to COBOL, that is a project for someone I have twice
worked for and have known for well over 30 years. The customer, for whatever
reasons, wants to move from Assembler to COBOL. My guess is that the rest
of what they have is in COBOL and if that in fact is the case, the decision
is not completely wrong. At least it is a simplification of their computing
environment.
By the way, in both cases I am dealing with financial computing, i.e. BIG
mainframes. Until discovering Open COBOL and GMP I wasn't aware that decimal
arithmetic was readily available outside the mainframe world. Well, back in
8080 and Z-80 days I used DAA, 'nuff said.
I'm afraid, as much as I don't want to admit it, Ben once again is right.
The world just ain't the way we'd like it. When I did my military service
there was an expression: shit floats. Basically Peter was an optimist, if
only incompetence were readily recognizable at the level where it first floats!
But somehow, perhaps as it rots and begins to stink, it seems to take up more
space and float even higher.
Sadly, too many people, like Billy, could sell SNOW to Eskimos.
Don't give up trying to do things right. But don't let it get to you psychologically.
Talkback: Discuss this article with The Answer Gang
Published in Issue 128 of Linux Gazette, July 2006
NewsBytes
By Howard Dyckoff
 |
Contents:
|
Please submit your News Bytes items in
plain text; other formats may be rejected without reading.
[You have been warned!] A one- or two-paragraph summary plus a URL has a
much higher chance of being published than an entire press release. Submit
items to bytes@linuxgazette.net.
News in General
 Eclipse Callisto shines in FOSSw world
Eclipse Callisto shines in FOSSw world
"Callisto" is a coordinated, simultaneous release of some 10 new
or upgraded releases of major projects. This includes version 3.2 of the
Eclipse Platform and these other new releases:
* Business Intelligence and Reporting Tools (BIRT) Project
* C/C++ IDE
* Data Tools Platform
* GEF - Graphical Editor Framework
* Eclipse Project [v. 3.2]
* Eclipse Test and Performance Tools Platform Project
* Eclipse Web Tools Platform Project
* VE - Visual Editor and
* Eclipse Modeling and Graphical Frameworks
Callisto was a major undertaking for the Eclipse community, involving 10
different project teams, 260 committers and over 7 million lines of code.
Demonstrating the multi-vendor and global nature of the Eclipse community, 15
different ISVs contributed open source developers to work on the projects
included in Callisto.
The coordination took the better part of a year and involved Bjorn
Freeman-Benson, technical director of infrastructure at the Eclipse Foundation,
and Ward Cunningham, Director, Committer Community Development, who left
Microsoft in 2005 to work with Eclipse. [Cunningham has been described as the
father of the wiki.] Eclipse presenters from IBM at JavaOne had described the
level of maturity and coordination built into the Eclipse process during a
morning keynote and also at a JavaOne BOF. This is based in part on advanced
collaboration tools shared by all Eclipse project leads [IBM suggested that it
may productize some of the process tools]. It also involved coordinating bug
fixes with Bugzilla.
http://www.crn.com/sections/breakingnews/dailyarchives.jhtml?articleId=189601018&pgno=2&queryText=
http://www.eweek.com/article2/0,1895,1981651,00.asp
http://www.eclipse.org/projects/callisto.php
Also see free archived webinars on how you can use the
different Eclipse projects. These use Adobe's Macromedia Breeze meeting service
to host the webinars: http://www.eclipse.org/callisto/webinars.php
RSA folds into EMC
EMC had an expensive lunch at the end of June. For a whopping $2.1 billion,
it acquired security and identity company RSA, orignially founded by the 3
cryptologists whose initials make up its name.
Although financial analysts were skeptical about the potential integration
issues and the high cost, EMC's CEO Joe Tucci called the purchase "critical
technology" for adding security to storage solutions. One area of possible
synergy is regulatory compliance, where data security is of increasing
importance. However, RSA has not been primarily a sales organization, as EMC is,
and the corporate cultures may clash.
RSA put itself up for auction several months ago, according to NY Times reports.
Red Hat Enterprise
Linux 5 beta starting in July
Beta 1 of the next RHEL server may to be available in late July. The
now-available Fedora Core 5 is viewed as alpha code for RHEL5. Red Hat hopes to
incorporate the next Fedora Core 6 build into its Beta 2, planned for release in
mid September.
RHEL 5 will include the Xen open source virtualization hypervisor -- a key
element of the release and a necessary addition due to Novell's inclusion of Xen
in Suse 10 -- as well as integration with the Red Hat's directory and
certificate servers. It will also offer support for Intel and AMD virtualization
extensions, stateless Linux clients, and single sign-on.
JBoss Unveils OSSw Enterprise Management Strategy with implementation of agent technology
JBoss, now a division of Red Hat, is open sourcing the core systems
management agent in JBoss Operations Network (ON) to create and drive broadened
adoption and collaboration around its open management platform. This
announcement, backed by the JBoss developer and ISV community, provides software
vendors and customers a foundation for building their own management agents,
which will enable interoperability across heterogeneous IT environments.
This strategy is an important step in putting customers in charge of their IT
infrastructures. As a subscription-based offering, JBoss ON delivers dramatic
savings in total cost of ownership (TCO) and provides a holistic environment for
inventory management, administration and configuration, monitoring, software
updates and provisioning of applications based on JBoss Enterprise Middleware
Suite (JEMS). Red Hat is working with other network and systems management
vendors to ensure that management data can be shared with existing customer
management installations. JBoss ON subscribers will also be able to leverage
existing open source agents from projects such as Nagios.
By bringing its JBoss management agent to the open source community, Red Hat
will enable systems to expose its manageability functions in an extendable and
pluggable way - underscoring the company's commitment to support heterogeneous
customer environments. For example, other vendors can extend the agent to manage
their products. As part of its strategy, JBoss will create blueprints,
certification toolkits and methodologies that vendors can use to validate their
extensions and plug into the management process used for JEMS today.
JBoss Releases JBoss Seam 1.0, a Web 2.0 framework for SOA technologies
JBoss also announced the general availability of JBoss Seam 1.0, a new
application framework for Web 2.0 applications that unifies popular
service-oriented architecture (SOA) technologies such as Asynchronous JavaScript
and XML (AJAX), JavaServer Faces (JSF), Enterprise JavaBeans (EJB) 3.0, Java
portlets, business process management (BPM) and workflow. Since its initial
developer release, JBoss Seam has seen strong community interest and has played
a driving role for a new standards initiative for Web Beans through the Java
Community Process (JCP).
Designed to eliminate complexity at the architecture and application
programming interface (API) level, JBoss Seam enables developers to assemble
complex web applications with simple annotated POJOs (plain old Java objects),
componentized UI widgets and simple XML. To accomplish this, JBoss Seam extends
the annotation-driven and configuration-by-exception programming model of EJB
3.0 into the entire web application stack. It bridges the artificial gap between
EJB 3.0 and JSF in the Java Platform Enterprise Edition 5.0 (Java EE 5.0)
architecture. The result is a unifying, tightly integrated application model
that enables stateless, stateful, transactional and process-driven applications
such as workflow and page flow.
Gavin King, founder and project lead of JBoss Seam and founder of Hibernate,
commented: "Enabling the next generation of web development requires a major
reconsideration of the underlying web application architecture. Until EJB 3.0,
that had not been possible. As the first unifying ... framework for SOA
technologies, JBoss Seam offers developers a rapid development environment and
programming model that extends from the simple to the most complex web
applications."
Key features of JBoss Seam 1.0 include:
-- EJB-based development. EJB 3.0 has changed the notion of EJBs as
coarse-grained, heavy-weight objects to EJBs as lightweight POJOs with
fine-grained annotations. In JBoss Seam, everything is an EJB. JBoss Seam
embraces the Web 2.0 concept that the web is the platform, and as such, JBoss
Seam eliminates the distinction between presentation tier components and
business logic components. Even session beans, for example, can be used as JSF
action listeners.
-- AJAX-based remoting layer. JBoss Seam Remoting allows EJB 3.0 session
beans to be called directly from the web browser client via AJAX. The session
beans appear as simple JavaScript objects to the JavaScript developer, hiding
the complexity of XML-based serialization and the XMLHttpRequest API. Web
clients may even subscribe to JMS topics and receive messages published to the
topic as asynchronous notifications.
-- Declarative state management for application state. Currently, Java EE
applications implement state management manually, an approach that results in
bugs and memory leaks when applications fail to clean up session attributes.
JBoss Seam eliminates almost entirely this class of bugs. Declarative state
management is possible because of the rich context model defined by JBoss
Seam.
-- Support for new types of stateful applications. Before Seam, HTTP session
was the only way to manage web application states. JBoss Seam provides multiple
stateful contexts of different granularity. For example, developers can write
web applications with multiple workspaces that behave like a multi-window rich
client.
-- Support for process-driven applications. JBoss Seam integrates transparent
business process management via JBoss jBPM, making it easier than ever to
implement complex workflow and page flow applications. Future versions of JBoss
Seam will allow for the definition of presentation-tier conversation flows by
the same means.
-- Portal integration. JBoss Seam supports JSR-168 compliant portals such as
JBoss Portal.
JBoss Seam 1.0 is free to download and use under the GNU
Lesser General Public License (LGPL). JBoss Seam 1.0 works with any application
server that supports EJB 3.0, including JBoss. For download and additional
information, visit www.jboss.com/products/seam
Webinar Series on Clustering JVM, Tomcat Sessions
Terracotta, Inc., announced a free Webinar series for Java professionals
about the technology and benefits of the company's clustered JVM (Java Virtual
Machine) solutions The series is a response to the market's growing interest in
clustering at the JVM level, instead of at the application level.
Designed for Java developers, architects, and anyone needing fault tolerance
and linear scalability, the webinars will cover all aspects of clustering the
JVM. Highlights will include benefits, new features, installation, usage,
management, demos, and technical Q&As. Webinars will be archived for those
who cannot attend.
The first webinar, on June 28, addressed clustering the JVM with Apache
Tomcat, which Terracotta currently supports. The Panelists included Jim
Jagielski, CTO, Covalent Technologies; Gary Nakamura, vice president,
Terracotta; and Sreeni Iyer, senior manager/field engineer, Terracotta
Terracotta Sessions clusters the JVM, instead of the application, so no
coding or tuning during development is needed while achieving high availability
and linear scalability. Developers can easily replicate sessions to other
servers for high availability, without sacrificing performance. The product is
fee for developers.
Future Webinars will focus on the Spring Framework from
Interface21, which Terracotta will support in Q3, and additional open source
projects that Terracotta will support. Register at : http://www.terracottatech.com/
Improving Make with Mr. Make
If you want to expand your software build repertoire, check out a 4-part
series of practical techniques for enhancing your GNU Make Makefiles. John
Graham-Cumming presents "recipes" for improving your Make-based builds. For
example, Recipe 4 shows how to determine the version of GNU Make in a Makefile,
or if a specific GNU Make feature is available. Recipe 5 performs a recursive
$(wildcard), and Recipe 6 demonstrates tricks for tracing rule execution.
Interested? See: http://cmc.unisfair.com/log_thru.jsp?eid=72
and http://cmc.unisfair.com/index.jsp?id= 755&code=
mrmake [for part 1, use id=844
for part 2 and id=993 for part 3]. The last part will occur in August.
Opera 9 is out [and eWeek likes it]
http://my.opera.com/welcome%20to%209/blog/
http://www.eweek.com/article2/0,1895,1979227,00.asp
http://www.eweek.com/article2/0,1895,1980533,00.asp
New Opera widgets make for small, light-weight applications that execute
locally in the browser. These include calendar and game widgets, currency
converters, etc.
Opera's expanded functionality makes it possible to selectively block content
within a Web site. This can be done with right-clicking on the site page, then
holding down the Shift key and clicking on specific images, ads and other
componentsto be blocked on the next visit.
Quoting from the eWeek review: "A new site-settings feature made it possible
to define controls and settings on a site-by-site basis. So, for example, we
could define how we wanted to deal with pop-ups or cookies on a site.
"Now integrated directly within the Opera browser is a BitTorrent client,
useful for downloading very large files (legal and non-legal). This client
worked very well in our tests, and during downloads of Linux ISO files it
provided good feedback and was very lightweight. However, BitTorrent users
should keep in mind that if you close the browser, the download stops. Many
BitTorrent clients, in contrast, just switch to a minimized mode. "
Here's a full list of new features: http://www.opera.com/products/desktop/
Conferences and Events
- http://use.perl.org
- Dr. Dobb's Architecture & Design World 2006
- July 17-20, Hyatt Regency McCormick Place Conference Center, Chicago, IL
- O'Reilly Open Source Convention 2006
- July 24-28, Portland, OR
- YAPC::EU
- August 30-- 01 September, Birmingham, U.K
- SIGGRAPH 2006
- 7/30 - 8/03, Moscone Center, Boston, MA
- Entertainment Media Expo 2006
- 8/07 - 8/09, Universal City, CA
- LinuxWorld Conference & Expo -- SF
- August 14-17, 2006 -- in foggy San Francisco,
dress warmly!!
- SD Best Practices 2006
- September 11-14, Hynes Convention Center, Boston, MA
- GridWorld 2006
- September 11-14, Convention Center, Washington, DC.
- Digital ID World Conference
- September 11-13, 2006, Santa Clara Marriott, Santa
Clara, CA.
