
Thinking about Caching
By Pramode C.E.
Cache memory is an integral part of every modern microprocessor system. The way your program accesses memory does have an impact on run time, especially if you are accessing data sets which are bigger than what can be stored in the cache. In this article, I outline an experiment which I did on my Athlon XP system running Linux to get a `feel' of some of the performance issues associated with the cache. I wrote a simple device driver to read the Athlon performance monitoring counters. The driver monitors user-space data-cache accesses made by programs which reference a one dimensional array in different ways. The results give quantitative evidence of the importance of `locality of reference'.
Why have a cache?
Instructions (as well as data) are stored in RAM. Memory access is much slower than the CPU speed. It's possible to have faster memory - but then you can't have too much of it, as cost would be higher. The solution is (as is the case with almost all engineering solutions) a `compromise'. We keep a small amount of high speed `cache' memory - and a much larger amount of `main' memory.
In a direct mapped cache, each location in RAM is mapped to one and only one location in the cache.
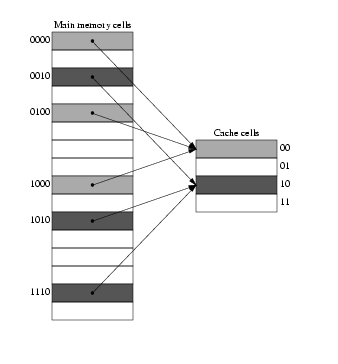
The figure shows 16 RAM cells mapped to 4 cells of cache memory. The mapping is done as per the equation:
Address of cache cell = (Address of RAM cell) modulus (total number of cache cells)
We note that RAM locations 0, 4, 8, 12 are all mapped to location 0 in cache. When the CPU first fetches data from memory location 0, a copy of it is stored in the cache. If the same memory location is to be read again, the read will be satisfied from the cache. But the question is, how does the CPU know that the data in cache cell 0 corresponds to data in RAM cell 0 - it can as well correspond to data in RAM cells 4, 8 or 12. The solution is simple - together with the data, each cache cell also maintains a tag which uniquely identifies the corresponding location in main memory. In the above example, we note that main memory can be addressed using 4 bits and cache, using two bits. If we examine the main memory addresses 0, 4, 8 and 12 (0000, 0100, 1000, 1100 in binary) we see that the lower two bits of all the addresses are 00 - all these addresses are mapped to cache location 00. We use as `tag', the higher two bits of the main memory address. Thus, if cache cell 0 contains data corresponding to main memory location 4, its tag bits would contain 01.
What is temporal and spatial locality of reference?
The cache is effective because it exploits `temporal and spatial locality of reference'. Data which was accessed a moment back might be accessed again and again (temporal locality); a typical example is instructions in a loop. The instructions are stored in memory - and the same instructions are executed over and over. When we step through an array, we normally do it in sequence - when we read one byte of the array, there is a high probability that the subsequent reads are going to be from adjacent locations. Designers of cache systems exploit this `spatial' locality of reference by loading not just the word being fetched from memory, but also a few consecutive words into cache. The next few accesses would be satisfied from the cache (a `cache hit') - provided they access consecutive locations.
How much cache memory does your system have?
It's easy to find this out. Here is a part of the output generated by running `dmesg' on my system:
CPU: L1 I Cache: 64K (64 bytes/line), D cache 64K (64 bytes/line) CPU: L2 Cache: 256K (64 bytes/line)
How do you write a program which reveals the presence of the cache?
Let's write a program which creates a really big array and simply reads all the elements in it in sequence.
The array-reading part of the program takes about one second to complete on my Athlon XP system with a clock speed of 1463 MHz; the system has 256Mb of RAM and the program does not swap to disk.
Now we change the program a bit. Suppose we have a cache block of size M bytes. We think of main memory as being divided into blocks of size M bytes each. Reading the zero'th byte would result in bytes 0 to M-1 getting stored in a cache block. If the next M-1 accesses refer to locations 1 to M-1, then the references would be satisfied from the cache. But what if the next referenced element is the one at main memory address M? Because only elements 0 to M-1 are in the cache, we have a miss, and another M byte block gets loaded into the cache (the block from M to 2*M-1). If we keep on accessing this way (ie, 0, M, 2*M, 3*M etc), each access will result in a cache miss. If the array is fairly large compared to the cache size, we would very soon fill up the cache. Now, if we come back and try to read from locations 1, M+1, 2*M+1, 3*M+1 etc, these elements would no longer be in the cache as they have been replaced by elements present at the far right end of the array - and so we again have cache misses. The figure below shows this kind of access for M=4.
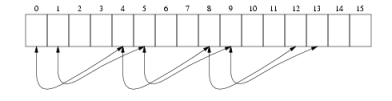
This makes up for very inefficient use of the cache - our program does not show enough `spatial locality of reference'. It would show up in the run time of the modified program - I measured it to be around 9 seconds on my system.
Using the performance counting registers
CPU's from Pentium onwards have special performance counting registers which can be used for counting architectural events like a cache hit/miss, TLB accesses etc. These registers can be accessed from kernel mode using the macro's `rdmsr' and `wrmsr'. The Athlon XP CPU has four such 64 bit counters located at 0xC0010004 to 0xC0010007. Each of these registers can monitor one architectural event at a time. The events to be monitored, whether monitoring is to be done for user mode events or kernel mode events etc are controlled by four `event select registers' located from 0xC0010000 to 0xC0010003 - there is one event select register for each event count register.
Let's say we wish to count the DCACHE misses. We will use the first performance counter at 0xC0010004, which is controlled by the event select register 0xC0010000. We have to write a 32 bit number to the event select register. Here is how the number is formed:
- Least significant 8 bits (D0 to D7) should be the `event number'. A DCACHE MISS is event number 0x41.
- If bit 16 is set, user mode events are counted. If bit 17 is set, kernel mode events are counted.
- Bit 22, when set, enables counting.
wrmsr(0xC0010000, 0x41 | (1U << 16) | (1U << 22), 0)After this, executing `rdmsr' on 0xC0010004 would yield the number of cache misses.
unsigned int low, high; rdmsr(0xC0010004, low, high);
[Listing 3] implements a simple character driver for reading/writing the performance count registers. A few macro definitions for use with this module are provided in [Listing 4].
Taking measurements
[Listing 5] is a simple program which reads DCACHE misses before and after calling two functions, one which which accesses an array in the normal manner - and another which reads the array by jumping across blocks. Only user space cache misses are counted. It should be noted that other programs running on the system also contribute to the count. Here is one set of outputs:
low = e023d3ef, high = ffff low = e047a944, high = ffff ----------------------- low = e938fae5, high = ffff
Further Reading
The book Computer Architecture - a Quantitative Approach by Patterson and Hennessy is the definitive reference for all the clever tricks which designers employ to push the limits of computing performance. The AMD Athlon Code Optimization Guide details the use of the performance counting registers and is available here. Similar documents are available for Intel CPUs also.
![[BIO]](../gx/2002/note.png) I am an instructor working for IC Software in Kerala, India. I would have loved
becoming an organic chemist, but I do the second best thing possible, which is
play with Linux and teach programming!
I am an instructor working for IC Software in Kerala, India. I would have loved
becoming an organic chemist, but I do the second best thing possible, which is
play with Linux and teach programming!
