
...making Linux just a little more fun!
Deividson Okopnik [deivid.okop at gmail.com]
Hello everyone!
Im looking for a multi-process CPU benchmark to be run on linux (CLI is even better), as I need to test how well a kerrighed cluster is running. Anyone know of any of those programs?
Thanks Deividson
[ Thread continues here (4 messages/2.54kB) ]
=?ISO-8859-2?Q?Petr_Vav=F8inec?= [pvavrinec at snop.cz]
Hello gurus,
I run a diskless, keyboard-less pc that boots into X11 (just plain twm as a window manager). The X clients I run remotedly, on a "database server". When someone switches off the Xserver PC (i.e. flips that big red switch), the X clients aren't killed - they remain on the "database server" forever (or at least 24 hours, that's for me the same as "forever"). Is there something that I could to to force them to die automa[t|g]ically?
Thanks in advance, Petr
[ Thread continues here (5 messages/5.55kB) ]
Amit Saha [amitsaha.in at gmail.com]
Hello TAG:
I know there are some 'hevea' users here. Could you help ? I am trying to convert this TeX article of mine into HTML and I run into:
Giving up command: \text
Giving up command: \@hevea@circ
./octave-p2.tex:227: Error while reading LaTeX:
End of file in \mbox argument
Adios
The relevant lines in my LaTex file are:
226 \begin{align*}
227 Minimize f(x) = c^\text{T}x \\
228 s.t. Ax = b, x \geq 0 \\
229 where b \geq 0
230 \end{align*}
What could be the problem ? I am using version 1.10 from Ubuntu repository.
Thanks a lot!
Best Regards, Amit
-- Journal: http://amitksaha.wordpress.com, �-blog: http://twitter.com/amitsaha
[ Thread continues here (3 messages/4.48kB) ]
Ben Okopnik [ben at linuxgazette.net]
Earlier today, I had a problem with my almost-brand-new Ubuntu 9.10 install: my netbook suddenly stopped booting. Going into "rescue" mode showed that it was failing to mount the root device - to be precise, it couldn't mount /dev/disk/by-uuid/cd4efbe9-9731-40a5-9878-06deff19af06 (normally, a link to "/dev/sda1") on '/'. When the system finally timed out and dropped me into the "initramfs" environment/prompt, I did an "ls" of /dev/disk/by-uuid - which showed that the link didn't exist. Yoiks... had my hard drive failed???
I was quickly comforted by the existence of another device in there, one that pointed to /dev/sda5, a swap partition on the same drive, but that could still have meant damage to the partition table. I tried a few things, none of which worked (i.e., rebooting the system would always bring me back to the same point)... until I decided to create the appropriate symlink in the above directory - i.e.,
cd /dev/disk/by-uuid ln -s ../../sda1 cd4efbe9-9731-40a5-9878-06deff19af06
and exit "initramfs". The system locked up when it tried to boot further, but when I rebooted, it gave me a login console; I remounted '/' as 'read/write', then ran "dpkg-reconfigure -plow ubuntu-desktop", the "one-size-fits-all" solution for Ubuntu "GUI fails to start" problems, and the problem was over.
NOW, Cometh The REALLY Big Problem.
1) What would cause a device in /dev/disk/by-uuid to disappear? Frankly, the fact that it did scares the bejeebers out of me. That shouldn't happen randomly - and the only system-related stuff that I did this morning was installing a few packages (several flavors of window manager so I could experiment with the Ubuntu WM switcher.) I had also rebooted the system a number of times this morning (shutting it down so I could take it off the boat and to my favorite coffee shop, etc.) so I knew that it was fine up until then.
2) Why in the hell did changing anything in the "initramfs" environment - i.e., creating that symlink - actually affect anything? Isn't "initramfs", as indicated by the 'ram' part, purely temporary?
3) What would be an actual solution to this kind of thing? My approach was based on knowing about the boot process, etc., but it was part guesswork, part magical hand-waving, and a huge amount of luck. I still don't know what really happened, or what actually fixed the problem.
I'd be grateful for any insights offered.
-- * Ben Okopnik * Editor-in-Chief, Linux Gazette * http://LinuxGazette.NET *
[ Thread continues here (12 messages/27.96kB) ]
=?ISO-8859-2?Q?Petr_Vav=F8inec?= [pvavrinec at snop.cz]
Allmighty TAG!
first, sorry for a longish post. I'm almost at my wit's end.
I have an industrial PC, equipped with a touch screen and "VIA Nehemiah" CPU (that behaves like i386). The PC has no fan, no keyboard, no harddisk, nor flash drive - only ethernet card. It boots via PXE from my database server. The /proc/meminfo on the PC says, that the PC has MemTotal: 452060 kB. I'm booting the "thinstation" (http://thinstation.sourceforge.net) with kernel 2.6.21.1. The PC uses ramdisk. I boot Xorg with twm window manager. Then I start client of the "Opera" browser on my database server and "-display" it on the X server on the PC. This setup has worked flawlessly for a couple of months.
Then my end-users came with complains, that the PC doesn't boot anymore after flipping the mains switch. For the moment, I have found following:
1. The PC sometimes doesn't boot at all. The boot process stops with the message:
Uncompressing linux... OK, booting the kernel.
...and that's all. Usually, when I switch the PC again off and on, it boots OK, I mean I don't change anything, just flip that big button.
2. When it really does boot all the way into X, the opera browser isn't able to start properly. I tried to investigate further the matter. I modified the setup, now I'm booting only into X+twm. This works.
Now I tried to run following test on my database server:
xlogo -display <ip_address_of_the_pc>:0
This works, the X logo is displayed on the screen of the PC.
Now I tried this test on the database server:
xterm -display <ip_address_of_the_pc>:0
Result is this error message on the client side (i.e. on the database server):
xterm: fatal IO error 104 (Connection reset by peer) or KillClient on X server "192.168.100.171:0.0"
...and the X server on the PC is really killed (I can't find him anymore in the process list on the PC).
This is, what I have found in the /var/log/boot.log on the PC:
------------ /var/log/boot.log starts here ---------------------------- X connection to :0.0 broken (explicit kill or server shutdown). /etc/init.d/twm: /etc/init.d/twm: 184: xwChoice: not found twm_startup twm: unable to open display ":0.0" ------------ /var/log/boot.log ends here ------------------------------
...and this is from /var/log/messages on the PC:
[ ... ]
[ Thread continues here (11 messages/16.28kB) ]
Mulyadi Santosa [mulyadi.santosa at gmail.com]
How do you catch a range or group of characters when using grep? Of course you can always do something like:
$ grep -E '[a-z]+' ./test.txtto show lines in file "test.txt" that contain at least single character between 'a' to z in lower case.
But there is other way (and hopefully more intuitive...for some people). Let's do something like above, but the other way around. Tell grep to show the name of text files that doesn't contain upper case characters
$ grep -E -v -l '[[:upper:]]+' ./*Here, upper is another way of saying [A-Z]. Note the usage of double brackets! I got trapped once, thinking that I should only use single bracket and wonder why it didn't work....
There are more classes you can use. Check "info grep" in section 5.1 "Character class"
-- regards, Mulyadi Santosa Freelance Linux trainer and consultant blog: the-hydra.blogspot.com training: mulyaditraining.blogspot.com
[ Thread continues here (2 messages/2.35kB) ]
Jimmy O'Regan [joregan at gmail.com]
Obviously, this isn't going to be everyone's cup of tea, but it would annoy me if I ever have to repeat this, or had to tell someone 'oh, I did that once, but forgot the details'.
Festival is a fairly well known as a speech synthesiser, but it's generally better suited as a development platform for voice and language data; Flite is a lightweight TTS system that uses data developed with Festival. Flite has some scripts to help the process, but they're either undocumented or misleadingly documented.
One such script is tools/make_phoneset.scm: the function synopsis gives 'phonesettoC name phonesetdef ODIR', but the actual synopsis is 'phonesettoC name phonesetdef silence ODIR', where 'name', 'silence' and 'ODIR' are strings, 'phonesetdef' is a Lisp list of features. I don't know Scheme or Lisp all that well, so I eventually got it to work by copying the phoneset to a file like this (myphones.scm):
(phonesettoC "my_phoneset" '(defPhoneSet my_phoneset ;;; Phone Features ( (vc + -) (vlng s l d a 0) (vheight 1 2 3 -) (vfront 1 2 3 -) (vrnd + -) (ctype s f a n l t 0) (cplace l a p b d v 0) (cvox + -) ) ( (# - 0 - - - 0 0 -) ;this is the 'silence' phonedef (a + l 3 2 - 0 0 -) ; snip ) ) (PhoneSet.silences "#") "outdir")
and converting it with: mkdir outdir && festival $FLITEDIR/tools/make_phoneset.scm myphones.scm
leaves a C file suitable for use with Flite in outdir
1 down, ~12 scripts left to figure out...
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
Rick Moen [rick at linuxmafia.com]
----- Forwarded message from Tony Godshall <tony@of.net> -----
Date: Tue, 1 Dec 2009 10:30:26 -0800 From: Tony Godshall <tony@of.net> To: conspire@linuxmafia.com Subject: [conspire] tip: avoid re-downloading full isosIf you have an iso that fails checksum and a torrent is available, rtorrent is a pretty good way to fix it.
cd /path/to/ubuntu910.iso && rtorrent http://url/for/ubuntu910.iso.torrent
The reason torrent is good for this is that it checksums each block and fetches only the blocks required.
Tony
conspire mailing list conspire@linuxmafia.com http://linuxmafia.com/mailman/listinfo/conspire
----- End forwarded message -----
By Deividson Luiz Okopnik and Howard Dyckoff

|
Contents: |
Please submit your News Bytes items in plain text; other formats may be rejected without reading. [You have been warned!] A one- or two-paragraph summary plus a URL has a much higher chance of being published than does an entire press release. Submit items to bytes@linuxgazette.net. Deividson can also be reached via twitter.
 New Novell Collaboration Platform for E2.0 Links to Google Wave
New Novell Collaboration Platform for E2.0 Links to Google WaveIn early November, Novell announced its real-time collaboration platform, Novell Pulse. Pulse combines e-mail, document authoring, and social messaging tools with robust security and management capabilities.