[The Dig-ID Conference sessions are on areas such as: enterprise identity management,
provisioning, strong authentication, federated identity, virtual directories,
smart cards, web services security, identity-based network access control,
enterprise rights management, and trusted computing. I found the 2005 conference
to be most excellent. Further information on Digital ID World 2006, is
here: http://conference.digitalidworld.com/2006/]
Distro news
The latest stable version of the Linux kernel is:
2.6.17.3
[ http://www.kernel.org/pub/linux/kernel/v2.6/patch-2.6.17.3.bz2 ]
Xandros Desktop 4
released
Xandros Corporation has announced immediate
availability of Xandros Desktop 4, a
novice-friendly desktop Linux distribution based on Debian GNU/Linux: "Xandros, the leading provider of easy-to-use Linux alternatives to
Windows desktop and server products, today announced a new line of consumer
desktop products targeting home and multimedia users: Xandros Desktop Home
Edition and Xandros Desktop Home Edition - Premium."
Xandros Desktop Home Editions provide enhanced Windows
compatibility, including enhanced Windows-to-Linux migration
support. This is the first distribution to enable writing to NTFS partitions (the native
file system on Windows computers) from Linux, which allows users to work with the
same files from Linux and Windows.
Announcing Fedora Core 6
Test 1 (5.90)
The Fedora Project announced the first release of the
Fedora Core 6 development cycle, available for the i386, x86_64, and ppc/ppc64
architectures, including Intel based Macintosh computers. Beware that Test
releases are recommended only for Linux experts/enthusiasts or for the
technology evaluation, as many parts are likely to be broken adn the rate of
change is rapid. Test 2 is scheduled for release July 19, marking the
developmental freeze of the Fedora Core 6 release. No new features after this
point. It is important that we get your help in testing, reporting and
suggesting fixes for bugs, and directing the technological improvements we
attempt with this release of Fedora Core.
See info at : http://fedoraproject.org/wiki/Core/Schedule
SimplyMEPIS 6.0 Release Candidate 2 adds Security
The MEPIS team released the second release candidate of
SimplyMEPIS 6.0, on June 21. RC2 adds bug fixes, security updates, and screen
resolution detection, founder and lead developer Warren Woodford said. The
distribution now also includes monitor resolution autodetection.
[Monitor
resolution autodetection] is a feature that has been requested for a long time,"
according to Woodford. "If the user does not specify their desired display
resolution when booting the CD, we attempt to obtain it from the EDID data
returned by the display card, and then the optimum screen resolution is chosen
automatically. Unfortunately there are a lot of monitor-display card
combinations that do not return this data, so this feature will work only for
some users."
A bug was found in RC1 that broke the "install on entire
disk" option, Woodford said, and it has been fixed for RC2. By popular demand,
the apt-notify applet was improved to support transparency in the panel. Firefox
now runs much faster out-of-the-box, due to some configuration improvements
suggested by the community, he added.
RC2 incorporates more security
updates from the Ubuntu Dapper pool, including a security-patched version of the
2.6.15 kernel
SUSE Linux Enterprise Release Candidate 3
Novell has
announced the availability of SUSE Linux Enterprise 10 RC3, both Desktop (SLED)
and Server (SLES) editions, for public testing: "Be among the
first to install, test and enjoy SUSE Linux Enterprise 10. The pre-release
contains all the functionality of the regular release, but is not the final
product. SUSE Linux Enterprise 10 is an open, flexible and secure platform that
is ready to host the applications and databases critical to your business --
from the desktop to the data center, across a wide variety of workloads."
See: http://www.novell.com/linux/preview.html
OpenOffice Security Bulletin [06-29]
OpenOffice.org 2.0.3 fixes three security vulnerabilites that have been found
through internal security audits. Although there are currently no known
exploits, we urge all users of 2.0.x prior to 2.0.2 to upgrade to the new
version or install their vendor's patches accordingly. Patches for users of
OpenOffice.org 1.1.5 will be available shortly. [note: the Macro execution flaw
allows an attacker to get a macro executed even if the user has disabled
document macros.]
The three vulnerabilities involve:
* Java Applets, CVE-2006-2199
* Macro, CVE-2006-2198; and
* File Format, CVE-2006-3117
Security News
"Blue Pill = Security Nightmare"
From Joanna Rutkowska on the 'theinvisiblethings' blog:
"Over the past few months I have been working on a technology code-named Blue
Pill, which is just about that - creating 100% undetectable malware, which is
not based on an obscure concept.
"The idea behind Blue Pill is simple: your operating system swallows the Blue
Pill and it awakes inside the Matrix controlled by the ultra thin Blue Pill
hypervisor. This all happens on-the-fly (i.e. without restarting the system) and
there is no performance penalty and all the devices, like graphics card, are
fully accessible to the operating system, which is now executing inside virtual
machine. This is all possible thanks to the latest virtualization technology
from AMD called SVM/Pacifica."
See the full entry at http://theinvisiblethings.blogspot.com/2006/06/introducing-blue-pill.html
Selected Security NEWS from SANS Institute
--Buffer Overflow Flaw in Opera Browser (23 June
2006)
A buffer overflow flaw that occurs when the Opera web browser processes JPEG
mages could allow remote code execution. The problem is known to exist in Opera
v.8.54 and possibly in earlier versions as well. Users are urged to upgrade to
the new Opera v.9.
http://www.vnunet.com/vnunet/news/2158971/jpeg-flaw-uncovered-opera
--DATA THEFT & LOSS --Lost Memory Stick Holds Phishing Investigation Dossier (26 June 2006)
A police officer with the Australian High Tech Crime Centre (AHTCC) lost a
memory stick that contains sensitive financial data belonging to thousands of
Australians. The lost memory stick holds a dossier on Russian phishing scams.
The data on the stick were being used in an investigation; several arrests were
made with the help of the data, but since the loss of the stick, no arrests have
been made. While officials searched fruitlessly for the memory stick, the people
whose data were compromised were not informed of the loss. The officer who lost
the device violated AHTCC rules regarding data transport. http://australianit.news.com.au/common/print/0,7208,19588463%5E15306%5E%5Enbv%5E,00.html
--Attackers Use SMS Messages to Lure People to Malicious Site (23 June 2006)
A recently detected attack sends intended victims SMS text messages
thanking them for subscribing to an online dating service and telling them
they will be charged US$2 a day until they unsubscribe. When people visit
the site where they are purportedly unsubscribing from the fictitious
service, "they are prompted to download a Trojan horse program." Infected
computers then become part of a botnet. http://www.zdnet.co.uk/print/?TYPE=story&AT=39277240-39020375t-10000025c
--Survey Finds Americans Want Strong Data Security Legislation
A survey from the Cyber Security Industry Alliance (CSIA) of 1,150 US adults
found 71 percent want the federal government to enact legislation to protect
personal data similar to California's data security law. Of that 71 percent, 46
percent said they would consider a political candidate's position on data
security legislation and "have serious or very serious doubts about political
candidates who do not support quick action to improve existing laws." In
addition, half of those surveyedavoid making online purchases due to security
concerns.
http://www.fcw.com/article94613-05-23-06-Web
http://ww6.infoworld.com/products/print_friendly.jsp?link=/article/06/05/23/78609_HNdatapolitics_1.html
--Millions of Blogs Inaccessible Due to DDoS
Attack
A "massive" distributed denial-of-service (DDoS) attack on Six Apart's
blogging services and corporate web site left about 10 million LiveJournal and
TypePad blogs unreachable for hours on Tuesday, May 2.
Six Apart plans to report the attack to authorities.
http://www.zdnet.com.au/news/security/print.htm?TYPE=story&AT=39255176-2000061744t-10000005c
--Soon-to-be-Proposed Digital Copyright
Legislation Would Tighten Restrictions
Despite efforts of computer programmers, tech companies and academics to get
Congress to loosen restrictions imposed by the Digital Millennium Copyright Act
(DMCA), an even more stringent copyright law is expected to be introduced soon.
The Intellectual Property Protection Act of 2006 would make simply trying to
commit copyright infringement a federal crime punishable by up to 10 years in
prison. The bill also proposes changes to the DMCA that would prohibit people
from "making, importing, exporting, obtaining control of or possessing" software
or hardware that can be used to circumvent copyright protection.
http://news.com.com/2102-1028_3-6064016.html?tag=st.util.print
Software and Product News
New Berkeley DB Java Edition 3.0
The new Berkeley DB 3.0 is a high performance, transactional storage engine
written entirely in Java. Like the original, highly successful Berkeley DB
product, Berkeley DB Java Edition executes in the address space of the
application, without the overhead of client/server communication. It stores data
in the application's native format, so no runtime data translation is required.
Berkeley DB Java Edition supports full ACID transactions and recovery. It
provides an easy-to-use, programmatic interface, allowing developers to store
and retrieve information quickly, simply and reliably.
Berkeley DB Java Edition is designed to offer the same benefits of Enterprise
Java Beans 3.0 (EJB3) persistence without the need to translate objects into
tables.
Most persisted object data is never analyzed using ad-hoc SQL queries; it is
usually simply retrieved and reconstituted as Java objects. The overhead of
using a sophisticated analytical storage engine is wasted on this basic task of
object retrieval. The full analytical power of the relational model is not
required to efficiently persist Java objects. In many cases, it is unnecessary
overhead. In contrast, Berkeley DB does not have the overhead of an ad-hoc query
language like SQL, and so does not incur this penalty.
The result is faster storage, lower CPU and memory requirements, and a more
efficient development process. Despite the lack of an ad-hoc query language,
Berkeley DB Java Edition can access Java objects in an ad-hoc manner, and it
does provide transactional data storage and indexed retrieval, as you would
expect from any database. The difference is that it does this in a small,
efficient, and easy-to-manage package. Using the Persistence API, Java
developers can quickly and easily persist and retrieve inter-related groups of
Java objects.
Berkeley DB Java Edition was designed from the ground up in Java. It takes
full advantage of the Java environment. The API provides a Java
Collections-style interface, as well as a programmatic interface similar to the
Berkeley DB API. Its architecture supports high performance and concurrency for
both read- and write-intensive workloads.
Berkeley DB Java Edition is not a relational engine built in Java [like
Derby]. It is a Berkeley DB-style embedded store, with an interface designed for
programmers, not DBAs. The architecture is based on a log-based, no-overwrite
storage system, enabling high concurrency and speed while providing ACID
transactions and record-level locking. Berkeley DB Java Edition efficiently
caches most commonly used data in memory, without exceeding
application-specified limits.
Here's the download link : http://dev.sleepycat.com/downloads/releasehistorybdbje.html
Ajax4jsf Now open
source
Exadel, Inc. has contributed Ajax4jsf as an open source project to Java.Net,
the web-based, open community that facilitates Java technology collaboration in
applied areas of technology and industry solutions.
Exclusively created to bring rich user interface functionality to the
JavaServer Faces (JSF) world, Ajax4jsf is a rich component development framework
that extends the benefits of JSF to AJAX development. Ajax4jsf allows developers
to add AJAX-capability to existing JSF applications, create rich components with
built-in AJAX support, create a slick user interface with Skinning technology,
package Java Script files and other resources together with JSF components, and
test the components functional elements in the process of components
development.
More information about Ajax4jsf can be found at: http://ajax4jsf.dev.java.net
Unisys Announces Open Source 'Oasis' in Enterprise Computing
Unisys Corporation has announced a major expansion of its open source
capabilities with Unisys Open and Secure Integrated Solutions (OASIS), an
integrated, certified set of software suites targeted specifically for
enterprise class computing based on open standards and fully supported through
Unisys global services and vertical-industry solutions capabilities. Combining
technology and services, Unisys open source solutions provide a comprehensive
environment that realizes the full benefits of enterprise computing capitalizing
on the economics of OSSw.
Unisys OASIS and associated services enable clients to take a disciplined,
secure approach to realizing the cost, agility and security advantages that open
source solutions can provide. The Unisys OASIS software suites provide a range
of options, including:
-- Application Server Suites, to migrate proprietary Java Enterprise Edition
environments to open source. Suites include JBoss Application Server, a
custom-tuned Java Virtual Machine for use with Unisys scaleable server
platforms; and Unisys Application Defender, which increases the capability of
Java Web applications in the JBoss environment to withstand attacks by hackers
and other adversaries.
-- Database Server Suites, which integrate and deploy the open source
databases MySQL and PostgreSQL.
-- Solutions for rapid migration to an open source platform, which include
tooling, services and methodology for moving databases and application
servers.
-- Services for developing Unisys 3D Visible Enterprise
(3D-VE) blueprints, which help organizations map their business to the IT
infrastructure, enabling evolution toward a Service Oriented Architecture (SOA).
For additional information on Unisys OASIS, visit http://www.unisys.com/services/open__source.htm
.
BlueCat Networks and Mirage Networks Defend Network Access
BlueCat Networks and Mirage Networks announced that the companies have formed
an alliance to deliver the strongest DHCP-based network access control (NAC)
available. Through this partnership, BlueCat Networks is adding support for
Mirage NAC to its lineup of network appliances. The combined solution will
enable customers to cost-effectively authenticate users and control their access
to network resources.
A recent Gartner report, states "To protect their networks, many network
managers are implementing network access control (NAC), based on technologies
such as 802.1x and Dynamic Host Configuration Protocol (DHCP)." This reflection
of industry requirements and drivers has spurred the development of this
partnership.
BlueCat selected Mirage NAC for its abilities to provide a future-proof
approach that provides security no matter the IP device or operating system. Its
award-winning design offers complete access control by:
-- Addressing policy violations and threats -- even day zero -- at all
points on the network
-- Enforcing DHCP-based authentication for dynamic IP addresses
-- Providing
safe quarantining and mitigation of offending devices
"There are no safe havens in the network: every endpoint, from the network
printer to the VoIP phone to the Windows desktop is vulnerable to threats,"
stated Michael D'Eath, vice president of corporate and business development,
Mirage Networks. "BlueCat is clearly a leader in the IPAM, DNS and DHCP Space.
