
Benchmarking Filesystems
INTRO
I recently purchased a Western Digital 250GB/8M/7200RPM drive and wondered which journaling file system I should use. I currently use ext2 on my other, smaller hard drives. Upon reboot or unclean shutdown, e2fsck takes a while on drives only 40 and 60 gigabytes. Therefore I knew using a journaling file system would be my best bet. The question is: which is the best? In order to determine this I used common operations that Linux users may perform on a regular basis instead of using benchmark tools such as Bonnie or Iozone. I wanted a "real life" benchmark analysis. A quick analogy: Just because the Ethernet-Over-Power-Lines may advertise 10mbps (1.25MB/s), in real world tests, peak speed is only 5mbps (625KB/s). This is why I chose to run my own tests versus using hard drive benchmarking tools.SPECIFICATIONS
HARDWARE
COMPUTER: Dell Optiplex GX1
CPU: Pentium III 500MHZ
RAM: 768MB
SWAP: 1536MB
CONTROLLER: Promise ATA/100 TX - BIOS 14 - IN PCI SLOT #1
DRIVES USED: 1] Western Digital 250GB ATA/100 8MB CACHE 7200RPM
2] Maxtor 61.4GB ATA/66 2MB CACHE 5400RPM
DRIVE TESTED: The Western Digital 250GB.
SOFTWARE
LIBC VERSION: 2.3.2
KERNEL: linux-2.4.26
COMPILER USED: gcc-3.3.3
EXT2: e2fsprogs-1.35/sbin/mkfs.ext2
EXT3: e2fsprogs-1.35/sbin/mkfs.ext3
JFS: jfsutils-1.1.5/sbin/mkfs.jfs
REISERFS: reiserfsprogs-3.6.14/sbin/mkreiserfs
XFS: xfsprogs-2.5.6/sbin/mkfs.xfs
TESTS PERFORMED
001] Create 10,000 files with touch in a directory.
002] Run 'find' on that directory.
003] Remove the directory.
004] Create 10,000 directories with mkdir in a directory.
005] Run 'find' on that directory.
006] Remove the directory containing the 10,000 directories.
007] Copy kernel tarball from other disk to test disk.
008] Copy kernel tarball from test disk to other disk.
009] Untar kernel tarball on the same disk.
010] Tar kernel tarball on the same disk.
011] Remove kernel source tree.
012] Copy kernel tarball 10 times.
013] Create 1GB file from /dev/zero.
014] Copy the 1GB file on the same disk.
015] Split a 10MB file into 1000 byte pieces.
016] Split a 10MB file into 1024 byte pieces.
017] Split a 10MB file into 2048 byte pieces.
018] Split a 10MB file into 4096 byte pieces.
019] Split a 10MB file into 8192 byte pieces.
020] Copy kernel source tree on the same disk.
021] Cat a 1GB file to /dev/null.
NOTE1: Between each test run, a 'sync' and 10 second sleep
were performed.
NOTE2: Each file system was tested on a cleanly made file
System.
NOTE3: All file systems were created using default options.
NOTE4: All tests were performed with the cron daemon killed
and with 1 user logged in.
NOTE5: All tests were run 3 times and the average was taken,
if any tests were questionable, they were re-run and
checked with the previous average for consistency.
CREATING THE FILESYSTEMS
EXT2
root@p500:~# mkfs.ext2 /dev/hdg1
mke2fs 1.35 (28-Feb-2004)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
30539776 inodes, 61049000 blocks
3052450 blocks (5.00%) reserved for the super user
First data block=0
1864 block groups
32768 blocks per group, 32768 fragments per group
16384 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Writing inode tables: done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 31 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
root@p500:~#
EXT3
root@p500:~# mkfs.ext3 /dev/hdg1
mke2fs 1.35 (28-Feb-2004)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
30539776 inodes, 61049000 blocks
3052450 blocks (5.00%) reserved for the super user
First data block=0
1864 block groups
32768 blocks per group, 32768 fragments per group
16384 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872
Writing inode tables: done
Creating journal (8192 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 34 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
root@p500:~#
JFS
root@p500:~# mkfs.jfs /dev/hdg1 mkfs.jfs version 1.1.5, 04-Mar-2004 Warning! All data on device /dev/hdg1 will be lost! Continue? (Y/N) y \ Format completed successfully. 244196001 kilobytes total disk space. root@p500:~#
REISERFS
root@p500:~# ./mkreiserfs /dev/hdg1
mkreiserfs 3.6.14 (2003 www.namesys.com)
A pair of credits:
Nikita Danilov wrote most of the core balancing code, plugin infrastructure,
and directory code. He steadily worked long hours, and is the reason so much of
the Reiser4 plugin infrastructure is well abstracted in its details. The carry
function, and the use of non-recursive balancing, are his idea.