Novell Pulse was demonstrated on November 4, 2009, during the "Integrating Google Wave into the Enterprise" keynote at Enterprise 2.0 in San Francisco. Beta availability will be early 2010, followed by general availability in the first half of 2010 via cloud deployment. Novell Pulse interacts with Google Wave through Wave's federation protocol, letting Novell Pulse users communicate in real-time with users on any other Wave provider.
"We designed Google Wave and its open federation protocol to help people collaborate and communicate more efficiently", said Lars Rasmussen, software engineering manager for Google Wave. "We are very excited to see Novell supporting Wave federation in its innovative Novell Pulse product."
"Security and identity management remain top concerns for companies considering real-time social solutions", said Caroline Dangson, analyst at IDC. "Novell has a proven record in security and identity management, an important strength for its new collaboration platform."
Key features draw on best practices for e-mail, instant messaging, document sharing, social connections, real-time co-editing, and enterprise control. These include single sign on, identity management, editable on-line documents, and a unified inbox.
For more information on Novell Pulse, visit http://www.novell.com/products/pulse/.
ECMA Proposes Revised JavaScript StandardThe future of JavaScript - at least for the next 3 years - will be determined by ECMA's General Assembly in early December. At that time, ECMA's membership will vote on the ECMAScript 3.1 proposal, a technology compromise from ECMA's contentious Technical Committee 39.
Factions within TC39 worked on JavaScript revision for several years, but AJAX's success upped the stakes for v. 4.0 - which is far from complete - so a smaller set of improvements went into the 3.1 draft. However, both Adobe and IBM are dissatisfied, and are lobbying to defeat it.
Doug Crockford, who represents Yahoo on TC39, delivered a keynote on the draft spec and its importance recently, at QCon in San Francisco. Doug explained that the sudden explosion in use of JavaScript (formally called ECMAScript) - both upped the stakes on revisions and intensified risks. One example is an on-going problem with representing decimal numbers. Original JavaScript can represent small and large integers, but often gives erroneous results for decimal arithmetic (e.g., 0.1 + 0.2 != 0.3).
IBM has proposed a revision ("754-r") to the 1970s-era IEEE 754 spec for floating point processing. However, this change would result in significant performance penalties on arithmetic unless implemented in silicon, which IBM has already done in Power CPUs. Speaking with Linux Gazette, Doug said IBM may be attempting to increase the value of its Power servers, or may be encouraging Intel to modify its own chips.
The committee is also discussing a longer-term set of changes to JavaScript / ECMAScript, with a working title of Harmony. Some additions could include enhanced functions and inclusion of a standard crypto library. However, many of those changes could break existing Web applications; implementations will have to do as little damage as possible.
Fedora 12 Released in NovemberThe Fedora Project, Red Hat's community-supported open source group, announced availability of Fedora 12, the latest version of its free, open-source distribution. The new release includes robust features for desktop users, administrators, developers, and open source enthusiasts. Enhancements include next-generation Ogg Theora video, virtualization improvements, and new capabilities for NetworkManager.
"Fedora always tries to include cutting-edge features in its distribution. We believe Fedora 12 stays true to this pattern, packing a lot of punch across its feature set", said Paul Frields, Fedora Project Leader at Red Hat. "Our community of global contributors continues to expand, with 25 percent growth in Fedora Accounts since Fedora 11. We've also seen more than 2.3 million installations of Fedora 11 thus far, a 20 percent increase over earlier releases."
Notable feature enhancements:
Other improvements are PackageKit command-line and browser plugins; better file compression; libguestfs, which lets administrators work directly with virtual guest machine disk images without booting those guests; SystemTap 1.0, to help developers trace and gather information for writing and debugging programs, as well as integration with the widely-used Eclipse IDE; and NetBeans 6.7.1.
The Fedora community held fifteen Fedora Activity Day events across the globe in 2009. These are mini-conferences where Fedora experts work on a specific set of tasks, ranging from developing new features and Web applications to showing contributors how to get involved by working on simple tasks. During that same period, the Project also held three Fedora Users and Developers Conferences (FUDCons), in Boston, Porto Alegre, and Berlin.
The next FUDCon is scheduled for December 5 - 7, 2009, in Toronto, Ontario, Canada. For more information about FUDCon Toronto 2009, visit http://fedoraproject.org/wiki/FUDCon:Toronto_2009.
For more information about the Fedora Project, visit http://www.fedoraproject.org.
New Knoppix 6.2 Released"Microknoppix" is a complete rewrite of the Knoppix boot system from version 6.0 and up, with the following features:
The current 6.2 release has been completely updated from Debian "Lenny".
Also included is A.D.R.I.A.N.E. (Audio Desktop Reference Implementation And Networking Environment), a talking menu system, which is supposed to make work and Internet access easier for computer beginners.
The current public 6.2 beta (CD or DVD) is available in different variants at the Knoppix Mirrors Web site (http://www.knopper.net/knoppix-mirrors/index-en.html).
Intalio Announces Jetty 7Intalio, Inc., has released Jetty 7, a lightweight open source Java application server. The new release includes features to extend Jetty's reach into mission-critical environments, and support deployment in cloud computing.
Jetty 7 brings performance optimizations to enable rich Web applications. Thanks to small memory footprint, Jetty has become the most popular app server for embedding into other open source projects, including ActiveMQ, Alfresco, Equinox, Felix, FUSE, Geronimo, GigaSpaces, JRuby, Liferay, Maven, Nuxeo, OFBiz, and Tungsten. Jetty is also the standard Java app server in cloud computing services, such as Google's AppEngine and Web Toolkit, Yahoo's Hadoop and Zimbra, and Eucalytpus.
This is the first Jetty release developed in partnership with Eclipse.org, where the codebase has gone through IP auditing, dual licensing, and improved packaging for such things as OSGi integration. In addition, Jetty 7 makes some of the key servlet 3.0 features, such as asynchronous transactions and fragments, available in a servlet 2.5 container.
Jetty provides both asynchronous HTTP server and asynchronous HTTP client, thereby supporting both ends of protocols such as Bayeux, XMPP, and Google Wave, that are critical to cloud computing — and can be embedded in small and mobile devices: Today, Jetty runs on J2ME and Google Android, and is powering new smartphones from Verizon and other manufacturers soon to start production.
"Jetty 7 significantly reorganizes packaging and jars, and makes fundamental improvements to the engine's underlying infrastructure", said Adam Lieber, General Manager at IntalioWorks.
The Jetty distribution is available via http://eclipse.org/jetty under the Apache 2.0 or Eclipse 1.0 licenses, and covered by the Eclipse Foundation Software User Agreement. The distribution furnishes core functionality of HTTP server, servlet container, and HTTP client. More information and technical blogs can be found at http://www.webtide.com/.
One Stop Systems Introduces First GPU/SSD 2U ServerOne Stop Systems, Inc. (OSS), a manufacturer of computer modules and systems, announced the first server to integrate an AMD-based motherboard featuring dual "Istanbul" processors and eight GPU boards providing 10 TeraFLOPS computing power. The server can also accommodate a combination of GPU boards and SSD (solid state drive) boards.
Four GPU boards and four 640GB SSD boards provides 5TFLOPS GPU processing and 2.5TB memory, in addition to the dual six-core CPUs' computing power. In addition, OSS has packed even more storage capacity into the system, with four hot-swappable hard disk drives and an internal RAID controller. The server is powered by dual, redundant 1,500 watt power supplies and housed in a 2U-high chassis tailored for rigorous environmental demands.
"The Integrated GPU Server represents a combination of One Stop Systems's areas of expertise; designing and manufacturing rugged, rackmount computers and PCI Express design", said Steve Cooper, CEO. "At the heart of this server is the dual Opteron processor board. With a motherboard based on the SHBe (System Host Board Express) form factor for industrial computing, it's built for long-life service. Then, we employed multiple PCIe switches to provide the 80Gb/s bandwidth to each slot. Using the latest AMD-based GPU boards, we produce greater than 10 TFLOPS of computing power. The system is then powered by dual redundant 1,500 watt power supplies with ample cooling."
The system supports two six-core Opteron processors and up to 96GB DRAM in six DDR2 DIMM slots, plus dual gigabit Ethernet ports, four USB, PCI Express 2.0, and ATI Radeon graphics. It supports four SATAII/SAS drives, and includes an LSI RAID controller.
The system can be configured to provide eight PCIe x16 Gen 2 slots for single-wide I/O cards, or four slots for double-wide cards. While GPUs offer the greatest amount of compute power, customers who want to mix other cards in the system can do so. A common example is to install two or four GPU boards with four SSD (solid state drive) boards.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dokopnik.jpg)
Deividson was born in União da Vitória, PR, Brazil, on 14/04/1984. He became interested in computing when he was still a kid, and started to code when he was 12 years old. He is a graduate in Information Systems and is finishing his specialization in Networks and Web Development. He codes in several languages, including C/C++/C#, PHP, Visual Basic, Object Pascal and others.
Deividson works in Porto União's Town Hall as a Computer Technician, and specializes in Web and Desktop system development, and Database/Network Maintenance.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard maintains the Technology-Events blog at
blogspot.com from which he contributes the Events listing for Linux
Gazette. Visit the blog to preview some of the next month's NewsBytes
Events.

The Linux User Group (also known as a LUG) has been one of the cornerstones of Linux advocacy ever since its first inception. Bringing together local Linux lovers, it is the grassroots of Linux - where neighbours and other townfolks can sit around a table and discuss the best way to compile the kernel for their machines, or how to get their Slackware network devices going again. It is also a high bandwidth way to share knowledge - if you've ever heard of the sneaker-net, you'll appreciate the advantages of being in a room full of real people who share your interest in open-source software.
Chances are good that you are already in an area that has a local LUG, and a simple search online should be able to confirm it. However, if you happen to be in an area where none currently exists, the process of actually setting up a group is very easy.[1]
Your group will be ready to go once you've got a basic framework in place:
The first two items shouldn't take longer than a couple of hours to set up, and will only need minimal maintenance after that. The meeting spot will take a little longer, but, with the collective effort of your group (communicating through the mailing list) it shouldn't be too difficult.
Now it's just a matter of getting a few people interested. It's alright if the first members are your friends - that's how the ball gets rolling! The LUG will take on a life of its own, once you have outsiders coming in, so find ways of getting the word out around town. Postering universities and cafes (be sure to ask permission) is a great way to get other like-minded folks to check out your Web site and meetings.