With this partnership, BlueCat can securely authenticate and attach any
endpoint, managed or unmanaged, to the network, without the need for expensive
switch upgrades, cumbersome client software or reactive signature updates."
The joint solution is available through BlueCat
Networks. Contact BlueCat Networks at www.bluecatnetworks.com
or
1-866-895-6931 for pricing and more information.
Forum Systems Launches Web Services Security Software Development Kit
Forum Systems has released the Forum Java Web Services Security (JWSS)
Software Development Kit (SDK) version 1.0 offering developers a comprehensive
library of application programming interfaces (API's) to leverage in coding Web
Services applications. The JWSS SDK v1.0 addresses the need for security to be
enforced within the application itself in order to ensure privacy and integrity
of Web Services and SOA applications.
Forum JWSS SDK v1.0 allows developers to administer and apply security
policies within J2EE compliant Application Servers using a declarative security
model and API's for XML message authentication and authorization. The
Application Server is then responsible for applying these security constraints
to the code at runtime. Adding XML security within business logic prevents
transactions from bypassing third-party enforcement points that would violate
regulatory compliance or work flow security. Companies should complement this
developer-centric approach with an "interception" model using a SOA Gateway or
XML Firewall within a DMZ (Demilitarized Zone) for a global and scalable SOA
security and acceleration strategy.
"There are business applications in which security must be enforced at the
exact location where information is being processed for privacy reasons," said
Walid Negm, vice president of marketing for Forum Systems. "In certain financial
services and government settings, the origin of messages must be verified at the
point of consumption to ensure that they were not physically intercepted. When
using XML Encryption within the application, Forum's JWSS SDK v1.0 equips the
developer with XML security functionality to decipher and verify the message
contents," Negm added.
Forum Seamless Security Solutions Architecture (Forum S3A) is an adaptive
approach to building security-minded service-oriented applications and
data-level networks using life-cycle solutions including vulnerability
management, testing systems, firewalls and gateways. Forum products are
available as software, PCI-card and appliance options and comply with government
requirements including CheckPoint OPSEC Certification, FIPS Certification,
Common Criteria EAL 4+ (in process) and JITC DoD PKI Certification. Forum
Systems is an active a member of OASIS and WS-I helping mature standards such as
WS-I Basic Profiles, SAML and WS-Security.
Magical Realism... (non-Linux news of general interest)
WOMMA Site Devoted to Word of Mouth Research and
Measurement
The Word of Mouth Marketing Association (WOMMA) has launched the first site
devoted solely to the field of word of mouth (WOM) research. Featuring a new
blog and email newsletter, the WOM Research site is a resource for both
marketers and academics seeking the latest information on word of mouth
measurement and metrics. Everything can be found at
http://www.womma.org/research.
The new site features content designed to introduce WOM research to a wider
audience. In addition to the latest research reports, surveys, and data, the WOM
Research blog also features original contributions from leading academics and
market research experts.
WOMMA has also announced the Word of Mouth Basic Training 2 Conference to be
held on June 20-21 in San Francisco. Measurement and research will form a
significant part of the agenda, with research experts on hand from BIGresearch,
Biz360, Informative, Keller Fay Group, Millward Brown, MotiveQuest, Starcom,
VoodooVox, and Umbria. More details can be found at
http://www.womma.org/wombat2.
As word of mouth marketing has continued to explode into the mainstream
marketing mix, the demand for new resources and data has become essential.
According to eMarketer, 43% of all marketers will incorporate word of mouth into
their marketing programs in 2006.
WOMMA is the official trade association for the word of
mouth marketing industry. Its members are committed to building a prosperous
word of mouth marketing profession based on best practices, measurable ROI, and
ethical leadership. Learn about WOMMA at http://www.womma.org.
World's Record Etch A Sketch Coming to SIGGRAPH 2006
The world's largest Etch A Sketch(R) will make its debut at SIGGRAPH 2006,
the International Conference and Exhibition on Computer Graphics held 30 July to
3 August 2006 in Boston, Massachusetts. SIGGRAPH 2006 will bring an estimated
25,000 computer graphics and interactive technology professionals from six
continents the event.
Officially endorsed by The Ohio Art Company, the installation will be in use
before the curtain rises on the SIGGRAPH Computer Animation Festival - the
world's marquee showplace for the latest and most innovative animation films of
the year.
It allows audience members to control (in real-time) the two famous Etch A
Sketch(R) drawing knobs and use them interactively on the main projection
screen. Functionality will also include the audience's ability to "shake" the
screen clean and start again with a blank canvas.
The SIGGRAPH 2006 Computer Animation Festival features
approximately 100 films and videos by some of the world's most creative
scientists, animators, VFX specialists, educators, studios, and students. For
more information on the Computer Animation Festival,visit: http://www.siggraph.org/s2006/main.php?f=conference&p=caf.
Virtualization Software Allows SPARC Applications to Run on Linux
Transitive Corp recently announced the first two products in its series of
products that are being developed as part of its new Solaris/SPARC Migration
Initiative:
-- QuickTransit for Solaris/SPARC-to-Linux/Xeon and
-- QuickTransit for Solaris/SPARC-to-Linux/Itanium
Transitive Corp previously developed Rosetta which allows Macintosh
applications written for the PowerPC chip to run on the new Intel-based versions
of the Macintosh.
The new products are the first results of the collaboration with Intel
announced in March of this year to accelerate the migration from RISC-based
platforms to Intel-based platforms, and they allow Solaris/SPARC applications to
run without any source code or binary changes on Linux/Xeon- and Linux/Itanium
2-based servers respectively. The products dramatically reduce the barriers IT
organizations face when migrating Solaris/SPARC workloads to Linux/Xeon- and
Linux/Itanium-based servers. Future products will allow SPARC applications to
run on various other hardware platforms.
"One of the biggest obstacles to migrating from one server to another is
getting your internally developed and commercial applications ported to the new
server," said Bob Wiederhold, President and CEO of Transitive Corporation. "In a
large IT organization this can take years to accomplish. Since SPARC
applications can now run on your target platform without the burden of porting,
this migration barrier is eliminated and IT organizations can immediately
realize the full benefits of their new strategic server platform."
Transitive's QuickTransit hardware virtualization products allow SPARC
applications to run with full functionality, including interactive and graphics
performance. The use of QuickTransit is completely transparent to the end-user
and easily managed by IT system administrators. Commercial and in-house software
development teams can easily support their applications with QuickTransit
because no source code or binary changes are required.
Transitive expects to deliver the first product,
QuickTransit for Solaris/SPARC-to-Linux/Xeon, in Q3 2006. The second
product, QuickTransit for Solaris/SPARC-to-Linux/Itanium, is expected to be
available by the end of the year 2006.
AMD to gradually introduce DDR3, FB-DIMM; will be used in next gen Cray supercomputer
In a recent supercomputing win, AMD Opteron processors were selected for a
multi-year contract that Cray, Inc. signed with Oak Ridge National Laboratory
(ORNL) to provide the world's first petaflops-speed (1,000 trillion
floating-point operations/second) supercomputer. The contract calls for
progressive upgrades to ORNL's existing Cray XT3™ supercomputer, starting with
Next-Generation AMD Opteron processors with DDR2 memory, followed by upgrades to
use quad-core AMD Opteron processors, which will be socket compatible. These
upgrades will accelerate peak speed to 250 teraflops (250 trillion
floating-point operations per second), planned in late 2007.
ORNL is then expected to install a next-generation Cray supercomputer in late
2008. This system, currently code-named 'Baker,' is designed to deliver peak
performance of one petaflops, making it roughly three times faster than any
existing computer in the world. All systems provided for in the contract will
utilize current and future versions of the AMD Opteron processor.
At the May Processor Forum, Senior Fellow Chuck Moore described a gradual
process of innovation for AMD multi-core chips. This involved supporting
advanced RAM technology as the price points come down near current DDR2 pricing.
At the presentation, AMD indicated that new architecture products from Intel
will roughly halve the power consumption advantage AMD now enjoys. AMD will add
better power management to keep its lead on future products in the 2007 and 2008
timeframe.
AMD also hopes to improve HyperTransport technology to handle up to 5.2
gigatransfers per second. AMD is encouraging motherboard manufacturers to add
HTX slots that use the high speed data transfers.
AMD has plans to add an on-chip L3 cache, shared by all CPU cores, while
maintaining the localized L2 caches for each core. Depending on its size and the
use of pre-fetch algorithims, this feature would keep CPU cores running longer
between pipleline stalls.
AMD will simplify its product portfolio by dropping the 939 and 754
processors in July and will offer steep discounts of up to 46% to stay ahead of
Intel on chip pricing.
Meanwhile, Intel may have delayed the anticipated shipment of its 'Conroe'
Duo and Extreme processors by up to four days, according to Taiwanese
manufacturers. [ But the delay was not officially confirmed by Intel. ] The
graphics chipsets to support the CPUs will also have a July 27th ship date [and
this may be the cause]. Also, its entry-level Celeron D 360 CPU, now the last
part to use the Pentium 4 NetBurst microarchitecture, will be introduced on
September 1. [So there may be a back-to-school price war in September.]
Wikipedia presents: Alien insults for rookies
http://news.com.com/2061-10786_3-6087132.html?tag=xtra.ml
The next time a Klingon shouts that your mother
has a smooth forehead, you will know how to insult him back, thanks to a
Wikipedia list of fictional expletives — curses and insults from books, TV series
and movies, mainly science fiction and fantasy. [ Check it out at :
http://en.wikipedia.org/wiki/List_of_fictional_expletives]
Free file backup and
synchronization online with MediaMax
Streamload, a leading provider of online digital media services, today
announced Streamload MediaMax 1.5, the latest version of its online media
center. The new Streamload MediaMax service is the first in the online storage
space offering a full suite of media sharing and remote access applications that
include free file backup and file synchronization in one online service.
Streamload MediaMax allows users to easily store, organize, access, and share
their digital media collection . Version 1.5 integrates the management and
sharing of online and offline media by integrating free client software, called
Streamload MediaMax XL, into the Streamload MediaMax service using a drag and
drop window on their desktop. It also automatically performs regular backups of
designated folders from their PC and it synchronizes files across multiple
computers and devices every time new files are added, changed or deleted on
their computer. A benefit of MediaMax's automatic backup and sync is always
having files when and where they are needed without the hassle of manual
uploads.
Users of the service can also invite friends and family to sync folders on
their computers. Without any additional effort, users can automatically share
photos and personal video instantaneously with others who are subscribed to
their synchronized folders.
Streamload MediaMax runs on Windows, Mac OS and Linux. The standard service
is free and comes with 25 GB of online storage. A premium account gives
subscribers 250 GB of storage for $9.95 per month, and the elite subscription
offers 1000 GB for $29.95 per month (when paid annually.) For more information
and to download the free Streamloader desktop software visit
http://www.mediamax.com.
Scientists OK Gore's movie
for accuracy / USA Today
[from -- http://www.usatoday.com/tech/science/2006-06-27-gore-science-truth_x.htm]
The nation's top climate scientists are giving "An Inconvenient Truth", Al
Gore's documentary on global warming, five stars for accuracy.
The former vice president's movie — replete with the prospect of a flooded
New York City, an inundated Florida, more and nastier hurricanes, worsening
droughts, retreating glaciers and disappearing ice sheets — mostly got the
science right, said all 19 climate scientists who had seen the movie or read the
book and answered questions from The Associated Press.
The AP contacted more than 100 top climate researchers by e-mail and phone
for their opinion. Among those contacted were vocal skeptics of climate change
theory. Most scientists had not seen the movie, which is in limited release, or
read the book.
But those who have seen it had the same general impression: Gore conveyed the
science correctly; the world is getting hotter and it is a manmade
catastrophe-in-the-making caused by the burning of fossil fuels.
Talkback: Discuss this article with The Answer Gang
 Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Copyright © 2006, Howard Dyckoff. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006
LG Tips
2-cent tip: Desktop Icon Text Color under KDE
Brian Bilbrey (bilbrey at orbdesigns.com)
Sun Apr 9 14:19:33 PDT 2006
Answered by: Brian, Thomas
Google didn't help. Usually when I go to find these things, Google takes
me to one of my own posts, so I can smack myself around as I gripe that
"I used to know that". Even though I've put myself through this in
prior iterations, I must never have posted it. Now it's time to get this
information out there so that I won't be insane (over this particular
issue) ever again...
Setting KDE's desktop icon text color has always, always made me insane. It's
not in the same place with all the other color settings, oh, no! To set most
item colors in a KDE setup, you use the Control Center, select Appearance &
Themes, then Colors. A simple easy-to-navigate interface for setting almost
every foreground, background and select color under KDE. But if you want to
set Desktop text color ... well, that's not listed. I always end up poking and
prodding for a considerable while. I found it again, today, and wanted to put
it up for me and others to find. So, to set the KDE (versions 3.4 and 3.5, at
least) desktop icon text, from the Control Center select Appearance & Themes.
Choose Background from the sub-menu. Yeah, Background. Who knew? Then, click
on the Advanced Options button. There are three sub-panes in the resulting dialog.
The first, Background Program is usually all I see before bailing out of that
dialog. But keep looking. Further down, there's Background Icon Text. Not Desktop,
oh, no. And that's not to be found in the general color settings tab, for heaven's
sake, no! Now I understand the reasoning behind where it is. But since for all
the rest of the world, that's the Desktop, why not call it that, or make it
easy to find using the Desktop term. And, praise Baal, why not let people change
that text color in the standard tool as well as in the special secret place!
PS: Also "published" on my
own site, on Monday, April 10, 2006. No worries!
[Thomas] - (Quoting Brian) Setting KDE's desktop icon text color has always,
always made me insane.