Lycos (www.lycos.com) has a support contract with us that consistently comes in
just when we would otherwise miss payroll, and that they keep doubling every
year. Much thanks to them.
Guessing about desired format.. Kernel 2.4.26 is running.
Format 3.6 with standard journal
Count of blocks on the device: 61048992
Number of blocks consumed by mkreiserfs formatting process: 10075
Blocksize: 4096
Hash function used to sort names: "r5"
Journal Size 8193 blocks (first block 18)
Journal Max transaction length 1024
inode generation number: 0
UUID: 8831be46-d703-4de6-abf3-b30e7afbf7d2
ATTENTION: YOU SHOULD REBOOT AFTER FDISK!
ALL DATA WILL BE LOST ON '/dev/hdg1'!
Continue (y/n):y
Initializing journal - 0%....20%....40%....60%....80%....100%
Syncing..ok
Tell your friends to use a kernel based on 2.4.18 or later, and especially not a
kernel based on 2.4.9, when you use reiserFS. Have fun.
ReiserFS is successfully created on /dev/hdg1.
XFS
root@p500:~# mkfs.xfs -f /dev/hdg1
meta-data=/dev/hdg1 isize=256 agcount=59, agsize=1048576 blks
= sectsz=512
data = bsize=4096 blocks=61049000, imaxpct=25
= sunit=0 swidth=0 blks, unwritten=1
naming =version 2 bsize=4096
log =internal log bsize=4096 blocks=29809, version=1
= sectsz=512 sunit=0 blks
realtime =none extsz=65536 blocks=0, rtextents=0
root@p500:~#
BENCHMARK SET 1 OF 4
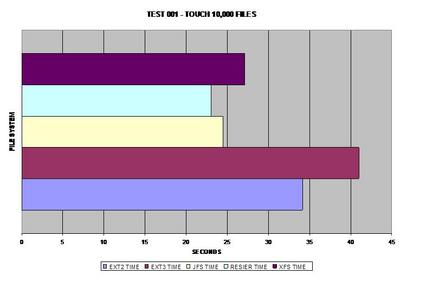
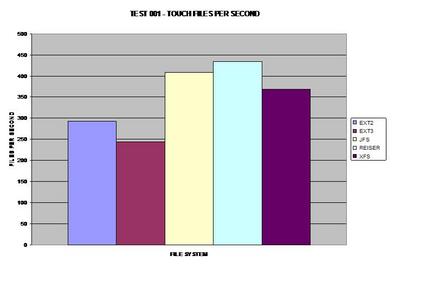
In the first test, ReiserFS takes the lead, possibly due to its
balanced B-Trees. (If the images are hard to read on your screen, here's
a tarball containing
larger versions of them.)
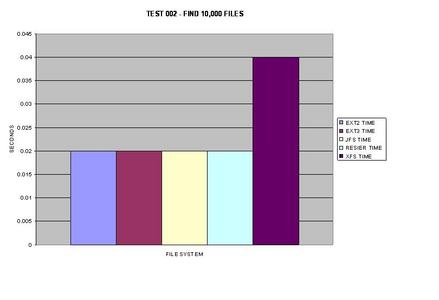
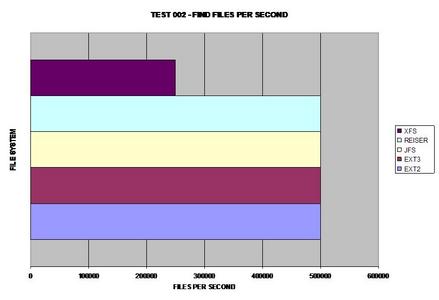
All of the files systems faired fairly well when finding 10,000
files in a single directory, the only exception being XFS which took twice as
long.