Keeping things interesting isn't something that is easily done spontaneously, so you'll want to keep note of ideas for presentations and events for future use. It's essential to keep the creative pump primed, otherwise it will be hard keeping members coming to meetings.
Fortunately, your members will be a great resource in letting you know what they're interested in - after all, they want to have fun, too! When someone is bursting with passion over the new distro he or she just installed, that enthusiasm can be infectious. Encourage this passion, because these people will help keep the group moving along.
Occasionally, there's the meeting where a talk or the scheduling has fallen through. This is a great time to be generating ideas and keeping those creative juices flowing. Keeping the meet-ups consistently fun and engaging will keep everyone showing up time and time again.
The greatest benefits of a LUG is what it can do for the local community. It can be donating Linux-loaded machines to non-profit groups, install-fests to help people start using Linux, or connecting people from different technology groups who wouldn't normally interact.
One of the beauties of Linux and F/OSS software is that there are many ways that people from different technology backgrounds and groups can contribute. Java programmers, hardware hackers, and theoretical scientists can all sit at the same table and meet common ground at a LUG, when given a good topic to think over. Therefore, keep connected with all the local groups which could potentially have a few Linux users (or future Linux users).
A lot of groups get side-tracked by things like dues, group bylaws, and other organizational structures that are necessary to keep the group viable year-to-year. Transparency is key, but don't let the meetings get bogged down in administrative matters - keep it short, keep it simple, and keep it civil. If an issue can be relegated to the mailing list, that's the best spot for it. That way everyone has a chance to speak up, and it's all available on the public record.
Starting a LUG is a rewarding experience, and can be a great experience for everyone involved. With so many successful groups running now, it has never been easier to start your own, so start organizing one today!
Wikipedia entry
on Linux User Groups
UniLUG
The Linux
Documentation Project's LUG HOWTO
[1] Rick Moen comments: My rule of thumb in the LUG HOWTO, and other writings on the subject, is that a successful LUG seems to need a core of at least four active members -- who need not be particularly knowledgeable. As you say, not a lot else is strictly necesssary.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/crosby.jpg)
Dafydd Crosby has been hooked on computers since the first moment his dad let him touch the TI-99/4A. He's contributed to various different open-source projects, and is currently working out of Canada.
By Rick Moen
A few days ago, out of nowhere, Google, Inc. announced that it was offering a new free-of-charge service to the public: robust recursive DNS nameservice from highly memorable IP addresses 8.8.8.8 and 8.8.4.4, with extremely fast responses courtesy of anycast IP redirection to send the query to the closest network cluster for that service (like what Akamai and similar CDNs do for Web content).
This service needs some pretty considerable funding for hardware and bandwidth, especially if its usage scales upwards as Google intends. Reportedly, it also developed a totally new recursive-only nameserver package, name not disclosed, in-house. According to my somewhat casual research, the software was probably written by Google developer Paul S. R. Chisholm, who doesn't seem to have any prior record of writing such software.
That is remarkable, to begin with, because recursive nameservers are notoriously difficult to write correctly, such that the history of open source DNS servers is littered with failed recursive-nameserver projects. (By contrast, the other types, authoritative, iterative, and forwarder, are much easier to write. Please see my separate article, "The Village of Lan, A Networking Fairy Tale", about the differences.)
The obvious question is, what's in it for Google? At first, I guessed it to be a research/prestige project, an opportunity for Chisholm and other technical staff to try their hand at managing major network infrastructure. It also already serves as DNS foundation for some internal Google services, such as the WiFi network for visitors to the Google campus, and for the free public WiFi network Google offers to residents of Mountain View, California, near its headquarters. That didn't really seem sufficient to justify the outlay required in expenses and technical resources, though.
My friend Don Marti suggested an alternative idea that sounds more promising: It's a "spamtenna", a distributed data-collection system that classifies DNS clients: those doing high numbers of DNS lookups of known spam-related hostnames, and regular DNS clients that don't. Then, other hostnames resolved more often by the first group than the second are noted as also probably spam-involved. Google can use that database of suspect hostnames in anti-spam service, to aid GMail antispam, etc., a usage model consistent with Google's privacy policy.
Is Public DNS an attractive offering? Does it have privacy problems? Yes and no.
For most people, probably even most Linux Gazette readers, DNS is just something automatically taken care of, which means it tends to get referred out to the local ISP's recursive nameservers. I shouldn't be unkind to ISPs, who do their best, but ISP recursive servers tend to be pretty bad. In general, they have spotty performance, often play tricks such as redirecting queries or ignoring time-to-live timeouts on DNS data, are security liabilities (on account of pervasive "cache poisoning" by malign parties elsewhere on the Internet), and of course are an obvious point where data collects about all of your DNS queries -- what you and your users ask about, and what is replied. Of course, your ISP already sees all all your incoming and outgoing packets -- but, unlike Google, are contractually obliged to deal with you in good faith and look after your interests.
That is one of the problems with Google's Public DNS offering, and, likewise, with its other free-of-charge services such as GMail (and, for that matter, with pretty much any unpaid "Web 2.0" service): Any contractual commitment to users is either non-existent or extremely weak. They say they have a strong privacy policy, with information about which of your IP addresses queried their servers being erased after 24-48 hours, but the fact is that you're just not a paying customer, so policies don't mean much, completely aside from the possibility of them being changed on a whim.
Another problem I've already alluded to: What software does it use, and is it reliable and correct? Google is telling the public nothing about that software, not even its name, except that it was developed in-house and is not to be open source in the foreseeable future. Most of the really good recursive nameserver packages were developed as open source (in part) to get the benefit of public debugging and patches. The rest took a great deal of time and money to get right.
One common comparison is to David Ulevich's OpenDNS free recursive service, which is competently run and keeps users away from malware/phishing hostnames. Unless you use the paid version, however, OpenDNS deliberately breaks Internet standards to return the IP of its advertising Web server whenever the correct answer is "host not found" (what is called NXDOMAIN in DNS jargon). Google Public DNS doesn't suffer the latter problem.
A third alternative: None of the above. Run your own recursive nameserver. For example, NLnet Labs's open-source Unbound is very easy to set up, requires no maintenance or administration, takes only about 11 MB RAM, and runs on Windows, Linux, or Mac OS X. It would be silly to run such a network service on every machine: Instead, run it on one of the machines of your home or office's LAN, and have all of the machines' DNS client configurations -- /etc/resolv.conf on Linux machines -- point to it. That way, there's a single shared cache of recently queried DNS data shared by everyone in the local network.
(Note: Most people have their machines' "resolv.conf" contents, along with all other network settings, populated via DHCP from a local network appliance or a similar place, and configure that to point clients' DNS to the nameserver machine's IP. For that reason, the nameserver machine should be one to which you've assigned a static IP address, and left running 24/7.
Hey, OpenWRT wireless-router firmware developers! Make me happy and put Unbound into OpenWRT, rather than just Dnsmasq, which is a mere forwarder, and Just Not Good Enough. Dnsmasq forwarding to Unbound, however, would be really good, and putting recursive DNS in the same network appliance that hands out DHCP leases is the ideal solution for everyone. Thanks!)
It seems that hardly anyone other than us networking geeks bothers to have real, local nameservice of that sort -- a remarkable example of selective blindness, given the much snappier network performance, and greater security and control, that doing it locally gains you for almost no effort at all.
In fact, what's really perplexing is how many people, when I give them the above suggestion, assume either that I must be exaggerating the ease of running a recursive nameserver, or that "professional" options like their ISP, OpenDNS, or Google Public DNS must actually be faster than running locally, or both. Let's consider those: (1) When I say there's nothing to administer with recursive nameserver software, I mean that quite literally. You install the package, start the service, it runs its cache by itself, and there are no controls (except to run it or not). It's about as foolproof as network software can get. (2) When your DNS nameserver is somewhere on the far side of your ISP uplink, then all DNS queries and answers must traverse the Internet both ways, instead of making a local trip at ethernet speeds. The only real advantage a "professional" option has is that its cache will be already well stocked, hence higher percentage of cache hits relative to a local nameserver when the latter first starts, but then there will be essentially no difference and the local service will thereafter win because it's local.
Why outsource to anyone, when you can do a better job locally, at basically no cost in effort?
BIND9: Big, slow, kitchen-sink package that does recursive
and authoritative service, and even includes a resolver library (DNS
client lib).
http://www.isc.org/index.pl?/sw/bind/
Licence: Simple permissive licence with warranty disclaimer.
dnscache (from djbdns): Fast, threaded, secure, needs
to be updated with various packages, which you can get in one of four
downstream maintained variants of the 2001 abandonware djbdns package:
zinq-djbdns, Debian djbdns, RH djbdns, or LolDNS.
http://cr.yp.to/djbdns.html,
but also see my links to further information at
http://linuxmafia.com/faq/Network_Other/dns-servers.html#djbdns
Licence: Asserted to be "public domain".
MaraDNS: general-purpose, fast, lightweight,
authoritative, caching forwarder, and recursive server, currently being
rewritten to be even better.
http://www.maradns.org/
Licence: Two-clause BSD licence.
PowerDNS Recursor: Small and fast. Has been a little
slow in fixing possible security risks, e.g., didn't take measures
against the ballyhooed vulnerability Dan Kaminsky spoke of until March
2008 -- but is excellent otherwise.
http://www.powerdns.com/en/products.aspx
Licence: GNU GPLv2.
Unbound fast, small, modular caching, recursive server,
from the same people (NLnet Labs) who produced the excellent NSD
authoritative-only nameserver.
http://unbound.net/
Licence: BSD.
This might be you: You have one or more workstation or laptop on either a small LAN or direct broadband (or dialup) connection. You're (quite rightly) grateful that all the gear you run gets dynamic IP configuration via DHCP. The only equipment you have drawing power on a 24x7 basis is (maybe) your DSL modem or cable modem and cute little network gateway and/or Wireless Access Point appliance (something like a Linksys WRT54G). You don't have any "server" other than that.
Mea culpa: Being one of those oddballs who literally run servers at home, I keep forgetting you folks exist; I really have no excuse.