Hehe. And in FVWM all that would need is one or two colorset definitions
and then:
Style * IconTitleColorset <n>, HilightIconTitleColorset <n>
... never mind, though. :)
[[Brian]] - Yes, I know. And when I get tired and need things simplified, there's
always *box (most often fluxbox). I often don't know why I keep dropping
back to KDE - I think I like the kicker. I know that I use those icons
on the desktop once in a blue moon, and really should just turn off
"Background Icons". That would be another solution to my dilemma.
I even dabble in FVWM from time to time, and have a carefully saved FVWM
configuration someplace safe (safe == well hidden). Find and locate are my
friends, though.
Bottom line, however, was that finding that setting was a PITA, and I'm glad
I did it, and documented it. I also bugged it as a wishlist item with the
KDE team.
2-cent tip: Using two computers with one kbd/mouse
Kapil Hari Paranjape (kapil at imsc.res.in)
Sat Apr 29 20:58:37 PDT 2006
Answered by: Kapil
Hi,
If some of you are unlucky(:)) enough to get confused because you have
two computers on your desktop and you forget which keyboard/mouse is connected
with which computer then this tip may help.
You need to choose "master" which is the computer connected
to the keyboard/mouse you will actually use. You can later put away the mouse
and keyboard of the other computer in order to avoid getting confused. The "master"
must be an X-window machine(*) but the "slave" can be anything.
After you execute these steps and "go west" off the screen
on the master your keyboard and mouse events will be directed at the slave.
(**)
You need to install "x2x" and "x2vnc" on the master.
"slave" is also X-window.
From the slave log in to the master using ssh X forwarding
slave:$ ssh -X luser at master
Then run "x2x" on the master via this ssh session as follows
master:$ x2x -from :0 -to $DISPLAY -west &
Here you replace west with the appropriate direction (west
equals left and north equals up) in which the monitor of the
"slave" is.
"slave" is Linux in "console" mode.
On the slave you run "linuxvnc"
slave:$ linuxvnc &
This will give you a port number (usually 5900) which you
must use below. I'll use 5900 as the port since that is
standard. Next start an ssh tunnel to the master.
slave:$ ssh -f -N -R 5900:localhost:5900 master
Finally on the master you run
master:$ x2vnc -west localhost:0 &
"slave" is "OtherOS".
On the slave you need a VNC server like "WinVNC" for Windows
and "OSXVnc" for Mac OS X. You also need "ssh" unless you allow
the VNC server to accept connections over the net (bad
security). You then follow the same sequence:
(a) start the VNC server on slave
(b) start the ssh tunnel on slave
(c) start x2vnc on master.
(*) I know that I should use the term "machine which is running
an X-server" instead of X-window machine but I hope the nomenclature is
clear enough. (**) There are other options like clicking in a window to switch
the focus but this "trick" of going west seemed the neatest.
Hope this magic helps someone.
[Kapil] - Here is another way to do this---synergy. You can find this at
http://sourceforge.net/projects/synergy2
There are also Debian packages.
The simplest possible config.
On the master you create a file called (say) synergy.conf that contains:
section: screens
center:
lefty:
end
section: links
center:
left = lefty
lefty:
right = center
end
you then run:
synergy -c synergy.conf &
On the slave you run:
ssh -f -N -L 24800:localhost:24800 master
synergyc -n lefty localhost
This is simpler than x2x or x2vnc and the master can also be a machine other than Linux.
2-cent tip: Using your text consoles from remote locations
Kapil Hari Paranjape (kapil at imsc.res.in)
Thu May 4 02:06:29 PDT 2006
Answered by:
Hello,
You may be on an Xsession that has disabled switching to "console"
mode or you may want to access the text console of a remote machine. Whatever
it is two programs may be useful. One is "conspy" and the other is
"linuxvnc".
"conspy":
Say you have access to the machine as root. Login and run
"conspy 1" where you can replace 1 with the number of the
console you want to access (don't try this with the vt on which X is running!).
http://www.stuart.id.au/russell/files/conspy/
"linuxvnc":
Suppose someone with root access on the machine is kind
enough to run "linuxvnc 1" where 1 has the same meaning as above.
You can then connect your favourite vncviewer to "machine:0" and access
the console. http://libvncserver.sourceforge.net/
The latter has some advantages in that anyone can be given access without root
priviledges. The former is distinctly "faster".
2-cent tip: Recording live playback using ALSA
Kapil Hari Paranjape (kapil at imsc.res.in)
Wed May 31 08:57:52 PDT 2006
Answered by:
Hello,
Have you ever felt the urge to record some "live" music while
you are listening to it? The following procedure might do what you want.
Prerequisites: The sound on your computer should use a 1.x release
of the ALSA drivers and you have alsa-lib (Debian's libasound2) installed.
Assumptions: You don't already have a $HOME/.asoundrc file. If you
do, then you need to edit it suitably. You also should not have a
script/program called "recording" :-)
Result: You run "recording -on" to start recording. You then
start your live playback. After you have had enough you stop the live playback.
You then run "recording -off" and are left with a (large) file containing
the recording.
Method:
1. First create a file called "$HOME/.asoundrc" like
the one enclosed.
2. Create the links.
ln -s /dev/null /var/tmp/null.raw
ln -s /var/tmp/null.raw /var/tmp/record.raw
3. Next install the script "recording" somewhere in your
path (download it here.)
4. That's it!
Caveats:
a. This only works for digital live playback through the PCM device
of your soundcard. You can use "arecord" for the other devices since
these can usually be "captured".
b. Don't forget to copy/convert your recording /var/tmp/sound.raw to
a safe location.
c. This only works with audio players that support alsa-lib. To get
it to work with other players like "realplay", install alsa-oss
and use "aoss realplay" instead of "realplay".
d. You usually cannot run "recording -on/-off" while the
player has the audio device open. For many players (in particular those like
(c) above), you must quit the player before and after recording.
e. The supplied .asoundrc converts the incoming audio to CD format.
This may lead to a loss in quality but I prefer it to "guessing" the
real format of the raw data in each case.
2-cent tip: vpac for Vim
Mike Lear (mikeofthenight2003 at yahoo.com)
Tue Jun 6 03:07:02 -0700 PDT 2006
Answered by:
As a Linux and Vim user, I like to use Vim to write programs and
subroutines in various programming languages. I developed 'vpac' as a
series of programming aids for Perl, gcc, g++ and asm, using Vim as the
focal point.
'vpac' and its related files allow you to compile, debug and run programs
all within one Vim session. Another feature is the ability to
comment/uncomment existing code with a single keystoke.
'vpac' works like a global makefile in that you can build several small files
into one executable file. It detects the programming language that you are
using and selects the appropriate compiler/assember. 'vpac' can also carry
out mixed language builds, i.e. c/c++ and asm.
It is easy to use - all the commands are run from function keys.
'vpac' comes as a tar-gzipped
package which includes various 'Howto's and all of the source code.
Regards,
Mike Lear
Talkback: Discuss this article with The Answer Gang
Published in Issue 128 of Linux Gazette, July 2006
How Fonts Interact with the X Server and X Clients
By Thomas Adam
[ The following is taken from a reply the author sent
to TAG in response to a question about fonts. Some of the answers in TAG
are so good that they simply deserve to be made into articles. :) -- Ben ]
Introduction
Behind the scenes, there's a fair amount that happens when an
application requests the use of a font. Because many default
installations include both the X server and their respective clients on
the same machine, a lot of the functionality is masked. However, the
X server plays a pivotal role in managing the fonts stored under
it.
There are usually two different mechanisms at work, as far as fonts
are concerned: one of them makes use of a font server, the other does
not.
Fonts and their location
Taking a typical system that doesn't use a font server, font definitions
are a property of the X server; that is, it knows and keeps track of which
fonts are on your system. X11 defaults to looking for fonts in
/usr/lib/X11/fonts/*.
Typically, a standard definition from /etc/X11/XF86Config-4 (and
newer xorg.conf) files might look like:
Section "Files"
FontPath "unix/:7100" # local font server
# if the local font server has problems, we can fall back on these
FontPath "/usr/lib/X11/fonts/misc"
FontPath "/usr/lib/X11/fonts/cyrillic"
FontPath "/usr/lib/X11/fonts/75dpi/"
FontPath "/usr/lib/X11/fonts/100dpi/"
FontPath "/usr/X11R6/lib/X11/fonts/sgi"
FontPath "/usr/lib/X11/fonts/Type1"
FontPath "/usr/lib/X11/fonts/CID"
FontPath "/usr/lib/X11/fonts/100dpi:unscaled"
FontPath "/usr/lib/X11/fonts/75dpi:unscaled"
An application can request a font to display, and
the X server will obligingly look for it in the hash of directories it
stores (much like the one above). The command 'xset q'
will list that information [1], and indeed font
paths can be added to with 'xset +fp /some/location/'.
However, that does nothing more than append the directory definition.
In order for the X server to become aware of the fact that a new location
has been added, one has to rehash that with 'xset fp rehash'.
Font descriptions
There's a convenience mechanism within X11 fonts, and that is to alias
font names. If we ignore TrueType fonts for the moment, the command
'xlsfonts' lists fonts like this:
-adobe-avant garde gothic-book-o-normal--0-0-0-0-p-0-iso8859-1
-adobe-courier-bold-o-normal--17-120-100-100-m-100-iso10646-1
...
[ Many more lines elided ]
Let's take one of them as an example — here's what each part
does:
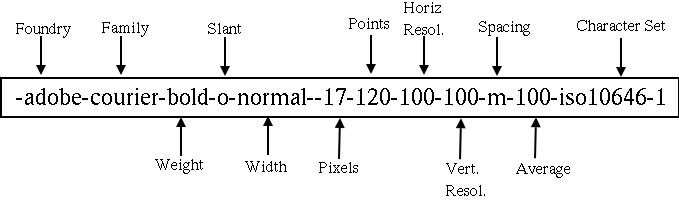
Figure 1: Structure of a typical font.
That's a lot of information, right? Well, yes, it is, but it's
a lot of very useful information. Roughly (and off the top of
my head) here's what each part means:
- Foundry refers to the company that produced the font (Adobe in this case).
- The family refers to the font type.
- The weight is the display of the font (which also includes normal).
- The various pixels and points refer to the size of the font with respect to the resolution of the displayed font (that's horizontal and vertical resolutions.)
- Spacing refers to whether the font is monospaced (m) or proportional (p).
All of this is very dull and boring, and of course it would be a
nightmare if one had to remember all of that information in one go.
This is where aliasing and wildcarding become useful.
Most X11 applications that use the X11 Resource Database (XRDB) allow
various resources to be set with an appropriate font. Example:
*xterm.font: *courier-bold-o-*-120*
That should be pretty self-explanatory, right? That's analogous to the
often used command-line [2] of:
<program> -fn '*courier-bold-o-*-120*'
The X server then has to look up that font, expanding the wildcard as it
goes. This is largely left down to the user to ensure that the correct
placement of any wildcards is accurate, since it will on many occasions
match nothing or unintentional fonts due to it. The X server will traverse
whatever is in its fontpath, in the order the directories are
listed, until a matched font is found. I cannot stress the order
enough — it's analogous to the way a binary is searched for, in one's
$PATH. The first matching font is whatever is found within the list of
fontpaths, even if two or more fonts are matched by the wildcard.
Aliasing is slightly different, in that rather than the user relying
on wildcard matching, a "font.alias" file holds short names for fonts
(alternate names, if you will). Here's a snippet of one:
lucidasans-bolditalic-8 -b&h-lucida-bold-i-normal-sans-11-80-100-100-p-69-iso885 9-1
Essentially, it's a two column file, with the alternate name in column
one, and the actual font name in the second column. As before, if you
use an alias to load a font, the X server will search each font
directory in turn. This has the added benefit of being able to specify
aliases for fonts in other directories.
A fonts.alias file is also associated with a fonts.dir file. You can
think of this file as a massive database that the XServer uses. It's a bit
like font.alias, except that this file lists the following:
Actual Font Name Font Name
When you ask the X server to search for a font, it will look in
fonts.dir to ascertain the font based on either the long name, or the alias
(since the alias is mapped before the fonts.dir is looked in.) If you've
ever used the mkfontdir(1) command, this is what it does — creates
font.dir files in each and every fontpath listed.
Font Servers
Now onto font servers: You don't need them. Really — unless
you're in some large multinational corporation that has hundreds of
workstations connecting to an X server with different vendors. In the R5
release of X11, they were used for uniformity, to ensure that font
names remained consistent, so that applications could load fonts, thus
sharing them. What happens is something like the following:
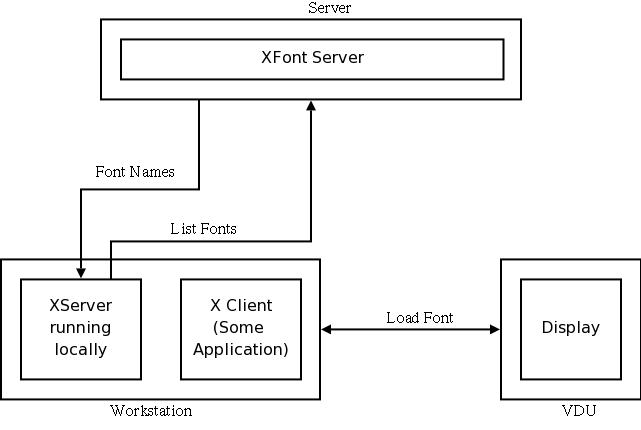
Figure 2: How XFS interacts with the X server and X client(s)
The machine "Server" has a number of services running on it --
including the XFS (X Font Server). The local X server running on a
client is hence told to use a font server (which is typical of the
line):
FontPath "unix/:7100"
The font server responds by supplying the X server on the client with a
list of font names applications (X clients) can load and display on
the screen. (Under the hood there's a lot which goes on, but I'll skip
that.) Note the "role reversal" here [3]: the X server is the client with
respect to the font server — hence it is itself a "font client"
— other examples include a printer, which would also talk to the font
server, where necessary (although not shown in the above diagram).