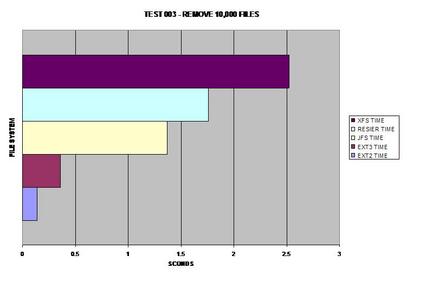
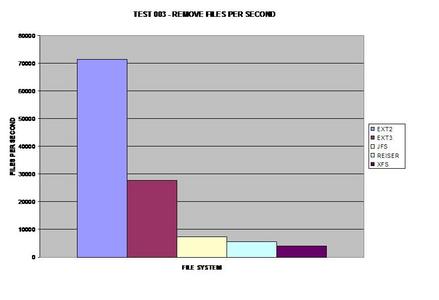
Both ext versions 2 and 3 seem to reap the benefits of removing
large numbers of files faster than any other file system tested.
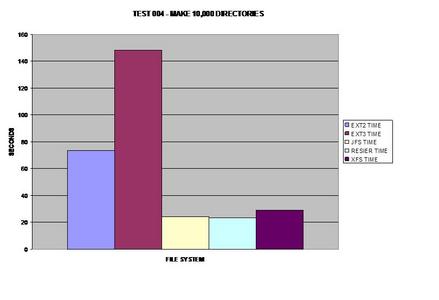
To make sure this graph was accurate; I re-benchmarked the ext2
file system again and got nearly the same results. I was surprised to find how
much of a performance hit both ext2 and ext3 take during this test.
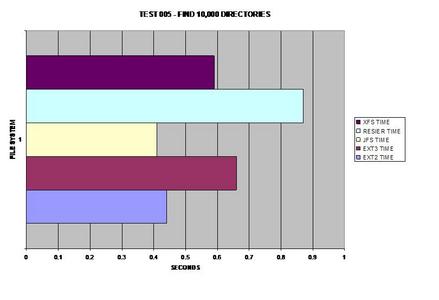
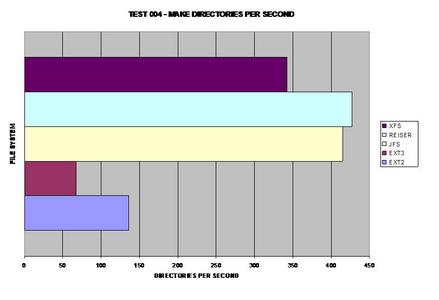
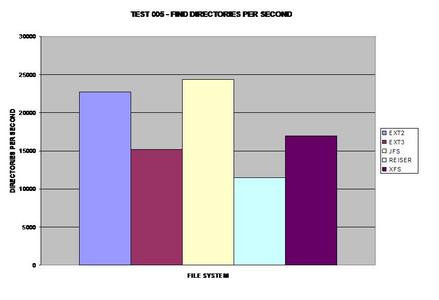
Finding 10,000 files seemed to be the same except for XFS;
however directories are definitely handled differently between the tested file
systems. Oddly enough, ReiserFS takes the largest performance hit in this
area.
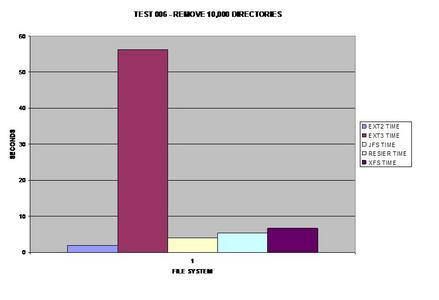
All of the file systems performed well in this area with the
exception of ext3. I am not sure what could cause such an overhead for ext3
over all of the other file systems tested.
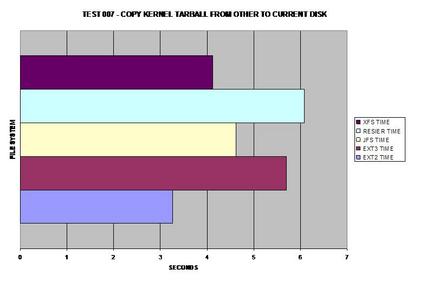
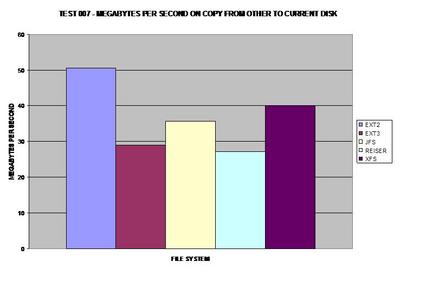
As expected, ext2 wins here because it does not journal any of
the copied data. As many would suspect, XFS handles large files well and takes
the lead for journaling file systems in this test.