Shortly after I submitted the first version of this article to LG, a friend on my local Linux user group mailing list reminded me of the problem: He'd followed my advice and installed Ubuntu's Unbound package on his laptop, but then (astutely) guessed it wasn't being sent queries, and asked me how to fix that. His house had the usual network gateway appliance, which (if typical) runs Dnsmasq on embedded Linux to manage his Internet service, hand out DHCP leases on a private IP network, and forward outbound DNS requests to his ISP nameserver.
As I said above, it would be really nice, in such cases, to run a recursive nameserver (and not just Dnsmasq) on the gateway appliance, forwarding queries to it rather than elsewhere. That's beyond the scope of my friend's immediate needs, however. Also, I've only lately, in playing with OpenWRT on a couple of actual WRT54G v.3 devices received as gifts, realised how thin most such appliances' hardware is: My units have 16 MB total RAM, challenging even for RAM-thrifty Unbound.
My friend isn't likely to cobble together a static-IP server machine just to run a recursive nameserver, so he went for the only alternative: running such software locally, where the machine's own software can reach it as IP 127.0.0.1 (localhost). The obstacle, then, becomes DHCP, which by design overwrites /etc/resolv.conf (the DNS client configuration file) by default every time it gets a new IP lease, including any "nameserver 127.0.0.1" lines.
The simple and elegant solution: Uncomment the line "#prepend domain-name-servers 127.0.0.1;" that you'll find already present in /etc/dhcp3/dhclient.conf . Result: The local nameserver will be tried first. If it's unreachable for any reason, other nameserver IPs supplied by DHCP will be attempted in order until timeout. This is probably exactly what people want.
(If, additionally, you want to make sure that your DHCP client never requests additional "nameserver [IP]" entries from the DHCP server in the first place, just edit the "request" roster in /etc/dhcp3/dhclient.conf to remove item "domain-name-servers".)
Second alternative: Install package "resolvconf" (a utility that aims to mediate various other packages' attempts to rewrite /etc/resolv.conf), and add "nameserver 127.0.0.1" to /etc/resolvconf/resolv.conf.d/head so that this line always appears appears at the top of the file. This is pretty nearly the same as the first option.
Last, the time-honoured caveman-sysadmin solution: "chattr +i /etc/resolv.conf", i.e., setting the file's immutable bit (as the root user) so that neither your DHCP client nor anything else can alter the file until you remove that bit. It's hackish and unsubtle, but worth remembering for when only Smite with Immense Hammer solutions will do.
Talkback: Discuss this article with The Answer Gang
His first computer was his dad's slide rule, followed by visitor access
to a card-walloping IBM mainframe at Stanford (1969). A glutton for
punishment, he then moved on (during high school, 1970s) to early HP
timeshared systems, People's Computer Company's PDP8s, and various
of those they'll-never-fly-Orville microcomputers at the storied
Homebrew Computer Club -- then more Big Blue computing horrors at
college alleviated by bits of primeval BSD during UC Berkeley summer
sessions, and so on. He's thus better qualified than most, to know just
how much better off we are now.
When not playing Silicon Valley dot-com roulette, he enjoys
long-distance bicycling, helping run science fiction conventions, and
concentrating on becoming an uncarved block.
 Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
By Rick Moen
There was a time, about a year ago, when I was trying to tell people on a LUG mailing list why they should consider using a genuine, full-service recursive nameserver on their local networks, rather than just the usual forwarders and such. One of the leading lights of that LUG countered with his own suggestion: "Run a caching-only or caching-mostly nameserver". Argh! People get so mislead by such really bad terminology.
The concept of a "caching" DNS nameserver really doesn't tell you anything about what the nameserver really does. All nameservers cache; that's not a name that conveys useful information.
What I needed, to clarify the matter, was a compelling and vivid metaphor, so I conjured one up. Here's what I posted back to the LUG mailing list, reproduced for the possible entertainment of Linux Gazette readers:
Although it's true that some recursive-nameserver configurations are (sloppily) referred to as "caching", e.g., by RHEL/Fedora/CentOS, that's a really bad name for that function -- because caching is orthogonal to recursion.
Theoretically, you could write a nameserver that does recursive service but doesn't cache its results. (That would be a bit perverse, and I don't know of any.) Conversely, nameserver packages that cache but know nothing about how to recurse and instead do less-helpful alternative iterative service iterative service are common: dnsmasq, pdnsd, etc.
Last, it's also not unheard-of to create a really modest caching nameserver package that doesn't do even iterative service of its own, but is purely a forwarder that knows the IP of a real nameserver -- or leaves that job up to the machine's resolver library (DNS client). I believe dproxy and nscd would be good examples.
And, whether they cache or not (and pretty much everything caches except OS client resolver libraries), nameservers that aren't just forwarders offer either recursive or merely iterative service, which makes a big difference.
I know it's not your fault, but terms like "caching-only" and "caching-mostly" obscure the actual important bits. Fortunately, I think I've just figured out how to fully de-obfuscate the topic. Here:
The mythical village of Lan has some talkative people (programs) in it. Oddly, they spend most of their time talking about DNS data ;-> , but all have quirks about their respective conversational styles.
Larry, the local DNS library (the crummy BIND8-derived code bundled into GNU libc), is the guy with all the questions. He's the guy who goes around asking other people about DNS records. Larry has a really awful memory (no cache), so he ends up asking the same questions over and over.
Nick (nscd, the nameservice caching daemon) is a kid whom Larry has ride on his shoulders occasionally. Although he doesn't accept queries himself, exactly, he listens to answers Larry gets from others, remembers them, and whispers them in Larry's ear when the forgetful old guy is about to go bother others about them yet again. Larry's glad to carry Nick around, to help compensate for his memory problem. On the downside, Nick's a bit sloppy and doesn't bother to commit to memory the data's spoiled-by dates. (He doesn't cache TTLs.)
(I hear that the Linux nscd implementation's rather severe fault of not caching TTLs is slated to soon be fixed. Meanwhile, smart people don't use its host caching functions.)
Frank is a forwarder (a copy of dproxy). He's not really bright, but has a pretty good memory. If you ask him a DNS question, he either says "Dunno, so I'll ask Ralph", or he says "Hey, someone asked me that just yesterday, and I got the answer via Ralph. Let's see if I still have the paper... yes. Here's your IP (or other requested datum -- and you're in luck, as it still has 6 days remaining in its TTL)." Thus, he forwards all queries he receives -- always to Ralph only, never anyone more suited to the query -- and caches whatever Ralph tells him.
When Larry gets such answers, he might also seek some context information from Frank. (Remember, Larry has sucky short-term memory.) "Hey, Frank, thanks. Is that answer something you know from your own knowledge?" "No, man, it's just what I hear."
Nils is an authoritative nameserver (running the "nsd" software), charged ONLY with answering questions of the form "What is [foo].lanvillage.com?" When Larry asks him such a question, he answers and adds that it is from his own knowledge (authoritative). If you ask him about anything outside lanvillage.com, he frowns and say "Dunno, man."
Ralph is a recursive nameserver (an instance of PowerDNS Recursor). Ralph is a born researcher: He doesn't have any DNS knowledge of his own (offers no authoritative service), but absolutely lives for finding out what DNS data can be unearthed from guys in other villages. If you ask him a DNS question, he'll figure out whom to ask, go there regardless of where it takes him, if necessary chase around the state following leads, and only bother you when he has the final answer. (This is the "recursive" part. Compare with the iterative approach, below.) Like everyone else in this village except Larry, he has a good memory (caching).
Let's say, Larry asks Ralph, "What's uncle-enzo.linuxmafia.com?" In the worst case, if Ralph is just back from vacation (has a depleted cache), Ralph goes off for a while, and says: "I looked on my desk to see if the answer were there (in cache), but it wasn't. So, I checked to see if answers to the question 'Where are nameservers for the linuxmafia.com domain?' were there, but they weren't either. So, I check to see if answers to the question 'Where are nameservers for the .com top-level domain?' were there, but they weren't either. So, I finally fell back on my Rolodex's list of 13 IP addresses of root nameservers, picked one, and visited it. I asked it where I can get answers to .com questions. It gave me a list of .com nameserver IPs. I picked one, visited it, and asked who knows about linuxmafia.com DNS matters. It gave me a list of linuxmafia.com IPs, I picked one, visited it, asked it where uncle-enzo.linuxmafia.com is, brought the answer back, and here y'are. Oh, and I've made a note who knows where .com information is, where specifically linuxmafia.com information is, and also where uncle-enzo.linuxmafia.com is, just in case I'm asked again."
Larry's fond of Ralph, because Ralph does all the work and doesn't come back until he can give either the answer or "Sorry, this took too long", or "There's no such host", or something similarly dispositive.
Dwayne is a nameserver offering iterative service only (running dproxy). You can get any DNS answer out of him eventually, but he's not willing to bounce around the state following leads. A conversation with Dwayne is sort of punctuated:
"Do you know where uncle-enzo.linuxmafia.com is?" "No."
"Well, do you know who knows?" "No."
"Well, do you know who knows where to find .com nameservers?" "No."
"Well, can you ask the root nameserver where to find .com nameservers?" "OK." [Gives list of 13.]
"Can you ask .com nameserver #1 who answers for linuxmafia.com?" "OK." [Gets list of five nameserver IPs.]
"Can you ask linuxmafia.com nameserver #1 where uncle-enzo.linuxmafia.com is?" "OK." [Queries and gets answer.]Next time Dwayne is asked any of the first three questions, his answer is no longer "No", because he is able to answer from memory (cache).
Notice that Dwayne, although not as helpful and resourceful as Ralph, is at least going about things a bit more intelligently than Frank does: Dwayne is able to look up the chain of people outside to query (iteratively) to find the right person, whereas Frank's idea of research is always "Ask Ralph."
At the outskirts of the Village of Lan is a rickety rope-bridge to the rest of the state. (Think "Indiana Jones and the Temple of Doom", or "Samurai Jack and the Scotsman".) All of Lan's commerce has to go over that bridge (an analogy to, say, a SOHO network's overburdened DSL line). Frank or Dwayne's bouncing back and forth across that bridge continually gets to be a bit of a problem, because of bridge congestion. Ralph's better for the village, because he tends to go out, wander around the state, and then come back -- minimising traffic. And all of these guys with functional short-term recall (everyone but Larry) is helping by avoiding unnecessary bridge crossings.