Old versions of Red Hat used to insist on running a TrueType font
server, for no other reason than presumably to annoy everyone.
[1] Programatically, this can be
achieved via the XSetFontPath() call.
[2] Note the hard quotation marks
here, so as not to perform globbing at the shell.
[3] Rick Moen comments: Unix
newcomers are often confused by the notion of applications being X11
clients and the graphical display being driven by a server process, which
somehow is opposite to people's expectations. They think: surely the
applications are serving up display data, thus making them servers, which
the graphical display is receiving, thus making it a client. However,
what's being served up, to both local applications and remote ones via X11
network access, is the graphical display software's drawing services, as a
central system facility for all applications that need it. Thus the
applications are, for that purpose, clients.
Talkback: Discuss this article with The Answer Gang

I used to write the long-running series "The Linux Weekend Mechanic",
which was started by John Fisk (the founder of Linux Gazette) in 1996 and
continued until 1998. Articles in that format have been intermittent, but
might still continue in the future. I currently write occasional articles
for LG, whilst doing a few things behind the scenes for it. I'm also a
member of The Answer Gang.
I was born in Hammersmith (London UK) in 1983. When I was 13, I moved to
the sleepy, thatched-roofed, village of East Chaldon in the county of Dorset.
It is very near the coast, and Lulworth Cove, which is where I used to work.
Since then I have moved to Southampton, and currently attend University
there, studying for a degree in Software Engineering.
I first got interested in Linux in 1996 having seen a review of it in a
magazine (Slackware 2.0). I was fed up with the instability that the then-new
operating system Win95 had and so I decided to give it a go.
Slackware 2.0 was great. I have been a massive Linux enthusiast ever
since. I ended up with running SuSE on both my desktop and laptop
computers. Although I now use Debian as my primary operating system.
I am actively involved with the FVWM
project, writing documentation, providing user-support, writing ad-hoc and
somewhat esoteric patches for it.
Other hobbies include reading. I especially enjoy reading plays (Henrik
Ibsen, Chekhov, George Bernard Shaw), and I also enjoy literature (Edgar Allan
Poe, Charles Dickens, Jane Austen to name but a few).
I am also a keen musician. I play the piano in my spare time.
Some would consider me an arctophile (teddy bear collector).
I listen to a
variety of music.
Copyright © 2006, Thomas Adam. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006
Creating a Rudimentary Kiosk System using FVWM
By Thomas Adam
Introduction
It is always interesting to see how and where Linux is used within the
wider community, especially where the general public are concerned.
Indeed, it is quite often the case for public libraries to use a batch of
computer terminals to offer a portal via their own intranet so that they
can do searches for books, renew overdue books, etc.
However, ensuring that those terminals only provide that specific
service can be something of a challenge. Because they're public-facing
terminals, their functionality is likely to be limited to a specific subset
of the available applications. Ensuring that these applications are the
only ones the user of the terminal sees, along with making sure that no
other application is accessible unless it's explicitly needed in such a way
that it doesn't break the system can be an interesting task, to say the
least.
This is where some sort of kiosk comes into play. Note that
the concept is nothing
new, although the current HOWTO on the issue is somewhat out of date.
FVWM, which is mentioned in the above HOWTO, has advanced a lot since it
was written. Of course, since then, desktop environments such as KDE have
also had a kiosk extension added to them.
This article will focus on using Firefox as the main and only
application the user will be using. By using FVWM to manage this
application, it is possible to provide restrictions not only on the
application, but also the environment the user will be using.
The motivation for this article is mostly derived from a series of
e-mails I have been exchanging with someone who seems to be trying to setup
a kiosk system in a corporate environment. The actual content of the e-mail
that turned into this article (as a very odd coincidence) is born out of an
e-mail from another TAG member, who asked the same question.
Originally, I had planned to discuss how to lock down Firefox. While
this is applicable within the context of this article, it's also somewhat
less restrictive, given that different people require different
circumstances. Firefox itself has a series of extensions dedicated
to kiosk browsing that you can further use to lock Firefox down. This
article will concentrate on getting a window manager (FVWM) to do the rest
of the work.
Preliminaries
In the best case, what you'll probably want to do is something like the
following:
- Run the application maximized
- Possibly remove window decorations (run full-screen)
- Ensure that Firefox is the only application running
- Ensure that's the only application that can be run
From first principles, here's what your ~/.fvwm/config file ought
to contain. Note that any decoration changes for this are out of
scope for this article; if you don't like hideous pink borders, change
them. (I'm going to suggest FVWM version >=2.5.16; anything I
write here won't work on FVWM 2.4.X).
Enter FVWM
StartFunction is a function that FVWM runs at both restarts and init.
So, in this, all that's needed is to start your application. Since there
are some crude preventative measures one can take to ensure this
application doesn't die once the WM has loaded, we'll just start this at
init time.
DestroyFunc StartFunction
AddToFunc StartFunction
+ I Test (Init) Exec exec firefox
That's that, all taken care of. Next thing to consider is whether you
want any window decorations or not, for Firefox. Let's assume for the
moment that you do want the title and borders, but want to restrict the
buttons that appear on the title. That's fine; just set a style line for
it:
Style Firefox-bin NoButton 1, NoButton 2, NoButton 4, ResizeHintOverride
NoButton removes a button from being displayed in the title.
ResizeHintOverride makes those column-dependent aware applications
not worry about it. The number buttons are ordered thus, on a titlebar:
+----------------------------------------------------------+
| . . . . . . . . . . |
+----------------------------------------------------------+
| 1 3 5 7 9 10 8 6 4 2 |
| |
Typically (and as is the default), buttons 1, 2, and 4 are defined for
normal operations of displaying a menu (button 1) and minimising and
maximising an application (buttons 4 and 2 respectively).
The next thing to do is remove any possible mouse bindings on the
title bar that could disrupt its operation, or that could cause some
arbitrary operation to be performed on it. This also includes bindings
for both the frame and the sides of the window.
Mouse 1 SF A -
Mouse 1 T A -
Mouse 2 SF A -
Mouse 2 T A -
That's just an example. You ought to do the same for key bindings,
although by default FVWM defines no key bindings other than bringing
up a popup menu.
So what happens once the application starts? You'll presumably want it
maximised. Read the FvwmEvent article for
details of this. Essentially, the following could be used:
DestroyModuleConfig FE-SM: *
*FE-SM: Cmd Function
*FE-SM: add_window StartFirefoxMaximised
Module FvwmEvent FE-SM
That sets up FvwmEvent using a module alias of 'FE-SM'. It's listening
for the add_window event, and hence will call the
'StartFirefoxMaximised' when any new window is mapped. As for what
StartFirefoxMaximised looks like:
DestroyFunc StartFirefoxMaximised
AddToFunc StartFirefoxMaximised
+ I ThisWindow (Firefox-bin, !Maximized) Maximize
The function says that if the window mapped matches
"Firefox-bin" as either its window name, class, or resource (class in
this case), and it is not maximised, to maximise it.
And that's it, right? Pffft, if only. What if, by some means unknown
to us, the window were un-maximised? That's not something we probably want
within this kiosk environment, much less allowing the window to be moved
once it has been maximised. That's OK, since we can restrict this. You
might think it's a simple case of adding to the style definition we defined
for Firefox earlier:
Style firefox NoButton 1, NoButton 2, NoButton 4, FixedSize, FixedPosition, !Maximizable
But that's not quite true. What happens here is that the style
preferences are applied before the add_window event is triggered. Whilst
it is true that "FixedSize" and "FixedPosition" do exactly what we want
(i.e., doesn't allow resizing, or moving the window, or not allowing the
window to become un-maximized, respectively), we have to apply it
afterwards. This is where the WindowStyle command can be
used.
The WindowStyle command works like Style, except that it pertains to a
specific window currently mapped and visible. Under the hood, it just
assigns various struct events via the window's WindowId, but that's out of
scope, here. Hence in the StartFirefoxMaximised function, we can now
expand upon this further:
DestroyFunc StartFirefoxMaximised
AddToFunc StartFirefoxMaximised
+ I ThisWindow (Firefox-bin, !Maximized) Maximize
+ I ThisWindow WindowStyle FixedSize, FixedPosition, !Maximizable
+ I UpdateStyles
I mentioned earlier that you may or may not want any window
decorations. If that's the case, then you can do the following
to turn them off:
Style firefox !Title, !Borders, HandleWidth 0, BorderWidth 0
That's a bit better, right? Well, maybe. There's still a few other
considerations that should be taken into account. When a window is
mapped, it is put into a layer (layer 4 by default, which can be changed
using the DefaultLayers command). This is fine, but means
some windows can cover up this window. This is unlikely to happen
here, given that it's unlikely you're going to be running any other
application, but, for the theoretical concept alone, it's best to
perhaps put this window into a much higher layer than normal.
Style Firefox-bin NoButton 1, NoButton 2, NoButton 4, Layer 8
FVWM (like several other window managers) has virtual desktops. Wooo.
You aren't going to need them here, so ditch them. You can do this using
the DesktopSize command, and perhaps the DesktopName
command , to define how many desks you want.
DesktopSize 1x1
DesktopName Main
Hence the DesktopSize command restricts us to one page defining a single
desk, whose name is "Main". I also alluded to earlier ensuring that you
turn off all mouse bindings. This is also true of the root window that
might bring up any menus.
Mouse 1 R A -
Mouse 0 R A -
Mouse 2 R A -
Again, it's unlikely to much of an issue, given the application runs in
some sort of full screen mode, but it's better to cover one's bases than
not at all.
There are two more things that need mentioning. Ensuring that the
Firefox window is the only running instance can be a little tricky.
We could prepend some stuff to the StartFirefoxMaximised function to
try and enforce such a policy.
DestroyFunc StartFirefoxMaximised
AddToFunc StartFirefoxMaximised
+ I ThisWindow (!Firefox-bin) Close
+ I ThisWindow (Firefox-bin, !Maximized, !Transient) Maximize
+ I TestRc (Match) ThisWindow WindowStyle FixedSize, FixedPosition, !Maximizable
+ I UpdateStyles
...although that may or may not be overkill for some purposes. It might
be the case, of course, that you only want to allow a certain subset of
applications to run. This would presumably be via Firefox itself
(perhaps some filetypes spawn mplayer or RealPlayer), hence you could
expand upon StartFirefoxMaximised even more.
DestroyFunc StartFirefoxMaximised
AddToFunc StartFirefoxMaximised
+ I ThisWindow (!"App1|App2|App3|App4") Close
+ I ThisWindow (Firefox-bin, !Maximized) Maximize
+ I ThisWindow WindowStyle FixedSize, FixedPosition, !Maximizable
+ I UpdateStyles
'ThisWindow (!"App1|App2|App3|App4") Close' says something like the
following: "If the window just created is not one of App1
or App2 or App3 or App4, then close it." Thus,
in this way, one can conditionally place restrictions.
One final consideration. How do you ensure that the Firefox window is
never closed? Well, FVWM has a style consideration "!Closable" that when
applied means the application cannot be closed... almost. It only goes as
far as trying to circumvent the various events generated. It does not,
for example, stop xkill closing the application, or for some external
source to do so.
You could use some sort of script to monitor whether the application is
still running (which assumes this script also runs Firefox).
#!/bin/sh
firefox &
ffpid=$!
while sleep 60; do
[ kill -0 $ffpid ] || {
# Spawn firefox
firefox &
break
}
done
But that's far from ideal. You might be better off using FvwmEvent to
monitor when windows are closed, and to respawn them as apropos. Hence
adding to the "FE-SM" definition from earlier.
*FE-SM: destroy_window CheckWindowClosed
Tells that module alias to now also listen for any windows closing and
take action. The function CheckWindowClosed might look like
this.
DestroyFunc CheckWindowClosed
AddToFunc CheckWindowClosed
+ I ThisWindow (Firefox-bin) Exec exec firefox
That works, right? Well, yes it does. But what if there were more
than one instance of Firefox running? What if we wanted to respawn
this application only if the last remaining instance of this
application died? That's no problem:
DestroyFunc CheckWindowClosed
AddToFunc CheckWindowClosed
+ I None (Firefox-bin) Exec exec firefox
None will only work if there's no instances of the matched
window being asked for — in this case, "Firefox-bin".
Conclusion
Some may argue that the use of a window manager is in itself
overkill, given that one could easily dispense with using one, and
just start Firefox in fullscreen mode as soon as X11 is logged into.
However, that's potentially disastrous, given that the windows aren't
controlled. A transient window (such as an open dialogue box)
wouldn't be managed — if it were opened in an awkward place on the
screen, there's be no way of moving it. Neither, of course, does not
using a window manager preclude the possibility of closing other
windows (applications) down that don't ultimately belong there.
In short, there is no real solution or easy answer to creating a
true kiosk system. At best it can simply be managed by enforcing
certain rules specific to its environment.
Talkback: Discuss this article with The Answer Gang
I used to write the long-running series "The Linux Weekend Mechanic",
which was started by John Fisk (the founder of Linux Gazette) in 1996 and
continued until 1998. Articles in that format have been intermittent, but
might still continue in the future. I currently write occasional articles
for LG, whilst doing a few things behind the scenes for it. I'm also a
member of The Answer Gang.
I was born in Hammersmith (London UK) in 1983. When I was 13, I moved to
the sleepy, thatched-roofed, village of East Chaldon in the county of Dorset.
It is very near the coast, and Lulworth Cove, which is where I used to work.