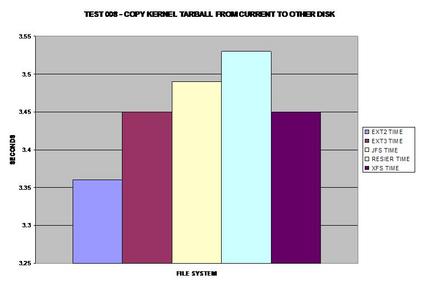
This benchmark represents how fast the tar ball can be read
from each file system. Surprisingly, ext3 matches the speed of XFS.
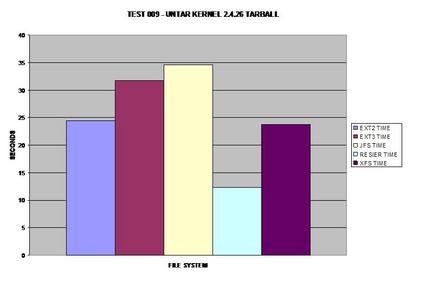
Surprisingly, ReiserFS wins, even over the non-journaling
filesystem ext2.
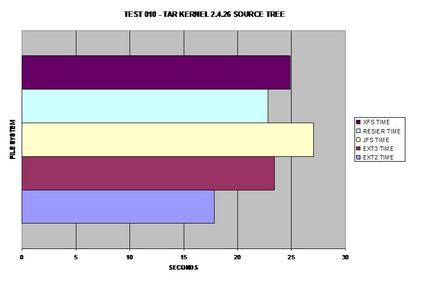
The best journaling file system here is ReiserFS; however, ext3
comes in at a close second.
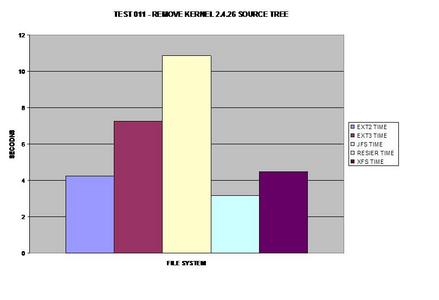
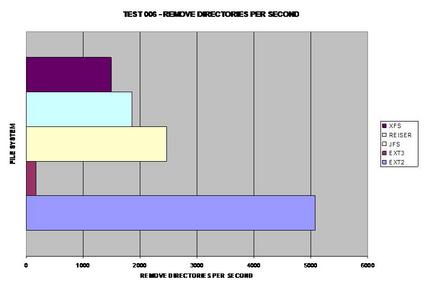
ReiserFS once again surprises everyone and takes the lead; it
appears JFS has some serious issues removing large numbers of files and
directories.
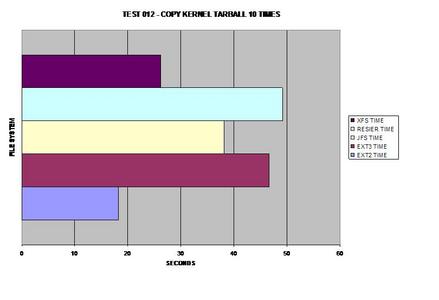
Obviously ext2 wins here as it does not need to journal its
copies but XFS is a close second, able to handle large files fairly well.
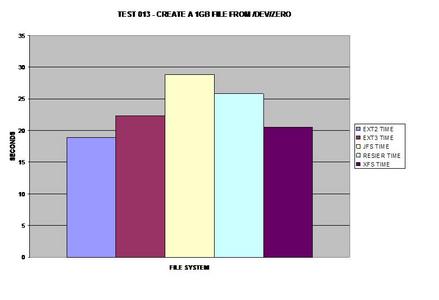
If one must deal with consistently large files, XFS seems to be
the best choice for a journaling file system.
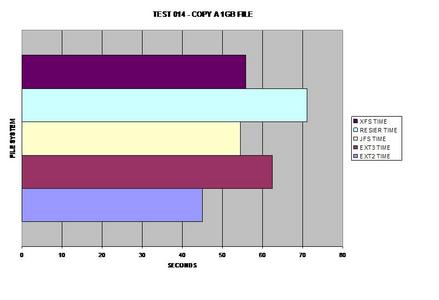
Once again on the journaling side, XFS performs well with large
files; however, JFS wins by a hair.