On the far side of the (slow, rickety, congested) ropebridge is Ollie (the OpenDNS server). Ollie is willing to do recursive service the way Ralph does, but instead of saying "I checked, and there is no such DNS datum" where that is the correct answer, it says "guide.opendns.com" (IP 208.67.219.132), which is the IP of a OpenDNS Web server, advertising-driven, that tries to give you helpful Web results (plus ads) -- something that's less than useful, and in fact downright harmful, if what's attempting to use DNS isn't a Web browser. (Gee, ever heard of e-mail, for example?)
I don't know about you, but I think "That place doesn't exist" is a better answer than "guide.opendns.com, IP 208.67.219.132", when "That place doesn't exist" is in fact the objectively correct answer. Ollie says:
$ dig i-dont-exist.linuxmafia.com @resolver2.opendns.com +short
208.67.219.132By contrast, my own nameserver gives the actually correct answer:
$ dig i-dont-exist.linuxmafia.com @ns1.linuxmafia.com +short
$(Specifically, it says "NXDOMAIN", which means "That place doesn't exist.")
Getting back to Larry: Larry can outsource all of his queries across the rickety, thin, congested ropebridge to Ollie -- and spend time waiting for Ollie and watching him barge continually across it every time there's a query -- and know that Ollie gives bullshit answers every time the correct answer should be "That place doesn't exist."
Larry can use Dwayne's services -- something of an exercise in frustration but better than nothing. He can tap Frank, which is barely better than nothing. Or, he can use Ralph.
Regardless of whom he asks, he can let Nick ride on his shoulders and serve as his aide-memoire -- with the drawback that Nick carelessly disregards something really, really important (TTLs).
Personally, if I were Larry, I'd give Frank, Dwayne, and Ollie a pass, dump Nick, and give Ralph a call.
Talkback: Discuss this article with The Answer Gang
His first computer was his dad's slide rule, followed by visitor access
to a card-walloping IBM mainframe at Stanford (1969). A glutton for
punishment, he then moved on (during high school, 1970s) to early HP
timeshared systems, People's Computer Company's PDP8s, and various
of those they'll-never-fly-Orville microcomputers at the storied
Homebrew Computer Club -- then more Big Blue computing horrors at
college alleviated by bits of primeval BSD during UC Berkeley summer
sessions, and so on. He's thus better qualified than most, to know just
how much better off we are now.
When not playing Silicon Valley dot-com roulette, he enjoys
long-distance bicycling, helping run science fiction conventions, and
concentrating on becoming an uncarved block.
Rick has run freely-redistributable Unixen since 1992, having been roped
in by first 386BSD, then Linux. Having found that either one
sucked less, he blew
away his last non-Unix box (OS/2 Warp) in 1996. He specialises in clue
acquisition and delivery (documentation & training), system
administration, security, WAN/LAN design and administration, and
support. He helped plan the LINC Expo (which evolved into the first
LinuxWorld Conference and Expo, in San Jose), Windows Refund Day, and
several other rabble-rousing Linux community events in the San Francisco
Bay Area. He's written and edited for IDG/LinuxWorld, SSC, and the
USENIX Association; and spoken at LinuxWorld Conference and Expo and
numerous user groups.
By Ben Okopnik
Over the years of using computers, as well as in the process of growing older and more forgetful, I've discovered the value of having quick, focused ways of accessing important information. As an example, I have a password-protected, encrypted file containing my passwords and all the information related to them (i.e., hostname, username, security questions, etc.), as well as a script that allows me to look up the information and safely edit it; I also have a quotations file that I've been assembling for the last 20-plus years, and a script that looks up the quotations and lets me add new ones easily. In this article, I'll show yet another, similar script - one that lets me keep track of often-used commands and various tips and tricks that I use in Linux, Solaris, and so on.
For those familiar with database terminology, this is a minimal version of
a CRUD
(create, read, update, and delete) interface, minus the 'delete' option -
as an old database administrator, I find even the thought of data deletion
distasteful, anyway.  Updating is a
matter of adding a new entry with a distinct search string - and if you've added
something that you decide you don't need later, all you have to do is not look
it up.
Updating is a
matter of adding a new entry with a distinct search string - and if you've added
something that you decide you don't need later, all you have to do is not look
it up.
One of the things I've found out in writing and using this type of script is that there are pitfalls everywhere: any time you write something that takes human-readable information and tries to parse it, you're going to run into interface problems. Not only are the data items themselves suspect - although that's not an issue in this case, where the information is just a textual reminder - but also the user interaction with the script has edge cases all over the place. As a result, 99% of this script is tests for wrong actions taken by the user; the actual basic function of the script is only about a dozen lines. The most amusing part of how things can break is what you get after a while of not using the script and forgetting its quirks: even I, its author, have managed to crash it on occasion! These were always followed by half-amused, half-frustrated muttered curses and fixes - until there wasn't anything left to fix (at least, based on the problems that I could stumble across, find, imagine, or create.) As always, I'd appreciate feedback, if anyone discovers a problem I haven't found!
On my system, the script is simply called 'n' - as I recall, I was originally thinking of 'note' at the time that I named it. You can download the latest version from here, although the one on the LG server isn't likely to go stale any time soon; this script hasn't changed in quite a while.
The run options for this script are deceptively simple, and can be seen by invoking it with '-h' or '--help' as an argument:
ben@Jotunheim:~$ n -h n [-h|--help] | [section] [comment_search_string] If invoked without any argument, asks for the section and entry text to be added to the data file. If an argument is provided, and matches an existing section, that entire section is displayed; if two arguments are supplied, displays the first entry matching arg[2] in the section matching arg[1].
Here's an example of adding a new entry:
ben@Jotunheim:~$ n Current sections: awk date find grep mencoder misc/miscellany/miscellaneous/general mount mp3/ogg/wav mplayer netstat perl shell/bash/ksh sort tcpdump vi/vim whois Please enter the section to update or a new section name: perl Please type in the entry to be added to the 'perl' section: # Interactive Perl debugger perl -d scriptname ben@Jotunheim:~$
Note that each entry requires a comment as its first line, and is terminated by a blank line. The comment may be continued on the subsequent lines, and is important: the default action for lookup (this may be changed via a setting in the script) is to search only the comment when the script looks for a specific entry in a given section. In other words, if I wanted to find the above entry, I'd search for it as
n perl debug
This would return every entry in the 'perl' section that contained 'debug' in the comment. If you wanted a "looser" type of search, that is, one which would match either the comment or the content, you could change the 'search_opt' variable near the top of the script as described there. Personally, I prefer the "comment-only" search - but, in this, I'm taking advantage of my "Google-fu", that is, my ability to formulate a good search query. The trick is that I also use the same thing, the same mode of thinking, when I create the comment for an entry: I write comments that are likely to match a sensibly-formed query even if I have absolutely no memory of what I originally wrote.
So far, so simple - but that's not all there is to it. The tricky part is the possibly-surprising features that are a natural consequence of the tools that I used to write the script. That is, since I used the regex features of 'sed' to locate the sections and the lines, the arguments provided to the script can also be regexes - at least, if we take care to protect them from shell expansion by using single quotes around them. With those, this script becomes much more useful, since you can now look for more arbitrary strings with more freedom. For example, if I remember that I had an entry mentioning 'tr' in some section, I can tell 'n' to look for 'tr' in the comment, in all the sections:
n '.*' tr
However, if the above search comes back with too many answers (as it will, since 'trailing', 'matrix', 'control', and so on will all match), I can tell 'n' to look for 'tr' as a word - i.e., a string surrounded by non-alphanumeric characters:
n '.*' '\<tr\>'
This returns only the match I was looking for.
I can also look for entries in more than one section at once, at least if I remember to use 'sed'-style regular expressions:
n 'perl\|shell' debug
This would search for any entry that has 'debug' in the comments, in both the 'perl' and 'shell' sections.
This can also go the other way:
n perl 'text\|binary'
Or even:
n 'awk\|perl' 'check\|test'
One of the convenient options, when creating a new section, is to use more than one name for it - that is, there may be more than one section name that would make sense to me when I'm thinking of looking it up. E.g., for shell scripting tips and tricks, I might think of the word 'shell' - but I might also think of 'bash', 'ksh', or even 'sh' first. (Note that case isn't an issue: 'n' ignores it when looking up section names.) What to do? Actually, this is quite easy: 'n' allows for multiple names for a given section as long as they are separate words, meaning that they are delimited by any non-alphanumeric character except an underscore. So, if you name a section 'KSH/sh/Bash/shell/script/scripting', any one of these specified as a section name will search in the right place. Better yet, when you add a new entry, specifying any of the above will add it in the right place.
Since the data is kept in a plain text file, you can always edit it if you make a mistake. (The name and the location of the file, '~/.linux_notes', is defined at the top of the script, and each user on a system can have one of their own - or you could all share one.) Just make sure to maintain the format, which is a simple one: section names start with '###' at the beginning of the line, comments start with a single '#', and entries and sections are separated by blank lines. If you do manage to mess it up somehow, it's not a big deal - since the file is processed line by line, every entry stands on its own, and, given the design of the script, processing is fairly robust. (E.g., multiple blank lines are fine; using multiple hashes in front of comments would be OK; even leaving out blank lines between entries would only result in the 'connected' entries being returned together.) Even in the worst case, the output is still usable and readable, and any necessary fixes are easy and obvious.
One of the things I'd like the readers of LG to take home from this article is the thought of 'n' as a starting place for their own future development of this type of scripts. There are many occasions when you'll want an "update and search interface", and this is a model I've used again and again in those situations, with only minimal adjustments in all cases. Since this script is released under the GPL, please feel free to tweak, improve, and rewrite it however you will. Again, I'd appreciate being notified of any interesting improvements!
Talkback: Discuss this article with The Answer Gang

Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity at the tender age of six, promptly demonstrated it by sticking a fork into a socket and starting a fire, and has been falling down technological mineshafts ever since. He has been working with computers since the Elder Days, when they had to be built by soldering parts onto printed circuit boards and programs had to fit into 4k of memory (the recurring nightmares have almost faded, actually.)