Since then I have moved to Southampton, and currently attend University
there, studying for a degree in Software Engineering.
I first got interested in Linux in 1996 having seen a review of it in a
magazine (Slackware 2.0). I was fed up with the instability that the then-new
operating system Win95 had and so I decided to give it a go.
Slackware 2.0 was great. I have been a massive Linux enthusiast ever
since. I ended up with running SuSE on both my desktop and laptop
computers. Although I now use Debian as my primary operating system.
I am actively involved with the FVWM
project, writing documentation, providing user-support, writing ad-hoc and
somewhat esoteric patches for it.
Other hobbies include reading. I especially enjoy reading plays (Henrik
Ibsen, Chekhov, George Bernard Shaw), and I also enjoy literature (Edgar Allan
Poe, Charles Dickens, Jane Austen to name but a few).
I am also a keen musician. I play the piano in my spare time.
Some would consider me an arctophile (teddy bear collector).
I listen to a
variety of music.
Copyright © 2006, Thomas Adam. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006
A Brief Introduction to VMware Player
By Edgar Howell
The other day on the way home from work, between the streetcar
and the bus, I spent a couple of minutes at the train station
bookstore, and picked up a magazine with a DVD containing 10 new
"Linux-PCs". Hmmmm...
After getting off the bus, but before I had a chance to
complete the walk home, it began to rain. That ruined all hopes
of being able to mow the lawn... so I decided to investigate the
DVD, instead.
As it turned out, it contained VMware Player and 10 virtual
machines, or VMs: Damn Small Linux, Fedora Core 4, Pocketlinux,
and so on. It was beginning to look as if the weekend would have
some sunshine, after all!
Just What Is VMware?
For those not familiar with virtualization in general, or
VMware in particular, virtualization has been around in the
mainframe world for some 30-odd years. It enables effectively
simultaneous execution of more than one instance of operating
systems — including, in the case of VMware, ones that would
not normally even be able to execute on the physically available
hardware. This is a remarkable accomplishment that requires
convincing the operating system that it really has sole ownership
of the hardware environment it requires.
This unfairly terse description falls horribly short of doing
justice to the amazing feat - but there is no shortage of
far more detailed
descriptions on the Internet.
Installation
As usual, the first step is to install VMware Player. Well
organized by VMware, installation was a real no-brainer.
I did read the prompts and consider the responses, but wound up
just accepting the defaults offered by the installation
script.
Perhaps it was an idiosyncrasy of the particular magazine that
I picked up (it actually addresses users of Wimp/OS), but they
had used a compression program I neither had nor had ever heard
of. No problem - it was available at SourceForge, and just needed
to be installed.
[ '7zip' is actually not a Wind0ws-centric
program at all; it's been available for Linux for quite a while
now. To quote Debian's package listing, "7-Zip is the
file archiver that archives with the highest compression ratios.
The program supports 7z (that implements LZMA compression
algorithm), ZIP, Zip64, CAB, RAR, ARJ, GZIP, BZIP2, TAR, CPIO,
RPM and DEB formats. Compression ratios with the new 7z format
are 30 to 50% better than ratios with the ZIP format."
Good stuff, in other words... except that their RAR compressor
is non-free. -- Ben ]
web@linux:~/vm> cp /media/usbdisk_1/p7zip_4.39_x86_linux_bin.tar.bz2 .
web@linux:~/vm> ls
p7zip_4.39_x86_linux_bin.tar.bz2
web@linux:~/vm> bunzip2 p7zip_4.39_x86_linux_bin.tar.bz2
web@linux:~/vm> ls
p7zip_4.39_x86_linux_bin.tar
web@linux:~/vm> tar xf p7zip_4.39_x86_linux_bin.tar
web@linux:~/vm> ls p7zip_4.39
bin ChangeLog contrib DOCS install.sh man1 README TODO
web@linux:~/vm> ls p7zip_4.39/bin
7z 7za 7zCon.sfx 7zr Codecs Formats
web@linux:~/vm> cp p7zip_4.39/bin/7za .
web@linux:~/vm> l
total 8360
drwxr-xr-x 3 web users 4096 2006-05-20 17:24 ./
drwxr-xr-x 15 web users 4096 2006-05-20 17:20 ../
-rwxr-xr-x 1 web users 1198328 2006-05-20 17:24 7za*
drwxr-xr-x 6 web users 4096 2006-05-20 17:24 p7zip_4.39/
-rwxr-xr-x 1 web users 7331840 2006-05-20 17:23 p7zip_4.39_x86_linux_bin.tar*
web@linux:~/vm>
After that, installation of the VMs was quite
straight-forward.
web@linux:~/vm> cp /media/dvd/ubuntu/computer/pc_gratis/dsl-linux.exe .
web@linux:~/vm> ./7za x dsl-linux.exe
7-Zip (A) 4.39 beta Copyright (c) 1999-2006 Igor Pavlov 2006-04-13
p7zip Version 4.39 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,1 CPU)
Processing archive: dsl-linux.exe
Extracting dsl-linux
Extracting dsl-linux/nvram
Extracting dsl-linux/dsl-test-250.vmdk
Extracting dsl-linux/other24xlinux.vmx
Everything is Ok
web@linux:~/vm>
Now, VMware Player was fully functional and could execute the
available VMs.
Using Virtual Machines
Under SUSE with KDE, click on the panel icon for K Menu, then
'System' -> 'More Programs' -> 'VMware
Player'.
Navigation is not particularly challenging. As a first test, I
chose Damn Small Linux from the 'vm' directory.
Solitaire is a bit sluggish on this 2.6 GHz Celeron(tm), but
bearable. In any case, the following definitely isn't
SUSE!
When the bottom line shows "To grab input, press Ctrl+G", you
can move the cursor over the window as usual. Once you press
Ctrl+G, the cursor belongs to that window, and it is necessary to
press Ctrl+Alt to effectively de-activate that window and free
the cursor. Ctrl-Alt-F2 and the like still work as usual.
At this point, I halted the VM and shut VMware Player down.
Then, I rebooted the hardware. Upon restarting this VM, the
former status was restored:
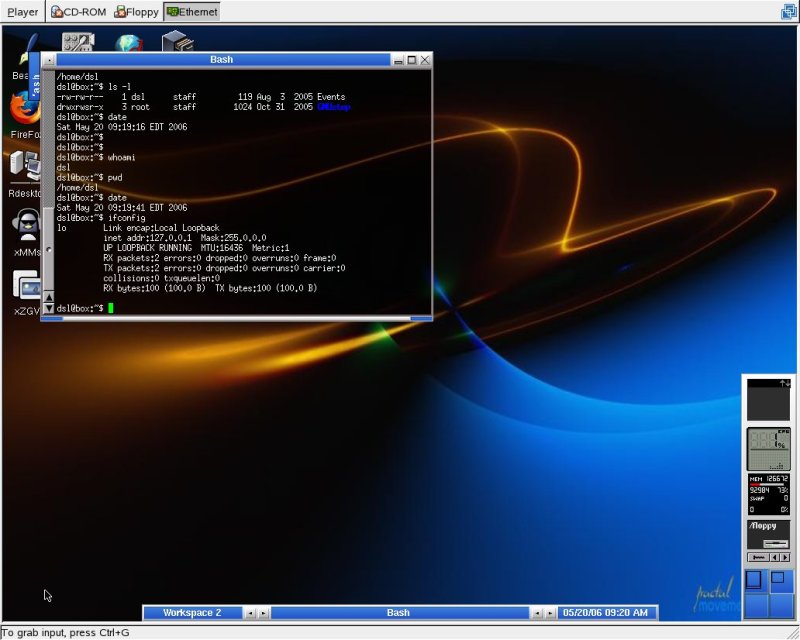
Before re-starting VMware Player, I also added another couple
of VMs. The following looks interesting for this long-time SUSE
user, at least:
Indeed, after logon:
And for the skeptics in the crowd, yes, both are active at the
same time:
The initial boot of a VM takes quite a while, just as does
booting hardware. On the other hand, restarting a VM that has
been active for a while is extremely fast.
Activating the network was no problem at all. In each of two
VMs, after a right-click on the "Ethernet" button, I selected
"host-only" and then assigned IP-addresses as in "ifconfig eth0
172.16.48.130 up". After that, ping worked as
expected:
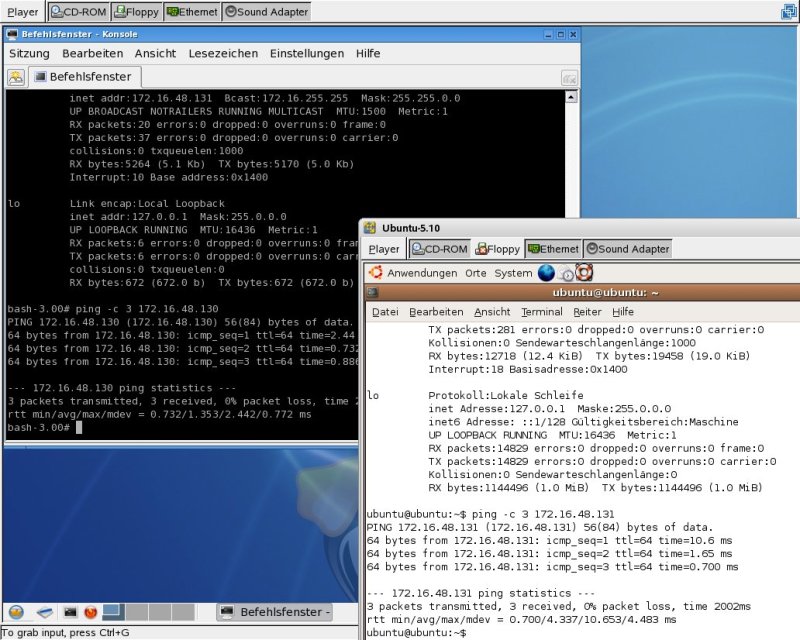
Sharing Hardware
VMware Player seems to share the hardware with the native
operating system quite well. While using Midnight Commander under
SUSE to copy VMs from the DVD into the appropriate directory, I
started Ubuntu under VMware, and it discovered the DVD drive and
went into update mode (synaptic). That slowed down the copying
considerably, but it worked just fine.
It is interesting that there is almost no limit to the number
of VMs available. VMware doesn't use partitions; each VM exists
within its own directory. I renamed the Ubuntu directory and
unpacked it again, creating a clone. When the renamed VM was
started, it came up with the status at the point where it had
been shutdown. The new VM went through the usual (simulated)
hardware boot.
The SUSE VM is 10.0, which is my most-current version. After
placing the distribution DVD in the drive and clicking on the
"CD-ROM" button, there was no problem using YaST to add software
to the VM. Although VMware Player doesn't support creating new
VMs, they clearly can be updated. Since YaST uses RPMs,
installing one ought to work, and I would expect that to be the
case for a tarball, as well.
Finite Resources
But don't get over-confident in starting VMs! At least
my resources are finite:
Networking
After assigning an appropriate IP-address such that the Ubuntu
VM was on the same sub-net as the network printer, it was
possible to ping it. Similarly for the notebook, manually
assigned IP-address 192.168.0.100. This required using the
"Ethernet" button to change the status of the network from
"host-only" to "bridged".
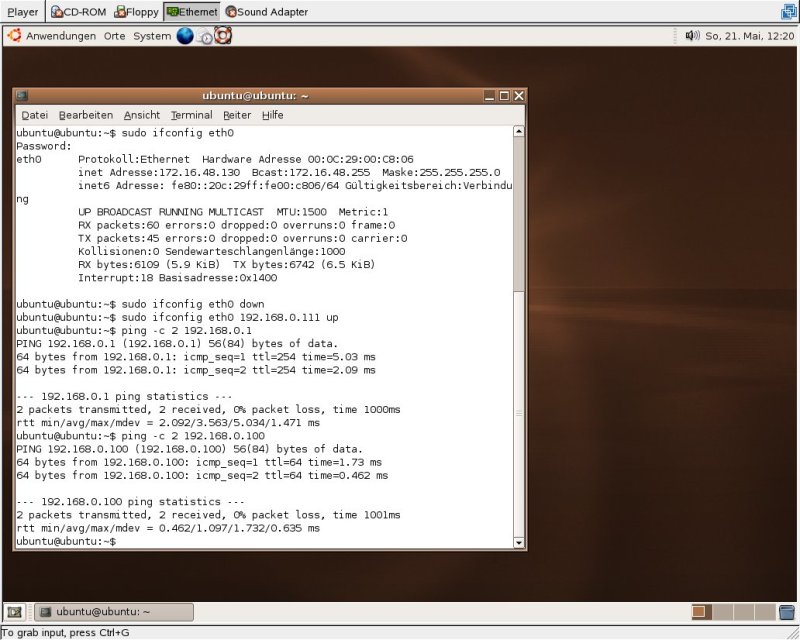
There was no trouble using SSH to log onto the notebook from
Ubuntu, or the other way around, although this of course required
using the ad-hoc IP-addresses rather than host names.
Why Bother?
Some time ago, when I mentioned to someone that I was
interested in checking out virtualization on a PC, his response
was "Why?" Wow, someone even more skeptical than I am! But the
question is certainly legitimate.
Typically the "traditional" reason to use virtualization in
this environment has been consolidation of servers, as in a
server farm that has lots of hardware idle most of the time.
Particularly if hosting for customers who may be competitors,
virtualization provides clean separation of VMs as opposed to
simply providing service for many customers on one machine.
However, I don't have a server farm in need of consolidation
in the office at home, and I doubt that most readers do either.
However, if you think about it, this can be a very interesting
technology, although certainly not of use to everybody.