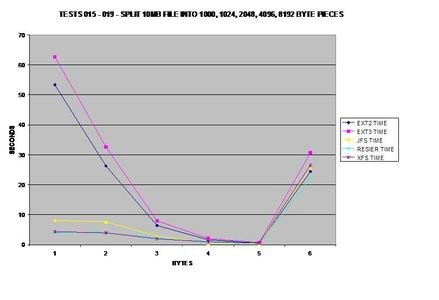
This test probably surprised me the most, so much so I re-ran
the test several times and got consistent results each time. Both ext2 and
ext3 have serious problems splitting files into small pieces, while JFS,
ReiserFS and XFS do not seem to have a problem.
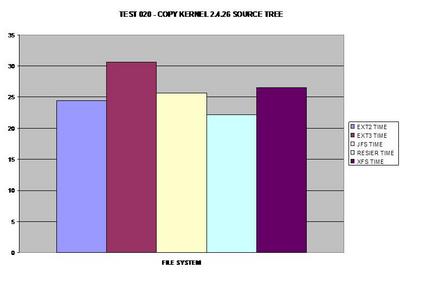
I figured people would ask for this test if I did not do it, so
here it is. It appears that ReiserFS's balanced B-Tree's allow it to
outperform all tested file systems including ext2!
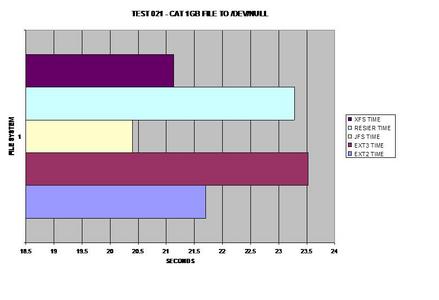
JFS takes this test benchmark by storm; I was surprised that it
had performed so well. However, once again dealing with large files, XFS is a
close second.
BENCHMARK SET 2 OF 4
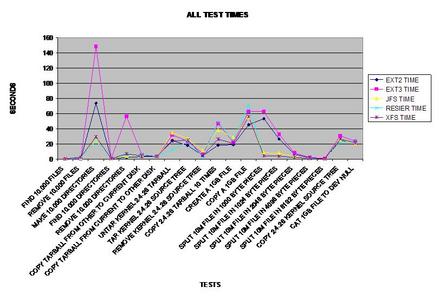
Here is a line chart of representing all of the timed tests.
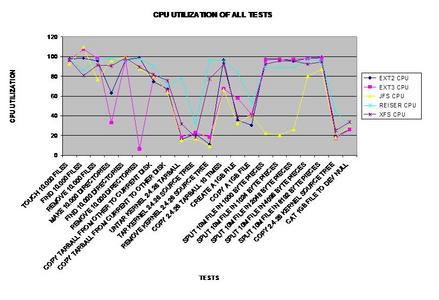
Here is a line chart representing the CPU utilized during each
test.
BENCHMARK SET 3 OF 4
A bar graph for all the timed tests.
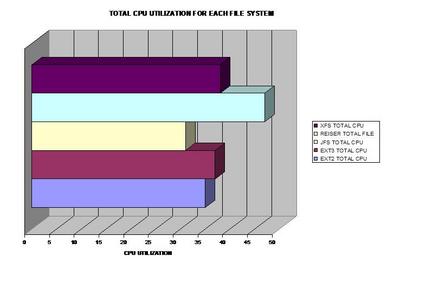
A bar graph of combined CPU usage.
BENCHMARK SET 4 OF 4
This graph was calculated by the previous tests.
This graph was calculated by the previous tests.
This graph was calculated by the previous tests.
This graph was calculated by the previous tests.
This graph was calculated by the previous tests.
This graph was calculated by the previous tests.
This graph was calculated by the previous tests.
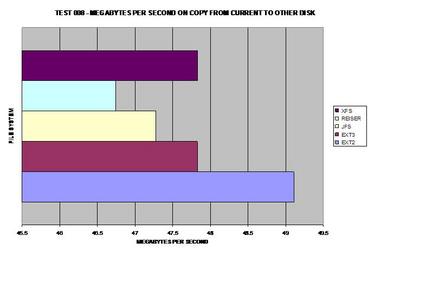
This graph was calculated by the previous tests.