His subsequent experiences include creating software in more than two dozen languages, network and database maintenance during the approach of a hurricane, writing articles for publications ranging from sailing magazines to technological journals, and teaching on a variety of topics ranging from Soviet weaponry and IBM hardware repair to Solaris and Linux administration, engineering, and programming. He also has the distinction of setting up the first Linux-based public access network in St. Georges, Bermuda as well as one of the first large-scale Linux-based mail servers in St. Thomas, USVI.
After a seven-year Atlantic/Caribbean cruise under sail and passages up and down the East coast of the US, he is currently anchored in northern Florida. His consulting business presents him with a variety of challenges such as teaching professional advancement courses for Sun Microsystems and providing Open Source solutions for local companies.
His current set of hobbies includes flying, yoga, martial arts,
motorcycles, writing, Roman history, and mangling playing
with his Ubuntu-based home network, in which he is ably assisted by his wife and son;
his Palm Pilot is crammed full of alarms, many of which contain exclamation
points.
He has been working with Linux since 1997, and credits it with his complete loss of interest in waging nuclear warfare on parts of the Pacific Northwest.
I've been a Linux user for almost fifteen years, and a digital photography enthusiast for about ten. I bought my first digital camera back in the late 90s while in college, which I used mostly for sharing pictures of my family with my parents, who live in Brazil. About five or six years ago, I crossed the line from family photos to photography as a hobby. I still cannot quite put into words exactly what photography means to me. All I can say is that it is a form of art, and I find it beautiful and inspiring. One of the things I have discovered throughout the years is that a lot of photography is not about having the big, expensive equipment, but being at the right place at the right time. The trick sometimes is realizing that you are there.
That is when I started to carry my camera with me more often. I started
carrying it around with me everywhere I went; from going to work to getting
my car's oil changed at the local mechanic. I got so used to carrying it
around with me that I became a fan of compact, point-and-shoot cameras: I
could simply carry it in my jeans pocket, and pull it out anytime I thought
a moment was worth capturing. Believe it or not, I decided to purchase
a 'bigger, better' camera only just a couple of months ago, and I have finally made
the transition to a DSLR camera, which has provided me with quite a bit of
flexibility to shoot photos -- yet, not as easy to drag around everywhere I
go, and that is why, even with my DSLR, I still keep my point-and-shoot
around. Even though it is rare, there have been occasions where I was
presented with a moment that I so desperately wanted to capture that I
even used my cellphone camera to do so. That is how desperate I get to take
photos.
In this article, I will attempt to share with you how I use Linux to manage, edit, and share my photos. With that said, I will warn you right now that I am not a professional photographer: it is something I enjoy, something I am constantly learning about, yet what I do with my photos may or may not be what a professional photographer would recommend.
So, how does one start talking about all that? Since I am not quite sure, I decided to just pick a starting point: equipment.
Currently, I have three different devices to take photos. They are:
Yes, you read it right, I consider my cellphone's built-in camera good enough to be part of my hobby in photography. The one thing that all of the above devices have in common is that Linux, at least my distribution of choice (Fedora Linux), recognizes all of them as storage devices -- and GNOME, my desktop manager of choice, automatically prompts me to import the photos directly from my phone or SD Cards via gthumb . In this very first step of importing my photos, I must decide two things:
First, the directory structure in which I am going to save my photos: I usually archive my photos based on the dates I have taken them, using the 'YYYYMMDD' format. For example, the photos I transferred today were saved under ~/Pictures/20091101. The second decision is whether I want to keep the original photos on my SD card or delete them after the transfer is complete. I usually delete them.
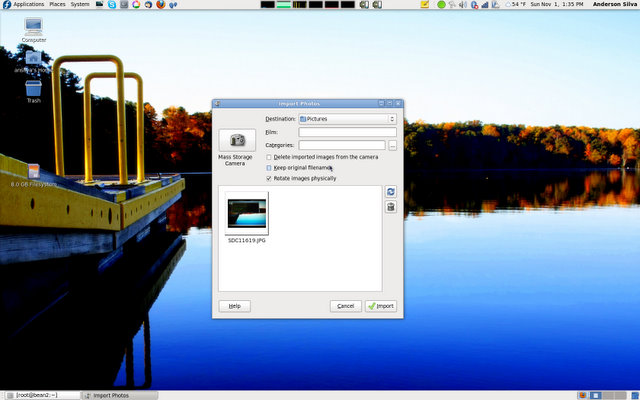
Once you have your photos on your file system, you have a few choices of applications to manage your work. I personally prefer using Google's Picasa - but it is not open source, usually lags behind the Windows version, and uses a customized version of WINE to run. In this article, I am only going to discuss using Picasa, but if you want to stick with 100% open-source solutions, take a look at: F-Spot, Shotwell, and DigiKam, which I will actually mention a bit more, later on.
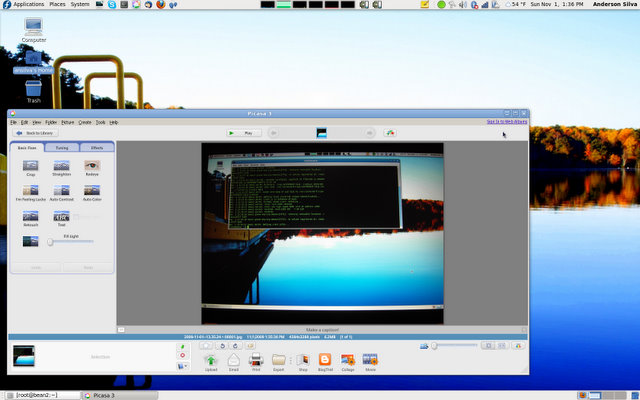
There are four simple, main reasons why I use Picasa over an alternative open-source application:
Once I have all my photos organized, edited, and tweaked on Picasa, I usually ask myself one question: Is this a photo I want to share with my family or with the world? If the answer is 'family', and most of them are, I usually select the photos in question and upload them to Picasa Web Album. Now, if the answer is 'world,' at least three things will happen:
In the world of digital photography, it is very hard to carry out a
conversation or write an article without mentioning Adobe Photoshop.
Virtually all professional photographers use it, and a lot of hobbyists do
as well. In our world, the Open Source world, there have been many
discussions and articles about where The GIMP
can and cannot fill the void for Photoshop users. This article is not
about that, since I am not good enough with either The GIMP or Photoshop. I can
use both just enough to be dangerous, but not enough to be good.
One of my favorite tricks to use with The GIMP, which works almost the same way in Photoshop, is to create a duplicate layer of the photo you are editing, and then:
The result is usually a ghostly, foggy photo that adds a lot of emotion to your shot. If the photo turns out too dark, I also tweak the Opacity slide bar right underneath the Layer Mode.
The above photo was also created in The GIMP by creating multiple duplicate layers of a color photo and a black and white photo, and using the magic wand to erase certain areas of the black and white photo exposing the color underneath.
One special type of photos that I have started working on recently is panoramic photos , a technique for capturing photos with an 'elongated field of view.' The proper way to create usually requires setting the camera in the portrait position (AKA standing up) on a rotating-head tripod, and taking a series of overlapping photos of your subject. Then, you download your shots and stitch your photos together with some specialized piece of software. I don't have a tripod (yet), but still have fun putting these together.
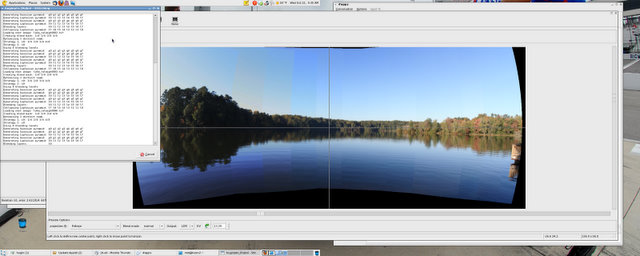
The above is my attempt to create a panoramic photo of Lake Raleigh, NC. It took a total of thirteen shots and using the Open Source application hugin, which is available for most current Linux distributions as well as for other operating systems. Some distributions may not include the 'auto-stitch' feature, which basically just means you have to go through your photos and add common points between your photos so the program can stitch each photo correctly.
Above is the final result.
How many of you are on Facebook? Linux Gazette is (see: http://www.facebook.com/group.php?gid=110960368283 ). As I said in the beginning, I even use my cellphone to take photos, more often than not the photos taken with my cellphone get uploaded directly to Facebook, never to be shared with anyone outside of my friends list. But sometimes, I do want to share them on Picasa Web Album or Flickr, and the original from the cellphone is no longer there.
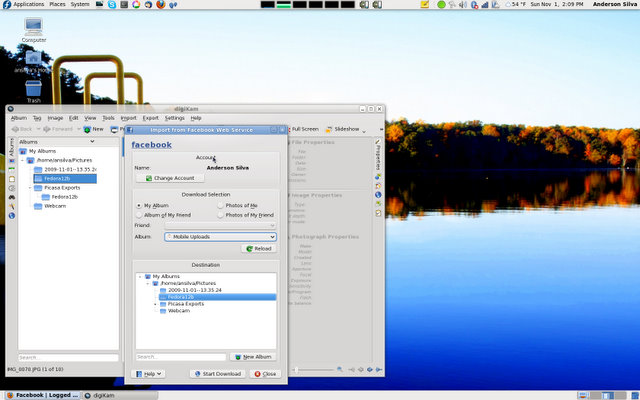
The solution is to use the kipi-plugins on digiKam, and import your Facebook photos. It is a great way to recover old cellphone photos, and to backup any other photos that may have been uploaded to Facebook.
The next technique that I would like to play with, in photography, is High Dynamic Range (HDR) image processing, which is a way to "allow a greater dynamic range of luminances between the lightest and darkest areas of an image". The open source application that I will be working with is qtpfsgui, and when I do have some decent results to show off, I will surely write up some steps on how to get them working.
And finally, if you are interested in learning more about photography and terms like aperture, exposure, wide angle and telephoto, I highly recommend Volumes 1, 2, and 3 of The Digital Photography Book by Scott Kelby. It will give you several tips on what type of techniques, software, and hardware the professional photographers are using in the 'real' world. Enjoy!