As you saw above, given available VMs, it is essentially
trivial to make an unfamiliar environment available in a
non-trivial way. As a long-time SUSE user, I'm not at all
familiar with GNOME. Disparaging comments by others
notwithstanding, I am interested in playing around with GNOME,
which is very different from what I am used to.
Indeed, this environment should be ideal for both teachers and
students. One of the things that I really appreciate about
GNU/Linux is the ability to learn new things at my own pace, at
home, when I have the time and at no or minimal expense. Without
a great deal of effort on my part, I can now get familiar with
several distributions I might never have had the time for.
Someone teaching a course could set up a series of exercises
for his students, and just needs to copy a handful of VMs onto
CD-ROM. This would be very effective for a course on some Linux
distribution, particularly if the students have only Wimp/OS at
home.
Or consider the need to do regression tests. The fact that
every VM restarts at the point it had been shut down would be
extremely nice for testing. Set up initial conditions and save
the directory to ensure that every test later run actually is
testing the same thing, unaffected by any side-effects of
something else run between tests.
Philosophy 101
To those who might object to VMware's proprietary business
model, I would reply that it is another tool on the market, and,
from my perspective as a consultant, I like having it in my
toolbox. Very many years ago, on a job-interview, I had to admit
that I didn't yet have any experience with one particular
package. Someone else got that job. Made sense then, makes sense
today. Do you want to be the one to say "I can learn that"? How
about "Been there, done that"?
In my opinion, virtualization is going to be very important,
very soon. I am really looking forward to my first machine with
Vanderpool or Pacifica technology.
Conclusion
This "brief" introduction comes nowhere near doing justice to
the accomplishment of VMware. It can be installed under Wimp/OS
to run GNU/Linux or the other way around (if your proprietary
EULA license gives you access to or permits your producing the
appropriate VM). Or merely to isolate a test-bed from a
production environment, as in the above.
There were problems, but not all of them were due to the
product. Likely attributable to VMware are problems with reboot
and date/time, although it might be argued that these are not
bugs but features. Using "reboot" or "shutdown -r now" returns
the VM to single-user mode. I couldn't figure out how to get
"startx --:1" under SUSE to do any good. And after having used
VMware's "Quit" button to shut down a VM for a couple of days, on
restart it has the date and time of shutdown. Well, in some
scenarios that does make sense.
VMware certainly does require significant resources. The
version of Solitaire that comes with SUSE will finish a game
automatically if told to try; natively, on a notebook with 1 GB
of memory, it moves about 5 cards per second. Under VMware,
however, it takes about 2 seconds per card. ping can take so long
that it seems to have hung: in spite of reporting 0.352 ms, the
wall-clock time was closer to 10 seconds!
This is not the responsibility of VMware, but my PC has only
512 MB - which sure seemed like a lot at the time. Two instances
of Ubuntu can be started in that, but their response times are
egregiously slow. A third instance fails due to lack of
memory.
A general problem with an environment where several different
systems can be played with is inexperience with each, by
definition (again, not relevant to VMware specifically.) It took
frustratingly long to find a command line with GNOME. Although
Ubuntu claimed to be using a German keyboard, it wasn't and I
couldn't convince it to do so — but, then, SUSE with the
same problem was difficult, because SaX2 wouldn't execute
consistently.
If the VM available to you doesn't correspond to your
hardware, you might be in trouble. Given appropriate distribution
media, it is possible to update software. However, what if the VM
doesn't even know about DVDs or writing to CD? Well, there's
always networking out to the native operating system.
Nonetheless, never was it so easy -- without having to worry
about repartitioning or zapping the MBR -- to get so many
different operating systems functional on one machine, not only
without their getting in each other's way but able to co-operate
with each other.
Talkback: Discuss this article with The Answer Gang
Edgar is a consultant in the Cologne/Bonn area in Germany.
His day job involves helping a customer with payroll, maintaining
ancient IBM Assembler programs, some occasional COBOL, and
otherwise using QMF, PL/1 and DB/2 under MVS.
(Note: mail that does not contain "linuxgazette" in the subject will be
rejected.)
Copyright © 2006, Edgar Howell. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006
Subversion: Installation, Configuration — Tips and Tricks
By Muthaiah Ramanathan
Introduction
This article is about installing and configuring Subversion v. 1.3.x;
the installation was performed under Fedora Core 4, but should not be very
different under other distributions. This article will not touch upon the
usual subjects — i.e., where to download Subversion and what
distro-specific commands should be used to install and configure this open
source version control system.
To the novice/beginner, Subversion is a version control tool
from the free/open-source world, designed to replace (and
completely take over) the old horse, CVS. We will not be delving
in-depth into how and why Subversion works the way it is working
currently, and that is not the objective of this article.
Multiple Subversion(s)
Using system commands, check whether you already have
Subversion installed. If so, verify the version before proceeding
to install the latest. It is quite possible to have multiple
versions installed in the same system.
Multiple Subversions — v. 1.2.3 and v. 1.3.0 — are
installed in this system, for example:
[ram@lemuria ~]$ whereis svnversion
svnversion: /usr/bin/svnversion /usr/local/bin/svnversion /usr/share/man/man1/svnversion.1.gz
[ram@lemuria ~]$ /usr/bin/svnversion --version
svnversion, version 1.2.3 (r15833)
compiled Aug 26 2005, 03:42:45
Copyright (C) 2000-2005 CollabNet.
Subversion is open source software, see http://subversion.tigris.org/
This product includes software developed by CollabNet (http://www.Collab.Net/).
[ram@lemuria ~]$ /usr/local/bin/svnversion --version
svnversion, version 1.3.0 (r17949)
compiled May 20 2006, 23:55:41
Copyright (C) 2000-2005 CollabNet.
Subversion is open source software, see http://subversion.tigris.org/
This product includes software developed by CollabNet (http://www.Collab.Net/).
Pre-Installation Checks
Subversion repository storage can be based on any one of the
following:
- FSFS-based repository storage
- Berkeley DB-based storage
At the time of creating the repository, the user has the choice of
using either one of the storage types to hold the repository. By
default, the storage type is FSFS enabled. [1]
With Subversion, access to the repository also has multiple
choices, which can be any one among the following:
- local file-system access,
- HTTP-based access, and,
- secure shell-based access.
How does one know for which mode of "repository access"
Subversion has been configured/installed? To see the answer,
run the following command:
svn --version
On my system, the output from the above command looks like this:
[ram@localhost ~]$ svn --version
svn, version 1.3.1 (r19032)
compiled Apr 4 2006, 06:38:16
Copyright (C) 2000-2006 CollabNet.
Subversion is open source software, see http://subversion.tigris.org/
This product includes software developed by CollabNet (http://www.Collab.Net/).
The following repository access (RA) modules are available:
* ra_dav : Module for accessing a repository via WebDAV (DeltaV) protocol.
- handles 'http' scheme
- handles 'https' scheme
* ra_svn : Module for accessing a repository using the svn network protocol.
- handles 'svn' scheme
* ra_local : Module for accessing a repository on local disk.
- handles 'file' scheme
Q&A: Before Installing Subversion
Take time and try to find the answers to the following questions
before proceeding to install and configure Subversion.
- Type of repository access required: file-system, SSH,
HTTP.
- Restrictions on repositories: open-to-all, restrictive
access with special groups for each repository, etc.
- Version of Subversion to be used, along with version of
one's "httpd" server.
Whatever your answers, always create one special/common
Subversion group ("svnusers") to which users can be assigned; to
these users, Subversion repositories can be opened-up for access.
(For example, with the common group, the repository could be a
play area/scratch pad sort of setup, where "everyone" can
practise Subversion and familiarise themselves with the
tool.)
The next task is to create a special user ("apache") for
running the "httpd" server. This user can be added to that
special/common group created for the needs of Subversion.
On my system, the results look like this:
[ram@localhost ~]$ grep apache /etc/passwd
apache:x:48:48:Apache:/var/www:/sbin/nologin
[ram@localhost ~]$ grep svn /etc/group
svnusers:x:501:ram,apache,root
NOTE: The "apache" user is part of the "svnusers" group, but
can be configured in such a way as to have two special groups for
Subversion — one group for those that access the repositories
via "http" and another for access via "file-system".
One final word on Web server "httpd". Always install the
"httpd" server first, before Subversion. Subversion
is built on APR (Apache Portable Runtime) libraries, which provide
all the interfaces that Subversion requires for its basic
functionalities on different OSes, like disk access, network
access, memory management, etc.
Subversion with Apache
Pre-Installation Tips
It is always good to install Subversion from its sources. [2]
In such a case, the "configure" script from the Subversion source
should be run like this (assuming that the "httpd" server is
already installed):
./configure --with-apr=/full/path/to/apr-config
--with-apr-util=/full/path/to/apr-util-config
Post-installation Tips
After installing Subversion, I proceeded to play around with it using
"http" access, but things did not happen as I expected: A quick look at the
Web server logs revealed that "http" requests were failing. Thanks to
people on the 'svnforum' mailing list, the problem was quickly revealed: it
concerned the APR libraries used in Subversion source compilation.
Using the "ldd" command, I verified the APR libraries used in
'mod_dav_svn.so' and 'httpd', but they did not match — meaning that
"httpd" and mod_dav_svn were not referring to the same APR libraries they
should be.
[ram@lemuria ~]$ ldd /lnx_data/apache2.0.54/modules/mod_dav_svn.so | grep apr
libaprutil-1.so.0 => /lnx_data/apache2.0.54/lib/libaprutil-1.so.0 (0xb7def000)
libapr-1.so.0 => /lnx_data/apache2.0.54/lib/libapr-1.so.0 (0xb7d59000)
[ram@lemuria ~]$ ldd /lnx_data/apache2.0.54/bin/httpd | grep apr
libaprutil-1.so.0 => /lnx_data/apache2.0.54/lib/libaprutil-1.so.0 (0xb7f8f000)
libapr-1.so.0 => /lnx_data/apache2.0.54/lib/libapr-1.so.0 (0xb7f6d000)
"mod_dav_svn.so" should be linked to the same APR libraries as
used by "httpd", and fixing that took care of the problem.
Repository Access using HTTP
Following successful installation of Apache and Subversion, next,
repository access via http:// schema must be configured in
"</path/to/apache/conf>/httpd.conf". Some of the
parameters that can be configured are related to hosting the repository;
other parameters are related to the special/common user and group for
Apache and Subversion:
# If you wish httpd to run as a different user or group, you must run
# httpd as root initially and it will switch.
#
# User/Group: The name (or #number) of the user/group to run httpd as.
# It is usually good practice to create a dedicated user and group for
# running httpd, as with most system services.
#
User apache
Group apache_svn
After creating the repository and configuration, it's time to
bring-up the Web server and start accessing the repository
via http:// schema. As you can see below, the
"httpd" server is started and running as that
special/common user, "apache":
[ram@lemuria ~]$ ps auxw | grep apache
root 2984 0.7 0.6 7616 2848 ? Ss 19:46 0:00 /lnx_data/apache2.0.54/bin/httpd -k start
apache 2985 0.0 0.4 7616 1900 ? S 19:46 0:00 /lnx_data/apache2.0.54/bin/httpd -k start
apache 2986 0.0 0.4 7616 1900 ? S 19:46 0:00 /lnx_data/apache2.0.54/bin/httpd -k start
apache 2987 0.0 0.4 7616 1900 ? S 19:46 0:00 /lnx_data/apache2.0.54/bin/httpd -k start
apache 2988 0.0 0.4 7616 1900 ? S 19:46 0:00 /lnx_data/apache2.0.54/bin/httpd -k start
apache 2989 0.0 0.4 7616 1900 ? S 19:46 0:00 /lnx_data/apache2.0.54/bin/httpd -k start
Configuring svnserve
As stated in the Subversion manual, the svnserve
program is a lightweight server capable of communicating to
clients over TCP/IP using a custom, stateful protocol. Clients
can use svnserve services using either svn:// or svn+ssh://
access schema. However, before that, svnserve must be configured.
Here, again, there are multiple options: svnserve can be
configured to run by "inetd" or as a standalone
daemon process.
Authentication Options
In the following examples I have configured two separate
"svnserve" daemons, again on the same system, both
serving different repositories and listening to different ports.
For one of the repositories, authentication options are turned on
using Subversion's built-in authentication and authorization
mechanisms.
The result of configuring multiple repositories under
"svnserve" is
shown here.
Subversion's built-in authentication configured using
"/path/to/repository/conf/svnserve.conf" is shown
here.
The svnserve.conf shown in the previous example has
many entries and one among them is password-db =
passwd. This passwd file can be located in
the same directory as "svnserve.conf" and sample
entries of this file are shown here.
If "passwd-db = passwd" is turned on but there
are no real entries in the "passwd" file, you'll see
errors like this one:
[ram@lemuria svntest_project]$ svn commit -m "added the first test C file"
svn: Commit failed (details follow):
svn: /lnx_data/report_holder/svntest_project/conf/svnserve.conf:18: Section header expected
As can be seen here, commit
operations will run successfully once the appropriate entries are defined
in svnserve.conf and passwd.
NOTE: The passwd file referred to above is not the
same as the system file, /etc/passwd. The system
file cannot be used in svnserve's configuration.
Summary
In this brief article, I have tried to highlight basic
parameters and options usable for configuring Subversion
with or without Apache. It's also a good idea to go through Subversion
documentation to clarify your doubts on this tool's usage. Many
a time, it is worthwhile to consult people (e.g., the Subversion
users mailing list) and seek guidance towards resolving
Subversion problems.