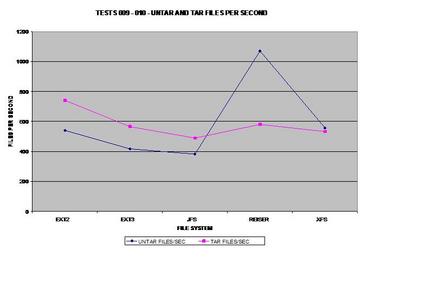
This graph was calculated by the previous tests.
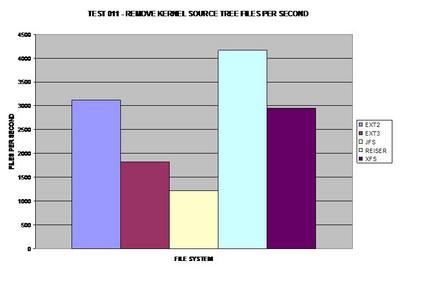
This graph was calculated by the previous tests.
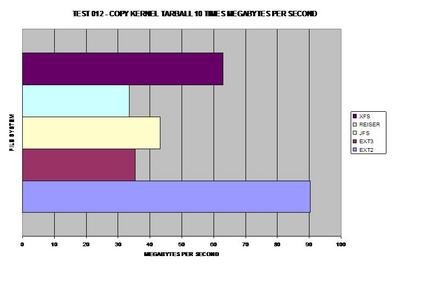
This graph was calculated by the previous tests.
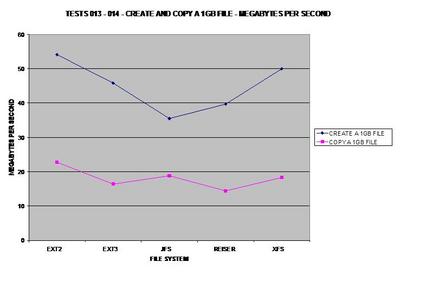
This graph was calculated by the previous tests.
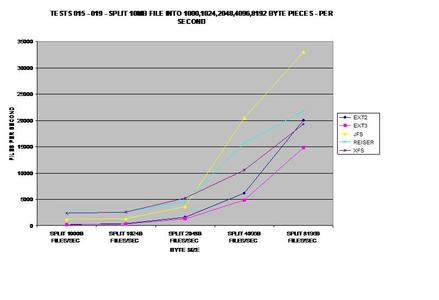
This graph was calculated by the previous tests.
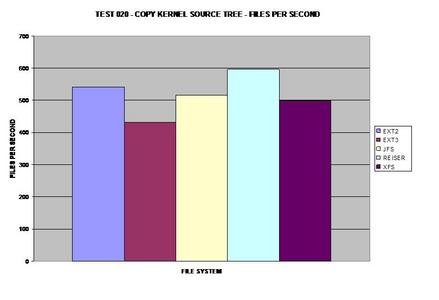
This graph was calculated by the previous tests.
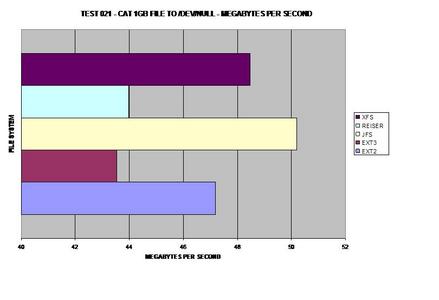
This graph was calculated by the previous tests.
CONCLUSION
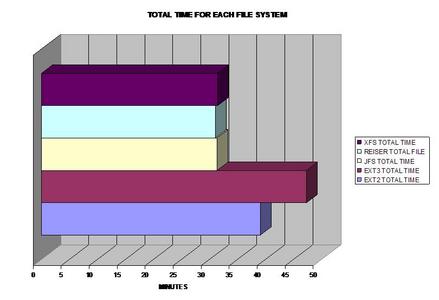
For those of you still reading, congrats! The conclusion is obvious by the "Total Time For All Benchmarks Test." The best journaling file system to choose based upon these results would be: JFS, ReiserFS or XFS depending on your needs and what types of files you are dealing with. I was quite surprised how slow ext3 was overall, as many distributions use this file system as their default file system. Overall, one should choose the best file system based upon the properties of the files they are dealing with for the best performance possible!