[ Keeping one's own photographs in order is an important task. In case you want to automatically rename your digital images using metadata from the camera itself you might want to check out the jhead tool, which can query and modify the JPEG header and EXIF information. -- René ]
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/silva.jpg)
Anderson Silva works as an IT Release Engineer at Red Hat, Inc. He holds a BS in Computer Science from Liberty University, a MS in Information Systems from the University of Maine. He is a Red Hat Certified Engineer working towards becoming a Red Hat Certified Architect and has authored several Linux based articles for publications like: Linux Gazette, Revista do Linux, and Red Hat Magazine. Anderson has been married to his High School sweetheart, Joanna (who helps him edit his articles before submission), for 11 years, and has 3 kids. When he is not working or writing, he enjoys photography, spending time with his family, road cycling, watching Formula 1 and Indycar races, and taking his boys karting,
By Ken Starks
This is not meant for Linux users' consumption. Rather, it is meant to be passed along to your friends who still use Windows. It has some irrefutable arguments within.

Idiot...
That's a fairly strong word. I can't think of a situation where most people would not find it offensive.
Or rude.
Let me tell you something else that is rude; the offensive part I will leave to personal opinion.
Asking a friend to repeatedly fix your computer.
Not "fix" as in "something inside the computer broke" - like a hard drive, or a power supply.
I'm talking about your forays into Myspace and astalavista.box.sk.
I'm talking about having to repeatedly clean the garbage off your computer so it will run halfway decently again.
You seem to have no shame when it comes to this.
I personally stopped "fixing" Windows computers three years ago. That included my wife's computer. Ahem... now my ex-wife, but that goes a bit farther than the scope of this discussion.
See, many of us have found a way to run our computers where we don't have to worry about that crap anymore.
Ever.
Many of us have told you of this miraculous operating system and have gone as far as to offer to install it on your computer for you... free of charge.
For many of us, the motive is far from altruistic.
We're sick of cleaning up your messes. If we install GNU/Linux and free software on your computer, we simply won't have to be bothered again. I don't speak for all Linux users, but enough of them to hear the applause in the background.
And trust me, it is a bother, whether we verbalize it or not.
In 2004, a variant of the Sasser worm infected my three-city network, and, by the time the dust settled, had cost me $12,000.00 in business. My machines were fully protected and fully patched. See, that's the problem with Windows exploits. These viruses and worms mutate quicker than the anti-virus software makers can issue the fixes. In my case, Symantec was 72 hours away from fixing this variant. I was one click away from disaster.
It's convenient to blame the virus writers and anti-virus software makers, but ultimately it is your fault that you get this crap on your machine. You are using a system that not only allows it: It fosters it. Let it be known that, by reading further, you will learn that you have a choice in how you operate your computer. A free-as-in-cost and free-as-in-no-restrictions choice.
You will no longer be able to identify yourself as a victim.
The cost I incurred was in business loss. Today's viruses are not in it for the mischief: They are in it for the money.
These people are not going to stop. They are stealing billions of dollars a year by infecting your computers. There is too much money in this for them to even think about taking a break. What's worse, they are operating out of Russia and Nigeria for the most part: We can't get to them, to stop them.
Yeah. It's not going to happen to you, is it?
Right.
It wasn't going to happen to me either.
Linux is an alternative operating system much like Microsoft Windows -- and no, it's not a "program". "Programs" run within an operating system. Think of it as a walnut. The shell of the walnut is your operating system. The goods within the walnut shell are the programs.
I'll not bore you with the details. If you are interested in finding out why Linux is safer and better, you can go here, here and here. There is a fairly comprehensive explanation as to why you don't need anti-virus software here. Here is an article from a long-time Mac and Windows user who has seen the superiority of Linux, and has put it on his own computer.
But this isn't a lesson on computer usage.
It's a wakeup call for common sense.
Did you know that most computer repair shops, once they "repair" your system, project future profits based on the fact that you use Microsoft Windows? They know for a fact that you are going to need them again in six months.
They put their kids through private schools and upper-crust colleges because you are a Microsoft Windows User and are not able to adequately protect your computer.
It's getting harder and harder to do so. And don't look to Windows 7 for your salvation: You will still need to load your system with the same anti-virus garbage and registry cleaners you did with XP and Vista. There's an even-money chance that they are going to fail anyway. So you've paid for what?
There is however, a thin line between being a victim and being an idiot. If you do not know you have a choice and bad things happen to you, then you are a victim.
If you know you have a choice and still insist on personally using a system over and over again that will ultimately lead to the same problems....
I think the descriptor of idiot is fair.
You disagree? You know that Windows is the problem...you know that it's just a matter of time before you have to do it all over again. You know you have an alternative, but you insist on putting the source of the problem back on your computer. You may be uncomfortable with the term "idiot": You give me another name for it, then.
And if you have to use it at work, I understand. Unfortunately, as flawed as it is, it is still a Windows world. The good news? Slowly but surely, businesses across the globe are making the switch. Even those that are not yet Linux companies are letting some employees run their choice of operating systems on their work computers. That choice is Linux.
Look. Here is the way it is.
When you buy a new computer, chances are it will have Microsoft Windows on it. That didn't come free: The price of the computer is jacked up anywhere from $100.00 to $300.00 to pay Microsoft. It's known as the Microsoft Tax. Microsoft has entered into deals with many of the computer manufacturers to ensure that Windows is on about every machine they sell. The kicker here? Those agreements are secret and you and I cannot see them. We've written about this before.
Microsoft has a virtual monopoly on new computer sales.
Now there are independents such as zareason.com that sell nothing but GNU/Linux computers, and they are great folks to deal with. In fact, I have never encountered service like what Earl and Cathy Malmrose provide -- and, for the most part, they provide it for free. Dell has also begun selling Linux computers. Do you think Dell would sell a system on their machines that would cause them to lose money or damage their reputation?
When you call Microsoft for support, the first thing they ask for is a credit card.
So, suppose you have bought a new computer and here comes the first 90 days: You start getting pop-ups saying your anti-virus protection is about to expire and that, if you want to continue to "be protected", you need to renew your subscription.
What?
Yep, now some anti-virus companies go an entire year before they expire but still: Eventually, you are going to be frightened into shelling out more money in exchange for your peace of mind.
In other words, you have to purchase software to ensure that the software you've already purchased is going to work. Did you read that carefully? And you are okay with that?
If I did that, I'd be in jail by now... and so would you.
Linux amputates that part of the computing experience completely. Some people cannot get their heads around the fact that they don't need to pay this extortion fees anymore. You have no idea what a sense of liberation this brings. Now some of you are sure to comment:
"I've run Windows for years without a problem."
Congratulations. You wanna Google it and see how many others have not? I suppose as long as your computer is okay, then all is right with the world.
We can open almost any attachment without fear. We can visit Web sites that will bring a Windows machine to its knees -- and we don't notice anything. And please, don't be foolish and say that Linux is too hard for the normal Windows user. We have 10 and 12 year-olds picking it up in a couple of hours: They never look back. Entire nations have already switched or are in the process of switching to Linux. Many countries in Asia and South America have made the switch. India is booting out Microsoft in their schools and migrating to Linux, as we speak.
So. You've been told. You do have a choice, and it doesn't cost you one thin dime. If you choose not to at least look into it, and trust me, most of you won't, don't ask us to come fix your infected computers.
We know which side of that thin line you stand on.
EDIT: A friend of boh was kind enough to send us this faux-sign...just
seemed to fit the theme of the day.
[ While a long-time GNU/Linux user myself, I would add that there's something to be said about a product's built-in security features. Most operating systems, and the software running on top of them, have bugs that need to be reported, fixed and patched. Few users realise the effort behind this process, and rely on the automatic updates they receive. (This is true for many users of free software and proprietary software alike.) Measuring the security record of a computer system depends on a lot of additional factors, not only on the operating system alone. Attackers concentrate on common OS types that are well accessible. Currently, this is Microsoft Windows. Tomorrow, it could be a different OS. This does not mean that other platforms do not need any protection at all - on the contrary: All systems require a thoughtful and well-planned deployment, when it comes to security. -- René ]
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/starks.jpg)
Ken Starks is the Founding Director of The HeliOS Project. The HeliOS Project rebuilds computers to current technology standards and gives them to financially disadvantaged children in the Central Texas area. He lives in Austin, Texas and has been active in other projects such as Lindependence and The Tux500 project. Ken is a long-time advocate for the Linux Desktop and has made it the top priority in his life. The HeliOS Project is entering its fifth year in May of 2010 and to date, this effort has provided just over 1000 computers to those that need them most. Ken outlines the mission of his Texas non-profit in simple terms:
"A child's exposure to technology should never be predicated on the ability to afford it."
These images are scaled down to minimize horizontal scrolling.
Flash problems?All HelpDex cartoons are at Shane's web site, www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
 Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
More XKCD cartoons can be found here.
Talkback: Discuss this article with The Answer Gang
I'm just this guy, you know? I'm a CNU graduate with a degree in physics. Before starting xkcd, I worked on robots at NASA's Langley Research Center in Virginia. As of June 2007 I live in Massachusetts. In my spare time I climb things, open strange doors, and go to goth clubs dressed as a frat guy so I can stand around and look terribly uncomfortable. At frat parties I do the same thing, but the other way around.
These images are scaled down to minimize horizontal scrolling.
All "Doomed to Obscurity" cartoons are at Pete Trbovich's site, http://penguinpetes.com/Doomed_to_Obscurity/.
Talkback: Discuss this article with The Answer Gang
Born September 22, 1969, in Gardena, California, "Penguin" Pete Trbovich today resides in Iowa with his wife and children. Having worked various jobs in engineering-related fields, he has since "retired" from corporate life to start his second career. Currently he works as a freelance writer, graphics artist, and coder over the Internet. He describes this work as, "I sit at home and type, and checks mysteriously arrive in the mail."
He discovered Linux in 1998 - his first distro was Red Hat 5.0 - and has had very little time for other operating systems since. Starting out with his freelance business, he toyed with other blogs and websites until finally getting his own domain penguinpetes.com started in March of 2006, with a blog whose first post stated his motto: "If it isn't fun for me to write, it won't be fun to read."
The webcomic Doomed to Obscurity was launched New Year's Day, 2009, as a "New Year's surprise". He has since rigorously stuck to a posting schedule of "every odd-numbered calendar day", which allows him to keep a steady pace without tiring. The tagline for the webcomic states that it "gives the geek culture just what it deserves." But is it skewering everybody but the geek culture, or lampooning geek culture itself, or doing both by turns?