[1] Rick Moen comments: Since all Linux Gazette
editorial production is managed via svn (Subversion), we've
tallied up considerable experience with both of these repository
options over the years, and can heartily recommend the stability
advantages of the newer FSFS option, which uses
platform-independent flatfiles rather than database storage: Our
experience with the older BerkeleyDB ("BDB") option was that
improperly terminating svn processes would often wedge the
repository if they died during commits, requiring an irksome
"recovery" operation before work could resume. FSFS repositories
are also less trouble to backup.
[2] Rick Moen comments: The usual cranky-sysadmin advice
applies: In my view, as a matter of administrative best
practices, compiling source code from an upstream maintainer's
source tarball should be your last resort, if good official
packages from your Linux distribution or trustworthy, quality
unofficial packages constructed for your Linux distribution don't
exist, only then should you use upstream tarballs as a fallback.
Even then, check to see if the the tarball provides build
instructions, e.g., an rpm SPEC file, for your distribution.
Why? Any time you skip the work done by distribution package
maintainers and work directly with upstream source code, you're
implicitly agreeing to either perform all of that work yourself
or suffer the consequences of its absence. Most people have
little conception of how much work that is, or its value. Package
maintainers monitor upstream releases to select which have the
best mix of new features and debugging (newer not necessarily
being better), usually apply patches to adapt them to
distribution-specific needs, and sometimes code and apply
security patches the upstream programmer never even thought of.
Moreover, they do this on an ongoing basis, making improvements
available to a myriad of systems, keeping those systems updated
without their admins needing to worry, let alone duplicate that
work.
Talkback: Discuss this article with The Answer Gang

I hold an engineering degree in Electronics &
Communication.
After finishing my degree in '95, I worked in customer support, system
administration, and lab/tools administration in various start-ups and in
Cisco's offshore development center in Chennai, India.
Currently, I am working at Infineon Tech India in the SCM (software config
mgmt) domain, leading a team of 6 engineers specializing in IBM Rational
ClearCase and ClearQuest with experience in Shell and Perl scripting.
Copyright © 2006, Muthaiah Ramanathan. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006
Coding a Simple Packet Sniffer
By Amit Saha
This article has been removed from this issue following revelation
of excessive direct copying from a primary source. Linux Gazette
was not aware of that copying until recently, and regrets it.
-- Ben Okopnik, Editor-in-Chief
Talkback: Discuss this article with The Answer Gang

The author is a 3rd year Computer Engineering Undergraduate at Haldia
Institute of Technology, Haldia. His interests include Network Protocols,
Network Security, Operating systems, and Microprocessors. He is a Linux fan
and loves to hack the Linux kernel.
Copyright © 2006, Amit Saha. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006
The Foolish Things We Do With Our Computers
By Ben Okopnik
"Foolish Things" is a now-and-again compilation we run based
on our readers' input; once we have several of these stories
assembled in one place, we get to share them with all of you. If
you enjoy reading these cautionary tales of woe, proud stories of
triumph, and just plain weird and fun things that happen between
humans and silicon, that's great; if you have some to share so
that others may enjoy them, even better. Please send them to
 .
.
[ You can even tell us that it happened to A Friend of Yours,
and we'll believe you. ]
-- Ben
A Black Mark on Their Reputation
Karl-Heinz Herrmann
We have a nice SCSI HP ScanJet that's been sitting around for
years; once in a while, we use it to scan X-ray films with a full
A4 backlight. After some PC rearranging, it got moved and stopped
working. The PC to which it was attached had SCSI cables that
were too long (which worked fine before), but, after being
shifted, the PC's SCSI disk would only run at lowest async speed.
We changed about everything on the chain including the SCSI
adapter in the stripped-down PC, but nothing helped. After giving
up on connecting the scanner, I put in the network card again:
the AGP graphics card stopped working, no screen output
whatsoever. Pull the network card out: screen acts OK. Hm.
Dismissing the PC as too flaky and ancient to care about (PII
400), I decided to plug the HP scanner into my Linux laptop just
to check it — and it worked perfectly. I then plugged it
into a mini-tower similar to the discarded one, and it worked
fine. So all is fine, right? Not so. After moving it around on
the table and arranging the cables nicely, it wouldn't work. Then
I realised that the scanner wasn't making the "normal noises" on
power up: it would move the sledge inside a short way — and
then nothing. When it was working, it would move the scan head
back and forth for a few seconds, and then switch off the light.
That was when we decided the scanner had a real problem after
all, and sent it to a repair shop — but they sent it back
saying the board was defective and they couldn't get a
replacement, since it's too ancient.
There it was, sitting on the desk — a huge thing, sturdy
beyond anything, and the board is "gone" just like that? By
moving it a bit? I decided to open it up and look for a bad
contact somewhere, maybe close to the SCSI connector. After I got
the case open (tricky to find the last two screws), I saw a bit
of the circuit board and the flat cables. Looks flawless to me
— fine mechanics, cable guides everywhere. So, I switch it
on, the head moves a little and stops with the light on —
so it's still not OK. But the light is blinding me, so I put a
sheet of paper on it — at which point, the head moves back
and forth, goes to the 'park' position and switches off the
light. (??!) It was reproducible, too. I turn around the top
cover, and there is the white strip used for calibrating the scan
sensors before each scan. I rub my finger over it, and it comes
up black; I clean the glass plate from the inside, put it on, and
— the scanner works perfectly. Damaged board indeed....
These fellows didn't even open it up.
Letting Out the Magic Smoke
Ben Okopnik
This is a story that I'm telling on myself rather than exposing someone
else's foolishness; as they say, "it was in a far country, and besides, the
wench is dead" — and I'm smarter (I hope!) than I was then. Many,
many years ago — those of you who were working with computers then
will have a good idea of when, once you read this — when I was just a
PFY and still
learning the computer repair trade, I was working on a relatively new
machine that I had brought home from a client's place. The problem was that
the motherboard manufacturer (long since out of business — and with
good reason) used tiny rivets to connect the layers on the
opposite sides of the board instead of properly plating everything all the
way through. Well, as time went on, and thermal expansion flexed the board
microscopically, these rivets came loose — and so did the
connections. Randomly. Sometimes yes and sometimes no — and sometimes
maybe; depending on the weather, the humidity, how recently the computer
had been pounded with a fist, etc.
Expensive as it was back then — and it was very expensive indeed
— I had convinced this client to replace all these boards. He agreed,
through gritted teeth, but got me to promise that I would try my best to
keep his old boards working as long as possible..., so I spent a lot of
time soldering these rivets, using a contact-cleaning file around their
edges to get at least some kind of connection, or trying to solder
hair-fine wires to the traces. (This worked very rarely, since the traces
were so thin that they'd burn up as soon as you touched them with a
soldering iron.)
Back then, the standard bit of advice was to leave the computer plugged
in but turned off while you worked on it; this provided a local ground that
you were always touching and decreased the chance of blowing the chips
— which were very sensitive to static back then. The
board that I was working on was fairly new, and had just started showing
that random behavior. As usual, I plugged it in, made sure it was turned
off, and was twiddling my tiny file while quietly cursing to myself —
when suddenly, the chip next to the rivet, which I just happened to touch
with the file, EXPLODED. I mean, literally — blew out a chunk of its
ceramic packaging so I could see the silicon underneath.
I was completely flabbergasted. I had made absolutely sure that I
switched it off; I knew that the capacitors in the PC power supply were
designed to discharge in a fraction of a second after shutdown... What
happened? I grabbed my voltmeter and started poking around in the machine,
and figured it out after about two hours of measurements:
The computer I was working on had been designed with a
brand-new feature: a power switch that "put it to sleep"
instead of turning it off.
(Yep... it was that long ago.)
I felt really awful, but... I did indeed follow the agreement
I had with that client: that board couldn't be repaired anymore,
and needed to be replaced. I forgot to mention that I was the one
that contributed to its slightly earlier demise.
P.S. I never signed up for that kind of serfdom
anything like that again - and I always used a grounding strap instead of a
plugged-in chassis since that day. :)
Orientation Week
Rick Moen
The time having come to concoct a replacement for my
server-grade 486DX2 EISA/VLB-bus Linux host, I decided one day
to build a new machine from best-of-breed parts (well, within
limits set by my being a cheapskate).
I happened to have an excellent tower case and PC Power &
Cooling power supply handy, a pair of Adaptec PCI SCSI host
adapters, a SoundBlaster Pro, Matrox G200 video, a couple of
large, fast IBM SCSI hard drives, a Plextor SCSI CDR, and a pair
of 3Com 3C509B 10 megabit ethernet cards. (Hey, all it had to do
was potentially max out a 1.54 megabit T-1 line, OK?) That left
the matter of motherboard and parts attendant thereto.
After some checking, I bought a nice little FIC PA-2007
Socket-7-type motherboard. Then, from my favourite
vendors (SA Technology), I acquired 128 MB of Crucial Technology
SDRAM capable of running at CAS2 operation at 100MHz, an AMD
K6/233 CPU, and a big-kahuna heat sink with a fan on top that
uses ball bearings instead of the standard, noisy, failure-prone
sleeve bearings. The ensemble was designed to be highly reliable,
and at the same time hackable if I ever decided to join the
then-pervasive overclocking madness.
Anyhow, I banged everything together. It seemed to
work fine. The big tower case, low-heat-output CPU, and major
cooling capacity meant that the thing ran very cool and
reasonably quiet, even with the two very fast IBM 10,000 RPM SCSI
hard drives.
As was my custom, I started compiling a kernel after a bit.
That compile errored out with a SIG11. Hmm. Tried again. Errored
out even faster, and at a different point in the compile. Odd. Do
I have bad RAM?
Shut down and re-seated the RAM. Went downstairs to the
CoffeeNet (a recently
reborn 1990s Linux-based Internet cafe I'd helped build) for
a caffeine infusion. Came back, powered up, ran the compile. No
problems. Ran the compile again: SIG11. Ran it again: SIG11 at a
different place. Ran it with only half the RAM: Same symptoms.
Ran it with the other half: Same. Didn't seem to be a RAM
problem(?).
Slept on the problem. Woke up, fired up the machine, ran a
compile: No problem. Ran it again: No problem. Ran it a third
time: SIG11. Ran it again: Same error, different spot.
Pondered the problem for a bit: It seemed as if the error was
kicking in only after the system reached heat equilibrium, but
not during the initial 30 minutes of operation when the system
was still stone-cold. But that didn't make much sense: I opened
up the case and re-verified that the system really was
an engineer's dream of conservative design, and that even the
10,000 RPM drives were running cool.
I drove down from San Francisco to the Palo Alto Fry's and
bought both the heat-conductive pads you can sandwich between
CPUs and their heat sinks and the thermal paste you can
use instead. I was going to make double-sure that I had good
contact, there, before taking the CPU back to SA Technology and
looking like an idiot if it turned out to be perfectly OK.
I took the heat sink off the CPU, cleaned both off, put paste
on them and pressed them together. For some reason, perhaps on
account of some bell ringing in my unconscious mind, a few
minutes later I pulled them apart again to look at the two pieces
more closely.
And swore.
The Socket-7 motherboard socket for the K6 has a square
outline, and the pins have a square pattern, with one corner of
the CPU's pin-layout being different so you won't destroy it by
putting it in the wrong way. When you put the CPU into the
socket, if you aren't looking too closely (cue ominous
music), you think: square socket, square CPU with a keyed feature
to keep you from screwing up, square heatsink/fan assembly. 1, 2,
3 — done. Foolproof. (Well, no.)
The top surface of the CPU turned out to have a
heatsink-contact surface that extended only across maybe 70% of
the lateral distance, and the other 30% was sunk down lower.
---------------------
| | |
| | |
| | |
| | |
| contact | |
| surface | |
| | |
| | |
---------------------
I'd accidentally rotated the heatsink 180 degrees, so that
its contact surface was staggered over to the
right-hand-side:
---------------------
| | |
| | |
| | |
| | |
| | contact |
| | surface |
| | |
| | |
---------------------
Only a little strip in the middle was actually touching, so
all the other thermal paste was still protruding up into the air,
un-squashed. Most of the CPU top surface was getting
zero help with cooling, and instead was radiating out
into a nice warm, insulating air pocket under the
heatsink.
If this had been an Athlon or P4 Coppermine, the CPU probably would have
committed seppuku, but the K6 was completely undamaged and has
been happily cranking away ever since.
But that experience confirmed me in my prejudice that a cool
CPU (like a cool system generally) is much, much, much to be
preferred over one that runs hot and needs heroic measures like
huge amounts of forced air flow to stave off disaster. Those
other ones may be faster — but usually (for most machine
roles) don't even manifest that speed in ways you especially care
about.
Talkback: Discuss this article with The Answer Gang

Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity
at the tender age of six, promptly demonstrated it by sticking a fork into
a socket and starting a fire, and has been falling down technological
mineshafts ever since. He has been working with computers since the Elder
Days, when they had to be built by soldering parts onto printed circuit
boards and programs had to fit into 4k of memory. He would gladly pay good
money to any psychologist who can cure him of the recurrent nightmares.
His subsequent experiences include creating software in nearly a dozen
languages, network and database maintenance during the approach of a
hurricane, and writing articles for publications ranging from sailing
magazines to technological journals. After a seven-year Atlantic/Caribbean
cruise under sail and passages up and down the East coast of the US, he is
currently anchored in St. Augustine, Florida. He works as a technical
instructor for Sun Microsystems and a private Open Source consultant/Web
developer. His current set of hobbies includes flying, yoga, martial arts,
motorcycles, writing, and Roman history; his Palm Pilot is crammed full of
alarms, many of which contain exclamation points.
He has been working with Linux since 1997, and credits it with his complete
loss of interest in waging nuclear warfare on parts of the Pacific Northwest.
Copyright © 2006, Ben Okopnik. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 128 of Linux Gazette, July 2006

{kind=link}
{kind=link}