Thomas Adam [thomas.adam22 at gmail.com]
2009/12/3 C. Riley <crileyjm@gmail.com>:
> "you can carry cow to water's edge, but you can't force it to drink".
Haha. You mean horse. But this did make my day though, thanks.
-- Thomas Adam
[ Thread continues here (7 messages/4.92kB) ]
Jimmy O'Regan [joregan at gmail.com]
---------- Forwarded message ----------
From: Jimmy O'Regan <joregan@gmail.com> Date: 2009/12/5 Subject: Re: Apertium-en-es 0.7.0 To: Apertium-stuff <apertium-stuff@lists.sourceforge.net>
2009/12/5 Jimmy O'Regan <joregan@gmail.com>:
> I've just released en-es 0.7.0. I'm not a big fan of release notes, so
> here's the changelog:
>
> Sat Dec 5 15:23:45 GMT 2009
>
> * Release 0.7.0 ('More of an escape than a release')
> * Vastly improved handling of Anglo-Saxon genitive in transfer (Mireia)
> * 'Apostrophe genitive' (Jesus' etc.) in analysis
> * Pre-transfer processing of apostrophes/genitive (based on an idea by
> Jacob Nordfalk/Francis Tyers)
> * Greatly increased vocabulary (most notably, Paul "greenbreen" Breen)
>
> In addition, this version has some generation support for the two main
> dialects of English, British and American, though this only currently
> supports simple spelling differences for the moment ('favour' vs.
> 'favor').
>
Oh, and because I like to collect amusing translation errors, this error from 0.6 is fixed in 0.7:
0.6, es->en 'Fondo Monetario Internacional' -> 'International Monetary bottom' 0.7, es-en 'Fondo Monetario Internacional' -> 'International Monetary Fund'
[ Thread continues here (3 messages/6.52kB) ]
Jimmy O'Regan [joregan at gmail.com]
http://www.bobhobbs.com/files/kr_lovecraft.html
"Recursion may provide no salvation of storage, nor of human souls; somewhere, a stack of the values being processed must be maintained. But recursive code is more compact, perhaps more easily understood– and more evil and hideous than the darkest nightmares the human brain can endure. "
-- <Leftmost> jimregan, that's because deep inside you, you are evil. <Leftmost> Also not-so-deep inside you.
[ Thread continues here (2 messages/1.91kB) ]
By Ben Okopnik
Ever since I took over running the Linux Gazette, I've found it to be a fascinating experience: it's presented me with a variety of surprises, required a lot of hard thinking about the larger issues as well as dealing with problems that pop up out of nowhere and demand immediate action - and much of it has been just plain hard work. It's also been a blast - and I'm so grateful to my fellow contributors, staff and authors both, that words fail me in trying to express it adequately (and that's quite the statement for someone who considers himself a crafter of words and a lover of language!) To all of you who have made LG what it is, I'm truly grateful - both as a Linux user and as the Editor-in-Chief. Doubly so as the latter, since your contributions have built LG into a fun, useful, informative vehicle for sharing Linux info and thereby gave me a chance to explore my own abilities and experience my own limitations (as a friend of mine was fond of saying when speaking of painful experiences, "...and much learning occured therefrom.") If you hold learning in the same regard and respect as I do - and having been a teacher during most of my professional life, as well as always believing that education is one of the keystones to a better future for the entire world, I hold it in high esteem indeed - that is one of the best gifts one could ever receive.
This does not, however, mean that there are no problems or difficulties
here. If anything, it means that there are more of them than ever
- and that they mutate in shape, size, charm, spin, and flavor. Daily.
As you probably already know, good system design requires feedback; without it, control input means little or nothing, and such systems either spend most of their time idle or shift into destructive run-away conditions and fail, sometimes spectacularly and with much attendant fallout. For any publication, that feedback is very important; For a web-based, volunteer effort like ours, it's critical. And yet...
I'm not a marketing guru; far from it. In fact, I know next to nothing when it comes to promoting LG or getting its name out there, beyond doing the best job I can of putting out a quality publication. I am, however, very aware that this is not all there is to running a publication like LG... and I feel that lack quite strongly and am rather troubled by my inability to figure out a strong, direct method of addressing it.
In short, it boils down to the question of "can a volunteer-run publication survive and prosper in a world of glitzy commercial ones, and can it continue to provide quality content without sponsorship?" I feel sure that it can - but despite having put a lot of thought into it, I don't (yet) know what that means in terms of direction, planning, or action. If any of you, dear readers, have relevant ability or expertise, your advice and help would be much appreciated.
Last month, in this very space, I asked for you, our readers, to write in; to let us know that you were reading LG, that it mattered to you - in short, to tell us whether LG's continued existence was a value to the Linux community, as I believe it is. The response has been nothing short of phenomenal and tremendously heartening: for the last month, I've been buried under a huge pile of supportive email from all over the world, with a number of offers of help and ideas for improvement. It was amazing to see, and again, all of you have my thanks.
One thing stands out most clearly, though: it seems that we are "pricing ourselves out of the market" by producing content with great quality. It's funny when you think about it - and not a little aggravating when seen from another perspective.
You see, at the end of every month, our editors and proofreaders put in a lot of work to polish all those articles - and after they're done, I and my wife go over them with a fine-tooth comb to make sure that they're as readable and as clear as possible. At times, that last edit can be like sweating blood, and can involve anything from basic spelling correction to rewriting entire paragraphs to make them clearer, more comprehensible. Many of the comments that we've received contain high praise for the clarity and readability of our articles; I don't find this at all surprising, since we all put in a very large amount of work to make it so.
However, the *bad* effect here is that it makes us look so professional that many of our readers think "Wow, I could never write like that. My stuff would look really amateurish next to all these professionals. I shouldn't even bother trying! I saw a whole lot of that in the responses; lots and lots of people who would be happy to write, but... only... there's this REALLY HIGH BAR to jump over...
This is just... wrong, in many different ways and for a variety of reasons. For one, you only get to be a good writer by writing - and I like to think that, over the years, we've helped quite a number of people become good, or at least much better writers (I would like nothing better than for LG to be known, among other things, as a resource for people who want to learn to write well.) For another, your writing - yes, even yours! - can look pretty darn polished if you 1) can take criticism and 2) have a good proofreading/editing team - and we have one here, all shiny and capable and ready for your use, free of charge. Trust me, folks - that's a great offer, and if you have any aspirations as a writer and want to write about Open source topics, this is the place to do it.
Most of all - writing from the just-started, not-sure-what-I'm-doing new Linux users is what we want most desperately. Please, remember this always: LG is all about looking at the world with a fresh set of eyes. It's about exploration; it's about making mistakes and learning from them. Most of all, it's about growing by learning. Just like Linux itself, and the community around it. It's about all of us, and the force that we bring into the world to oppose the stodgy, inbred, stale world created by proprietary computing and closed-source practices. It's about the willingness to stay open, alert, and sensitive in the face of challenges, and dealing with Fear, Uncertainty, and Doubt - the weapons of the proprietary world - with courage, creativity, and laughter. It is, as I'm reminded by my 2-year-old son's outraged squeal of "mySE'F!!!" ("I'll do it myself!") when I try to do something for him that he knows how to do, about doing things your own way, in your own time - because "I'll do it instead of you" is at most a temporary good, is of limited utility, and is proper only to small children and incompetents. To have a valid claim to being an adult and a responsible human being, you have to sweat and struggle and bleed and do it all wrong, again and again - because a thousand instances of having it done for you, no matter how quickly or well, still leave you an ignorant slave, but doing it on our own even once, even in some barely-functioning fashion, grants you not only the learning experience, which you'll own for the rest of your life, but your independence and freedom.
And this is the best reason to write, contribute, and participate: we're designing, building, and maintaining freedom.
Please join us.

Talkback: Discuss this article with The Answer Gang
Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity at the tender age of six, promptly demonstrated it by sticking a fork into a socket and starting a fire, and has been falling down technological mineshafts ever since. He has been working with computers since the Elder Days, when they had to be built by soldering parts onto printed circuit boards and programs had to fit into 4k of memory (the recurring nightmares have almost faded, actually.)
His subsequent experiences include creating software in more than two dozen languages, network and database maintenance during the approach of a hurricane, writing articles for publications ranging from sailing magazines to technological journals, and teaching on a variety of topics ranging from Soviet weaponry and IBM hardware repair to Solaris and Linux administration, engineering, and programming. He also has the distinction of setting up the first Linux-based public access network in St. Georges, Bermuda as well as one of the first large-scale Linux-based mail servers in St. Thomas, USVI.
After a seven-year Atlantic/Caribbean cruise under sail and passages up and down the East coast of the US, he is currently anchored in northern Florida. His consulting business presents him with a variety of challenges such as teaching professional advancement courses for Sun Microsystems and providing Open Source solutions for local companies.
His current set of hobbies includes flying, yoga, martial arts,
motorcycles, writing, Roman history, and mangling playing
with his Ubuntu-based home network, in which he is ably assisted by his wife and son;
his Palm Pilot is crammed full of alarms, many of which contain exclamation
points.
He has been working with Linux since 1997, and credits it with his complete loss of interest in waging nuclear warfare on parts of the Pacific Northwest.

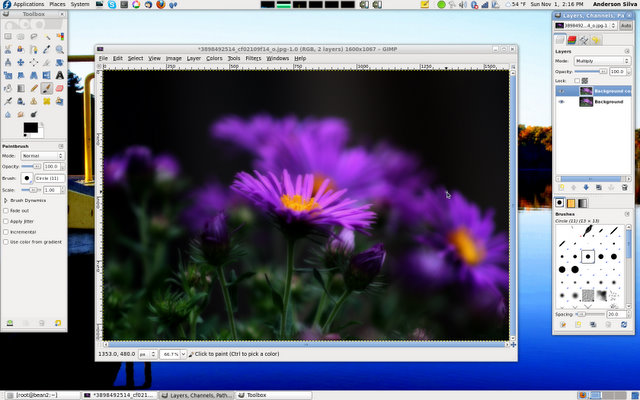


![[cartoon]](misc/xkcd/abstraction.png "If I'm such a god, why isn't Maru *my* cat?")

